Ensemble Learning in Machine Learning
Actualizado: 2026-05-03
Ensemble methods are the reason why winning Kaggle models almost always combine multiple predictors rather than using a single one. The intuition is simple: if one model makes errors on certain patterns, another model can compensate — as long as the errors are not correlated.
Key takeaways
- An ensemble combines the predictions of multiple models to obtain a more accurate and stable result than any individual model.
- The three main paradigms are bagging (parallel training on subsamples), boosting (sequential training correcting errors), and stacking (a metamodel learns to combine base predictors).
- Random Forest (bagging of trees) and XGBoost/LightGBM (tree boosting) dominate the state of the art on tabular data.
- Diversity between models is the necessary condition for the ensemble to outperform its components.
- The main cost is interpretability: an ensemble is always harder to explain than a single decision tree.
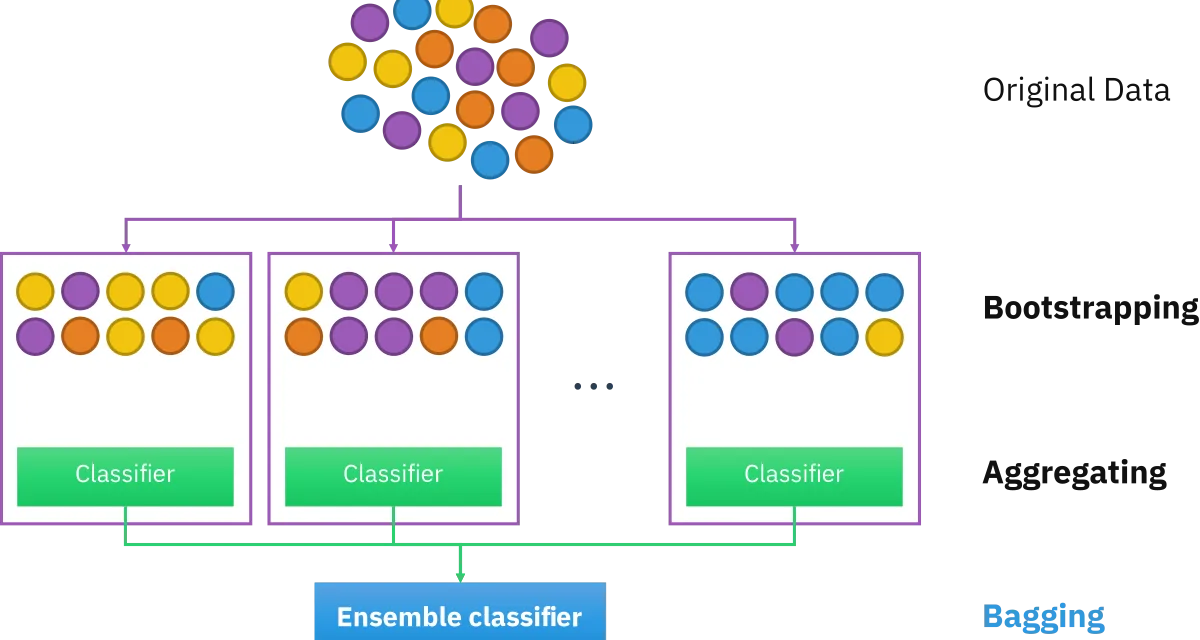
Bagging: Parallel Training on Subsamples
Bootstrap Aggregating (bagging) generates multiple training set versions via sampling with replacement (bootstrap), trains an independent model on each subsample, and combines predictions — by majority vote for classification, by averaging for regression.

The key to bagging is that the ensemble’s variance is lower than each individual model’s, as long as models have decorrelated errors.
Random Forest is the canonical implementation: a forest of decision trees, each trained on a dataset bootstrap with a random subset of features available at each split. The double level of randomness (data and features) maximises diversity between trees.
Boosting: Sequential Error Learning
Boosting trains models sequentially, where each new model focuses on examples the previous ones misclassified. The final ensemble is a weighted sum of all models.
XGBoost, LightGBM, and CatBoost are the most used implementations. In machine learning competitions with tabular data, gradient boosting models consistently dominate.
Stacking: A Metamodel over Base Predictors
Stacking takes the idea further: instead of combining models with fixed rules, it trains a metamodel that learns to optimally combine base model predictions.
Model Diversity: The Necessary Condition
Sources of diversity in ensembles:
- Algorithm diversity: combining models with different inductive biases (trees, neural networks, linear regression, SVM).
- Data diversity: bagging and variants (pasting, random patches, random subspaces).
- Hyperparameter diversity: same algorithms with different configurations.
- Feature diversity: models trained on different variable subsets.
Interpretability: The Ensemble Cost
A single decision tree is fully interpretable. An ensemble of 500 trees is not. Techniques that alleviate the problem:
- Feature importance from Random Forest or XGBoost.
- SHAP values: decompose each individual example’s prediction into per-feature contributions.
- Partial Dependence Plots (PDP): show a feature’s marginal effect on the prediction, averaged over the dataset.
See AI explanation through XAI for the broader context of interpretability in complex models.
Conclusion
Ensemble methods are the most mature and proven technology in classical machine learning for tabular data. Bagging reduces variance, boosting reduces bias, and stacking combines the best of multiple approaches. The condition for them to work is diversity: models that fail differently complement each other; models that fail the same way only add noise.




