Alignment evaluation: RLHF, DPO, and recent alternatives
Actualizado: 2026-05-03
When OpenAI described RLHF as the technique behind InstructGPT in 2022, the landscape of language-model alignment seemed conceptually solved. RLHF was expensive but worked, and for a time it was the default for any serious fine-tuning with human preferences. Three years later, that monopoly has faded: DPO showed you could achieve similar results with much less effort, and since then variants (KTO, ORPO, SimPO) promise to simplify things further.
This post is a practical review of the current state: when each method makes sense, what it costs, what results it produces in real contexts, and what criteria to use for choosing. Not a theoretical intro, but applied reading for those building an alignment pipeline.
Key takeaways
- DPO is the default for most standard alignment cases today: simpler, faster, works well with modest datasets.
- RLHF is reserved for cases where the last percentage points matter a lot, or where a reusable reward model for continuous evaluation is needed.
- KTO fits when data comes in binary format (good/bad responses without explicit pairs).
- ORPO simplifies the pipeline by merging SFT and alignment into one step.
- The barrier to aligning an open model has collapsed: what in 2022 was a research-lab project is today weekend fine-tuning with a moderate GPU budget.
The problem they all solve
The common goal is the same: start from a pre-trained and instruction-tuned model, and adjust it to respond according to preferences. Preferences can be “answer helpfully,” “don’t produce harmful content,” “adopt this style,” “prioritize brevity.”
All methods start from the same input: pairs of responses labeled “better” and “worse” according to some criterion. What changes is how that dataset is used to update the model’s weights.
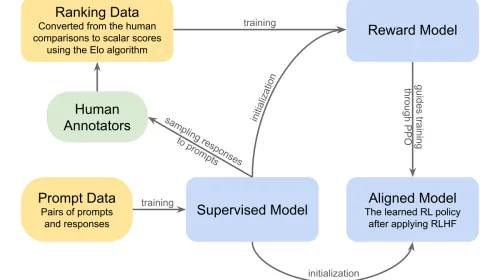
RLHF: the classic
RLHF first trains a reward model predicting how much a human will like a given response. Then uses reinforcement learning (typically PPO) to optimize the language model by maximizing that reward, with KL divergence constraints to prevent drifting too far from the base model.
Pros: most studied method, produces high-quality results, reward model can evaluate new responses outside training.
Cons: computationally expensive (three active models during training: policy, reference, reward), unstable (hyperparameter tuning is notoriously hard), requires a large, high-quality preference dataset.
When to use: when you have resources, want a reusable reward model for offline evaluation, or the alignment criterion is complex.
DPO: the simplification
DPO (Direct Preference Optimization) arrived in 2023 with a simple idea: reformulate the RLHF problem such that the implicit reward model is the language model itself, then train directly against preference pairs without PPO.
In practice, DPO works surprisingly well. Result quality is very close to RLHF on most benchmarks, and training cost is a fraction. This has made DPO the most common method in the open community today.
Pros: much simpler to implement, much faster to train, less sensitive to hyperparameters, works well with smaller datasets.
Cons: doesn’t produce a reusable reward model, slightly worse than well-tuned RLHF on very complex tasks, tends to produce longer responses (a well-documented bias).
When to use: for most standard alignment cases, especially in open-source environments with moderate resources.
Recent variants
Several DPO alternatives appeared over the last year:
- KTO (Kahneman-Tversky Optimization): uses individually labeled desirable/undesirable responses instead of preference pairs. Datasets are easier to build.
- ORPO (Odds Ratio Preference Optimization): fuses SFT and alignment into one step, eliminating the prior SFT phase.
- SimPO (Simple Preference Optimization): uses sequence-length normalization as reference, eliminating the reference model. Reduces memory cost. Promising results but modest community adoption.
What happens in practice
For standard alignment of a mid-sized model (7B to 70B) with a reasonable human-preference dataset, DPO is the default and there’s no strong reason to change. KTO gets adopted when the dataset is naturally binary. ORPO gets tried when simplifying the pipeline is the goal. SimPO shows up more in papers than production. RLHF is reserved for frontier models or complex multimodal alignment criteria.
Concrete recommendations
- Start with DPO. It has the most documentation, tutorials, and public implementations. Any decent framework (HuggingFace’s TRL, Axolotl, Unsloth) gets you to a working pipeline in a day.
- Use a preference dataset of at least a few thousand examples. If you have fewer, KTO can be more efficient because binary labeling is cheaper.
- Evaluate with a held-out validation set, using automated metrics (ROUGE, BLEU) and random human evaluation.
- Only move to RLHF if, after trying DPO, you have concrete evidence of quality shortfall. In most projects that evidence doesn’t show up.
- Try a recent variant (KTO, ORPO) if your dataset or pipeline fits its premises better.
My read
The barrier to effectively aligning an open model has crashed. What in 2022 was a research-lab project is today weekend fine-tuning with a moderate GPU budget. That doesn’t mean the problem is conceptually solved (important open questions about safe frontier-model alignment remain), but the routine practice of adjusting a model to your style or task is now accessible to any technical team.
The existence of new variants every few months signals the space is alive. The general trend — toward less complexity and more accessibility — is clearly good for the ecosystem.




