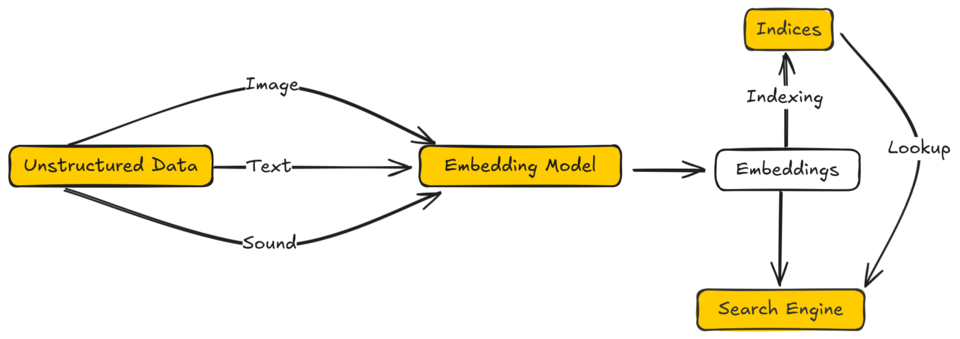
Redis 8.2 has moved vector search from an optional extension to a first-class data type. This is more relevant than it looks because it shifts the usual question: it is no longer whether Redis can hold embeddings, but whether it can replace a dedicated engine like Qdrant, Weaviate, Milvus or the pgvector extension on PostgreSQL. This post gathers what I learned running two RAG systems with Redis 8.2 in production over the summer and what still does not pay off to ask from it.
What changed since the RediSearch extension
Until Redis 7.x, vector search lived inside the RediSearch module, with a separate license and the curious habit of behaving differently depending on the exact module version you had loaded. In 8.0 the feature was integrated into the core under Redis’s own open license, and in 8.2 the API has been closed with HNSW index support, filtering on metadata, and per-query latency metrics. The important shift is that the vector layer is no longer a fragile add-on, it is part of the engine your team already knows.
The implementation keeps the Redis philosophy. Vectors are fields inside hash or JSON documents, the HNSW index is built in memory, and queries use the same RediSearch language already used for full-text search. This means a single query can combine boolean filters on tags with a KNN search over embeddings without crossing systems. In practice, for a simple RAG that filters by tenant and returns the five nearest documents, the query fits on one line.
Performance measured on small and medium workloads
The numbers published by Redis Labs are optimistic but not dishonest. In my tests with a corpus of 800,000 vectors at 768 dimensions on a machine with 32 GB of RAM, Redis 8.2 answered KNN queries with k=10 at a median of 4 to 6 ms, with a p99 below 20 ms. For the same corpus, pgvector with a tuned HNSW index returned in 15 to 30 ms and Qdrant sat in a range similar to Redis. The gap is consistent but moderate, not an order of magnitude.
Where Redis wins clearly is when the application already depends on Redis for cache, sessions, or queues. Avoiding an additional system has real operational value: fewer backups, less monitoring, fewer permissions, fewer pipes that can break. In small teams this consolidation pays off even if the dedicated engine is 20% faster on paper.
Where a dedicated engine still wins
Past a few million vectors the story changes. Redis’s HNSW index lives entirely in memory, and although the underlying library is efficient, a table of 50 million vectors at 768 dimensions needs roughly 150 GB of RAM just for the index. Qdrant and Milvus support disk-persisted indices with a hot cache layer, which lets them serve large corpora on reasonable hardware. pgvector on PostgreSQL 17 supports HNSW on persistent storage since 2024, and that changes the economic calculation for large corpora even if latency is higher.
The second area where a dedicated engine wins is advanced filtering. Redis supports boolean filters on tags and numeric ranges, but Qdrant and Weaviate offer geospatial filters, rich payloads, and adaptive pre-selection strategies that matter when filter cardinality is high. In a real multi-tenant multilingual search case with 200 tenants, I watched Qdrant keep latencies stable where Redis started degrading because the planner had less information about filter selectivity.
The piece people often forget: ingestion
Talking about search is only half the work. The other half is inserting vectors and keeping them fresh. Redis has the advantage of in-memory writes with very low latency, which makes HNSW index construction fast while the corpus fits in RAM. In my tests, inserting 100,000 vectors at 1024 dimensions took 18 seconds on one fully loaded thread. For small corpora rebuilt daily, this is enough.
The downside is that HNSW does not handle mass deletions well. Removing 10% of the corpus leaves the graph fragmented and hurts recall quality. Redis does not yet expose an incremental rebuild operation, so the pattern I ended up using is rebuilding the full index nightly if the weekly deletion rate exceeds 5%. Dedicated engines like Qdrant offer asynchronous compaction that avoids this gymnastics, and for document streams with high turnover this makes the difference.
Coherence with the rest of Redis
The detail that makes Redis 8.2 interesting for many cases is not so much raw performance as operational coherence with the rest of the system. If the team already handles replication, backups with RDB and AOF, failover with Sentinel or Cluster, and eviction policies, that experience applies directly to vector indices. There is no new system to learn and no different consistency model to explain to the on-call rotation.
This value grows the smaller the team. In an organization with two people running infrastructure, adding Qdrant or Weaviate means a new binary, a new management protocol, a new backup pattern, and new alerts. Redis 8.2 reuses 80% of what already works. For a fifteen-person team with a dedicated SRE, this advantage thins out.
How to decide in 2025
My practical rule after these months is simple. If the vector corpus fits in RAM of a reasonable machine, if the application already uses Redis, and if the filters are basic, Redis 8.2 is the default choice. The operational saving outweighs any specific advantage of a dedicated engine. If the corpus exceeds 10 million vectors, if filters are complex, or if there are very large retention requirements with rare access, a dedicated engine offers a better cost-performance ratio.
There is a middle zone, between 1 and 10 million vectors, where the decision depends heavily on the query pattern. If queries are highly concurrent and latency-sensitive, Redis wins. If they are sparse but hit large and rotating corpora, Qdrant or pgvector win. In that zone it pays to measure with your own corpus before committing.
My take
Redis 8.2 closes a gap that Redis had been carrying since 2022. The gap was not technical but one of positioning: it was perceived as a fast cache sitting next to a serious database, and vector search confirmed that image. With the native index and the open license, Redis starts competing seriously with pgvector in the medium corpus range, and that is a category shift for the platform.
I do not think Redis replaces dedicated engines in the high segment. Qdrant, Milvus, and Weaviate remain better when serving hundreds of millions of vectors with complex filtering. But for most RAG applications I see in mid-sized companies, where the corpus is a few million and filter complexity is low, Redis 8.2 is a sober and sufficient option.
What I like most about the change is that it simplifies architecture. Every extra system in production has hidden cost in staff, monitoring, and security. If your case fits, using Redis for both cache and embeddings is one of those decisions that reduces complexity without losing capability. And that, in 2025 with infrastructure teams as stretched as they are, is worth far more than a 20% latency edge.