DINOv2: Advances in Self-Supervised Computer Vision
DINOv2 de Meta AI entrena modelos de visión por computadora sin etiquetas humanas, con resultados que superan a modelos supervisados en tareas de clasificación, segmentación y profundidad.
Tag
DINOv2 de Meta AI entrena modelos de visión por computadora sin etiquetas humanas, con resultados que superan a modelos supervisados en tareas de clasificación, segmentación y profundidad.
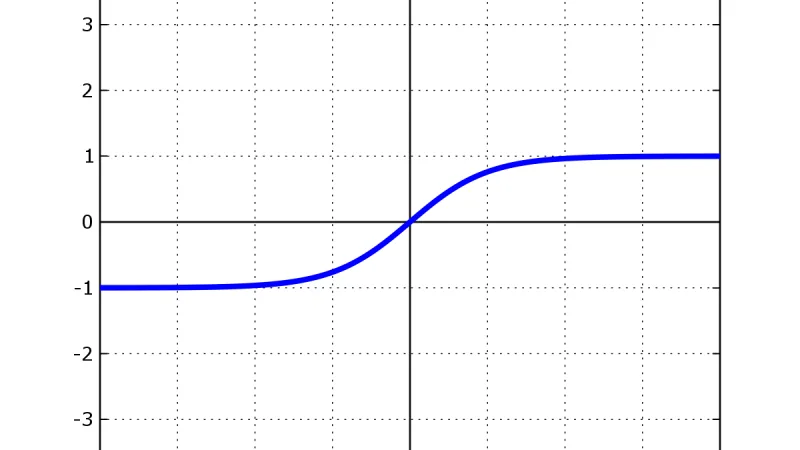
La tangente hiperbólica (tanh) produce salidas simétricas entre -1 y 1, lo que la convierte en una función de activación más estable que la sigmoide para capas ocultas.
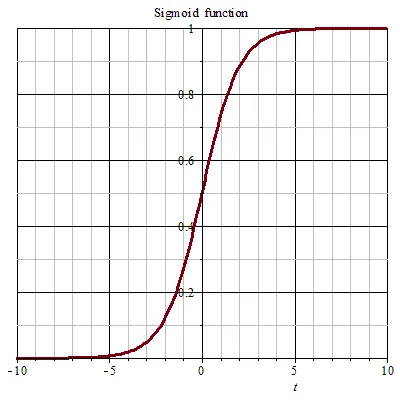
La función sigmoide comprime cualquier valor de entrada en el rango (0, 1), lo que la convierte en la función de activación natural para modelar probabilidades en redes neuronales.
La función Softmax convierte vectores de salida de una red neuronal en distribuciones de probabilidad. Es el estándar para clasificación multiclase y el fundamento matemático de los modelos de lenguaje.
Leaky ReLU resuelve el problema de la neurona muerta de ReLU estándar al permitir un gradiente pequeño en la región negativa, mejorando el entrenamiento en redes profundas.
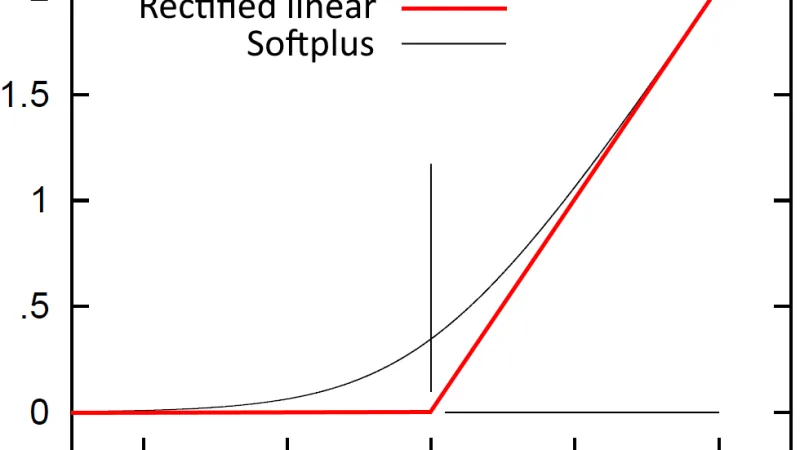
ReLU es la función de activación más utilizada en redes neuronales profundas: simple, eficiente y resistente al desvanecimiento del gradiente que lastra a la sigmoide.
