Model Context Protocol: Anthropic’s Open Proposal
Actualizado: 2026-05-03
Anthropic published Model Context Protocol (MCP) on 25 November 2024, an open standard for connecting language models to data sources and external tools. On first read it may look like yet another spec in an already crowded ecosystem of LLM-adjacent pieces, but it deserves a closer look. What Anthropic is proposing is not a framework, not a library: it is an interoperability protocol, designed so that any client (Claude Desktop, an IDE, a custom agent) can talk to any server that exposes data or actions. In short, MCP aims to be for context what Language Server Protocol is for code editors.
Key takeaways
- MCP standardises the boundary between LLMs and external tools with a JSON-RPC 2.0-based protocol.
- Servers expose three primitives: resources, tools and prompts; clients discover them through introspection.
- It does not replace function calling — it complements it by standardising the server side.
- Official SDKs in Python and TypeScript shipped at launch.
- The real value is interoperability: one MCP server works with any client that speaks the protocol.
The real problem it tries to solve
Anyone who has integrated an LLM into a serious application recognises the pattern. Connecting the model to an internal database, a corporate wiki, Slack, a Git repository or a ticketing system means writing a bespoke adapter every single time. The code that parses results, injects context into the prompt, exposes callable functions and handles errors ends up being duplicated across projects and across providers. Connecting Claude to a database needs a bridge. Connecting GPT-4 to the same database needs a different one. And every time the model, schema or function format changes, the glue breaks.
That friction is not accidental: it is the visible symptom of an integration layer that has never been standardised. If the server exposing the database speaks MCP and the client hosting the model also speaks MCP, integration stops being a project and becomes a configuration.
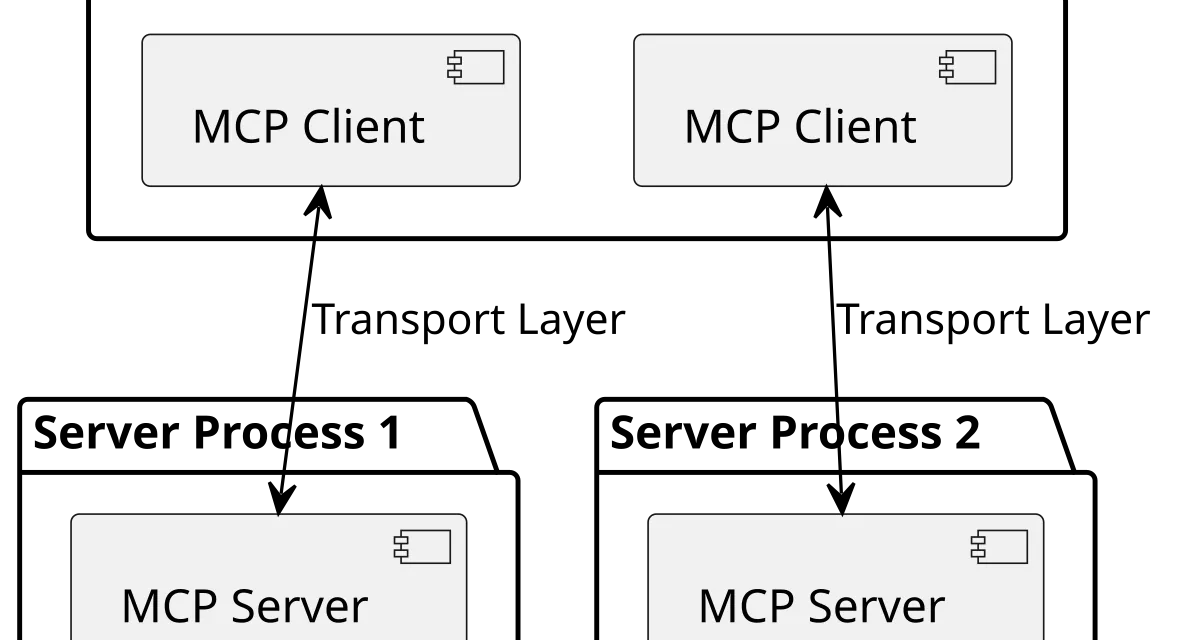
One-sentence architecture
MCP defines two roles. Servers expose three primitives:
- Resources: readable data identified by URI.
