Event-Driven Architecture: When and How to Adopt It
Actualizado: 2026-05-03
Event-Driven Architecture (EDA) is one of the most promoted patterns in modern distributed systems. The idea: instead of services calling each other directly, services publish events when something changes, and other services subscribe to relevant events. Coupling reduces, resilience improves, and new pieces plug in without touching existing ones.
Reality is more nuanced. This article covers when EDA adds real value, which patterns consolidate, and which new problems it introduces — the ones most often underestimated.
Key takeaways
- EDA shines with multiple consumers of the same event, naturally asynchronous processing, and domains reactive to continuous changes.
- It doesn’t pay off in linear workflows with few steps or when immediate user response is needed.
- The outbox pattern and a schema registry aren’t optional — they’re the difference between a robust system and a fragile one.
- Debugging without distributed tracing from day one is a trap that’s expensive to fix later.
- Gradual adoption: start with an obvious case using a single producer and a single consumer.
The Paradigm Shift
In classic synchronous REST architecture:
ServiceA → POST /orders → ServiceB
ServiceA waits for response
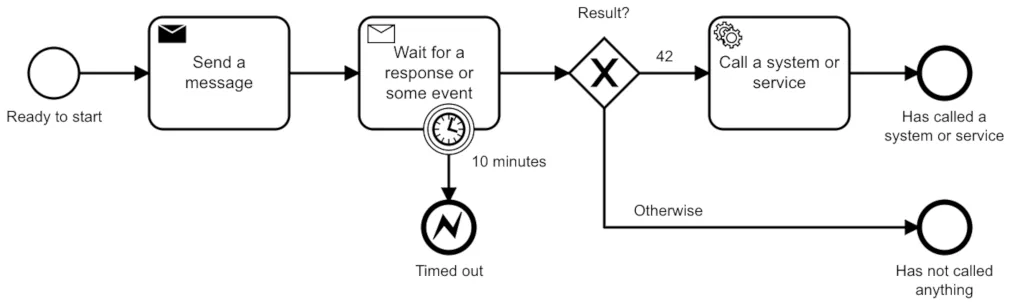
ServiceA does something with the responseIn event-driven architecture:
ServiceA publishes "OrderCreated" event on the broker
ServiceB receives the event, processes
ServiceC also receives it, does its thing
ServiceA neither waits nor knows who consumesThe difference is deep: ServiceA no longer knows about B or C. Tomorrow ServiceD can start consuming the same events without changing anything in ServiceA. That’s real decoupling.
When It Adds Value
EDA shines in five concrete scenarios:
- Multiple consumers of the same event. A purchase order triggers: inventory update, email send, analytics record, fraud check. Each separately, without coupling.
- Naturally asynchronous processing. The user makes a request; the result takes minutes to compute. You accept the request, generate an event, and the client polls for result later.
- Domain reacting to external changes. IoT, financial markets, online games — things happen continuously and you must react.
- Intrinsic audit trail. If you save all events, you have the complete history of what happened and when, without designing it separately.
- Autonomous teams with clear boundaries. Each team owns its events; others consume without asking permission.
When It Doesn’t Pay Off
EDA is often applied by default when something simpler would work better:
- Linear workflow with few steps. If A → B → C → D and nobody else benefits, a synchronous call or traditional orchestration is simpler and easier to reason about.
- Need immediate user response. EDA is naturally asynchronous; if your UI waits for result, you return to a request-response pattern over the broker — with added complexity.
- Small team and early product. Operating complexity (broker, schemas, monitoring) doesn’t amortise.
- Strong consistency guarantees. EDA is eventually consistent. If you need strong transactional consistency, the pattern adds significant friction.
Main Brokers
The brokers most seen in production in 2023:
- Apache Kafka[1]: king in high throughput and long persistence (days or weeks of retention). Distributed log model. Complex to operate but well understood. See the dedicated article at kafka-streaming-eventos.
- RabbitMQ[2]: simpler, focus on flexible routing (exchanges, queues), excellent for traditional queues.
- NATS[3]: very lightweight, high performance, suitable for microservices and edge. Persistent streams via JetStream.
- AWS SNS/SQS, Google Pub/Sub, Azure Service Bus: managed options per your cloud.
- Redis Streams: if you already use Redis, simple option for moderate volumes.
For almost any serious new project expecting scale, Kafka is the default. Choice among the others depends on expected throughput, required retention, and preference for managed vs self-host.
Patterns That Matter
Four patterns that appear in any serious EDA project:
Event Sourcing
Instead of storing current entity state, you store the full sequence of events that modified them. Current state is rebuilt by replaying events. Allows perfect auditing and “time travel”, but complicates queries and schema migration.
CQRS (Command Query Responsibility Segregation)
You separate the write model (commands) from the read model (queries). After a command, read models update asynchronously via events. You optimise each side independently. Often appears alongside Event Sourcing, but they’re orthogonal — you can do CQRS without event sourcing and vice versa.
Saga
For distributed transactions crossing multiple services without XA/2PC. The saga is a sequence of steps where each step publishes an event; if a step fails, compensating actions execute that reverse previous ones.
Two variants: choreography (each service reacts to events without coordinator) and orchestration (a central orchestrator guides the saga). Choreography is more decoupled; orchestration is easier to reason about.
Outbox Pattern
To guarantee atomicity between writing to your DB and publishing an event. You write the event to an outbox table in the same transaction as the state change. A separate process reads from outbox and publishes to the broker. This solves the “I published but the DB failed” problem — without it, your system has a fundamental race condition.
Problems EDA Introduces
Honestly: EDA isn’t just upsides. Six real problems that appear:
- Difficult debugging. A user request triggers a cascade of events through N services. Without serious distributed tracing, debugging is a nightmare.
- Eventual consistency. The user makes an action and “sees” the result seconds or minutes later. UX and communication must reflect this.
- Schema management. Evolving events, consumers with different versions, backward compatibility. Without discipline (Avro, Protobuf, JSON Schema in a schema registry), it all breaks.
- Event duplication. Brokers offer “at least once”, not “exactly once”. Your consumers must be idempotent.
- Broker operations. A Kafka cluster is a serious system: backups, monitoring, capacity planning — all new work.
- Cognitive cost. The way to reason is different. Longer onboarding for new developers.
How to Start Gradually
Gradual adoption reduces risk:
- Identify an obvious case where multiple systems react to the same event (purchase order, user registration, audit event).
- Start with a simple broker (RabbitMQ, NATS) if volumes allow. Kafka if you expect scale from the start.
- A single producer, a single consumer initially. Add more when the pattern is tamed.
- Schema registry from the first event — don’t improvise with JSON without contract.
- Distributed tracing from day one. Without it, debugging will be unbearable later.
Conclusion
Event-driven architecture is a powerful tool for concrete problems: service decoupling, multiple consumers, naturally asynchronous processing. But it’s not a free upgrade — it introduces new operational, cognitive, and consistency problems worth recognising before adopting. Applied with judgment in the right places, it improves architectures. Applied dogmatically, it complicates them unnecessarily.