La función escalón o de Heaviside es la función de activación más simple de una red neuronal: convierte cualquier entrada en una salida binaria 0 o 1.
La función lineal es la función de activación más simple en redes neuronales. Útil para regresión, pero con limitaciones críticas para capas ocultas: no introduce no linealidad.
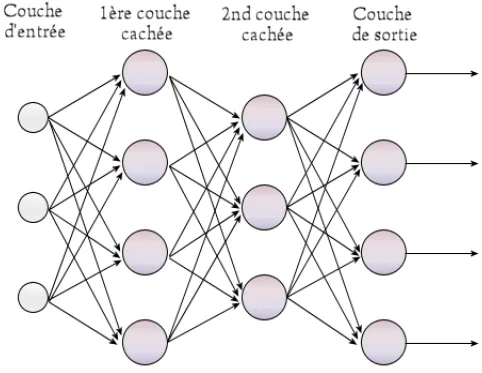
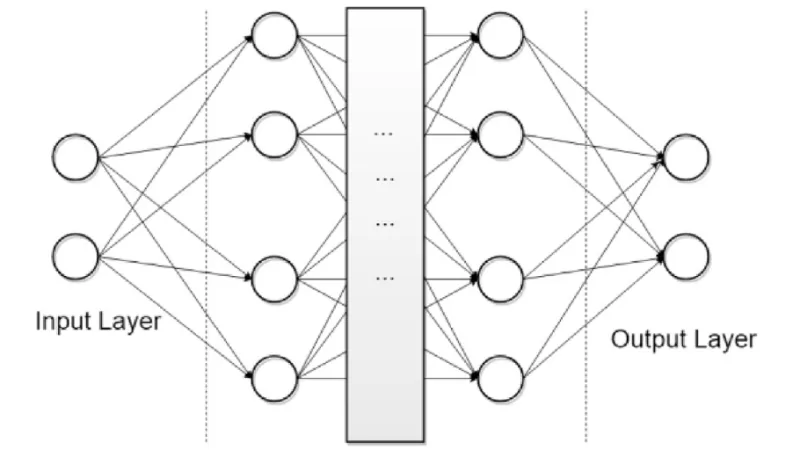
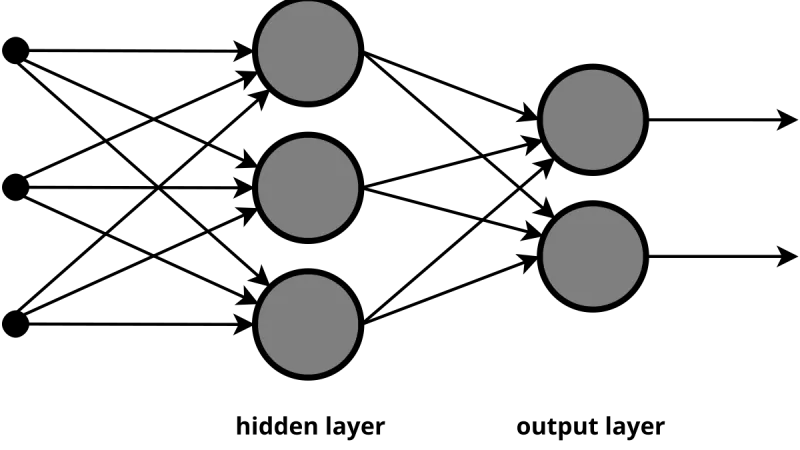
La red neuronal totalmente conectada o densa es el bloque fundamental del aprendizaje profundo: cada neurona se conecta con todas las de la capa anterior y posterior.
Cómo se representan matemáticamente las entradas, pesos y funciones de activación en una red neuronal artificial, y cómo el algoritmo de retropropagación ajusta esos pesos durante el entrenamiento.
Cómo funcionan las redes neuronales multicapa, qué las hace tan poderosas y por qué el deep learning depende de ellas para resolver problemas complejos.
La transferencia de aprendizaje permite reutilizar modelos entrenados en grandes conjuntos de datos para resolver tareas nuevas con mucho menos datos y tiempo de cómputo. Cómo funciona y cuándo usarla.