- Tools: actions invoked with parameters.
- Prompts: reusable templates.
Clients — the applications that host the model — discover those primitives through introspection, present them to the LLM and execute whatever calls the model decides to make. Communication travels over JSON-RPC 2.0 and can be transported via stdio (local subprocess), SSE over HTTP (remote) or WebSocket (bidirectional real time). The client knows nothing about the server’s domain: it learns what is available by asking at startup.
A minimal Python example
The official SDK ships a facade called FastMCP that collapses a server implementation down to a handful of lines:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("demo")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two integers."""
return a + b
@mcp.resource("config://app")
def get_config() -> str:
"""Return the active configuration."""
return "production"
mcp.run()The rest of the integration is declarative. Inside claude_desktop_config.json the server is registered with the command and arguments needed to launch it, Claude Desktop spawns it as a subprocess over stdio on startup, discovers the exposed primitives and makes them available to the model in every conversation.
How it differs from function calling
Function calling, as implemented by OpenAI, Anthropic and the rest of the providers in their APIs, is a model feature: the LLM emits a structured response representing a function call and the application decides how to execute it. It is a contract between the model and the application developer, but it says nothing about who exposes those functions or how they are discovered.
MCP operates one level up. It does not replace function calling, it complements it by standardising the server side. When an MCP client starts, it discovers the tools that a server offers, translates them into whichever function-calling format the model expects and routes invocations back to the server when the LLM decides to call one. The model keeps doing function calling as before; what changes is that tools are no longer coupled to the client’s codebase.
The difference with frameworks such as LangChain or LlamaIndex is of the same kind. Those frameworks define tools inside the application process; MCP pulls them out, turns them into services with their own lifecycle and lets multiple clients share them. They are not competitors: an agent built with LangChain can quite happily consume MCP servers as one more source of tools.
Why it matters as a standard
The value of MCP is not in solving a technically new problem. It lies in standardising the right boundary. When an integration standard appears, ecosystems reorganise:
- Teams that used to duplicate integrations reinvest that effort into improving a single server everyone can use.
- Clients stop competing on how many tools they support and start competing on the quality of the experience.
- Service authors (a CRM, a document manager, a monitoring platform) can expose their product to LLMs without betting on a specific provider.
For agents, the implications go deeper. A useful agent needs a broad, evolving and auditable set of capabilities. With MCP, an agent can connect to a brand-new server without being rebuilt, and the operator can add, remove or update servers without touching the agent. It is the same pattern that let modern IDEs support dozens of languages without shipping a native parser for each one.
What still needs to mature
The protocol launches with the usual first-week limits of any standard:
- Authentication and authorisation are defined at the level of responsibility but not of schema; both are left to each server.
- Prompt injection through resources or tool responses is a real attack surface that servers have to mitigate on their own.
- Large-scale deployment patterns (versioning, dynamic discovery, fine-grained permissions) are still open questions.
- Support from clients other than Claude Desktop is, at launch, non-existent.
None of that is unusual. LSP went through an equivalent phase before VS Code turned it into a de-facto standard, and OpenAPI took years to become the lingua franca of REST APIs. What is interesting about MCP is that Anthropic published the specification, the SDKs (Python and TypeScript) and an initial batch of official servers all at once, which lowers the cost of adopting the protocol to something smaller than writing the next bespoke integration.
Conclusion
MCP may become the dominant standard for the tooling layer around language models. The value of MCP, even if the name eventually changes, is that it makes clear where the boundary ought to live and what it should look like. What is not sustainable is the status quo: every product team rewriting the same adapter so that the same LLM can read the same kind of source. That friction is too large to survive once an alternative exists with working SDKs and a public specification.



