Ensamble de aprendizaje en ML
Actualizado: 2026-05-03
Los métodos de ensamble son la razón por la que los modelos ganadores de Kaggle casi siempre combinan múltiples predictores en lugar de usar uno solo. La intuición es simple: si un modelo comete errores en ciertos patrones, otro modelo puede compensarlos — siempre que los errores no estén correlacionados.
Puntos clave
- Un ensamble combina las predicciones de múltiples modelos para obtener un resultado más preciso y estable que cualquiera de los modelos individuales.
- Los tres paradigmas principales son bagging (entrenamiento paralelo sobre submuestras), boosting (entrenamiento secuencial corrigiendo errores) y stacking (un metamodelo aprende a combinar predictores base).
- Random Forest (bagging de árboles) y XGBoost/LightGBM (boosting de árboles) dominan el estado del arte en datos tabulares.
- La diversidad entre modelos es la condición necesaria para que el ensamble supere a sus componentes.
- El coste principal es interpretabilidad: un ensamble es siempre más difícil de explicar que un árbol de decisión único.
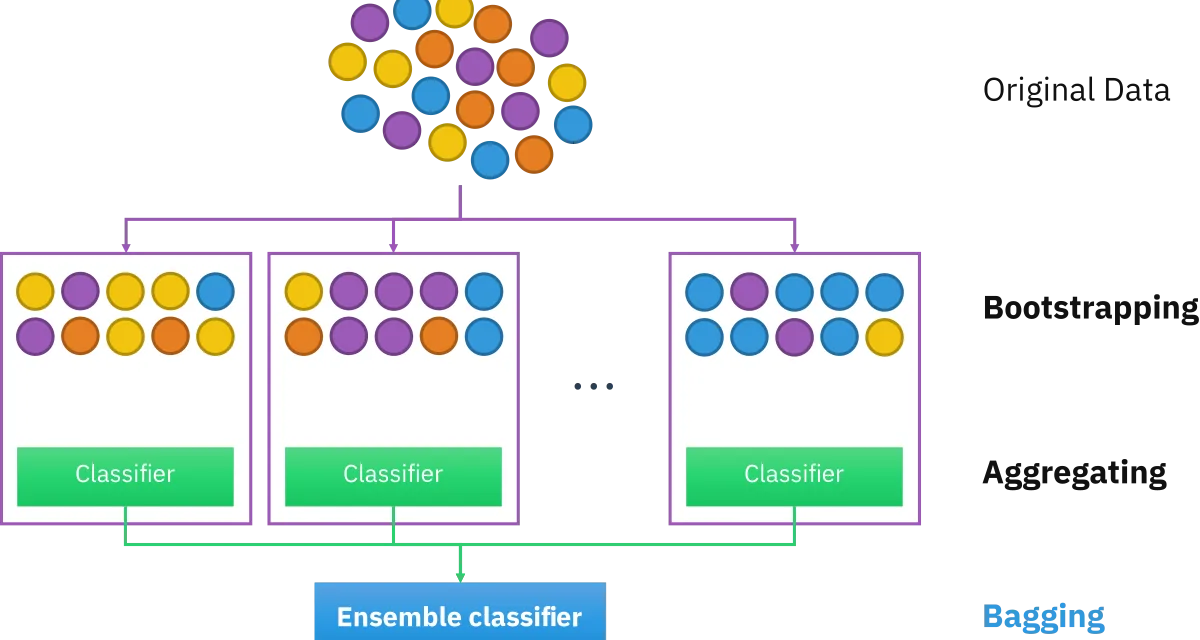
Bagging: entrenamiento paralelo sobre submuestras
Bootstrap Aggregating (bagging) genera múltiples versiones del conjunto de entrenamiento mediante muestreo con reemplazamiento (bootstrap), entrena un modelo independiente sobre cada submuestra y combina las predicciones — por votación mayoritaria en clasificación, por promedio en regresión.

La clave del bagging es que la varianza del ensamble es menor que la de cada modelo individual, siempre que los modelos tengan errores decorrelados. Cada modelo ve una perspectiva ligeramente distinta de los datos; el promedio cancela las idiosincrasias individuales.
Random Forest es la implementación canónica: un bosque de árboles de decisión, cada uno entrenado sobre un bootstrap del dataset y con un subconjunto aleatorio de features disponibles en cada split. El doble nivel de aleatoriedad (datos y features) maximiza la diversidad entre árboles.
Propiedades de Random Forest: – Robusto frente a overfitting en comparación con un árbol único profundo. – Proporciona importancia de variables como subproducto del entrenamiento. – Parallelizable trivialmente — cada árbol es independiente. – Rendimiento sólido con hiperparámetros por defecto.
Boosting: aprendizaje secuencial de errores
El boosting entrena los modelos de forma secuencial, donde cada nuevo modelo se concentra en los ejemplos que los anteriores clasificaron mal. El ensamble final es una suma ponderada de todos los modelos.
El proceso general:
- Entrenar un modelo débil (tipicamente un árbol poco profundo) sobre el dataset completo.
- Calcular el error residual: la diferencia entre la predicción y el valor real.
- Entrenar el siguiente modelo para predecir ese residual.
- Sumar el nuevo modelo al ensamble (con una tasa de aprendizaje que escala su contribución).
- Repetir hasta alcanzar el número definido de estimadores o hasta que el error de validación deje de mejorar.
XGBoost, LightGBM y CatBoost son las implementaciones más utilizadas. Sus diferencias principales están en la estrategia de construcción del árbol, el manejo de valores nulos y la eficiencia computacional — pero todos comparten el paradigma de gradient boosting.
En competiciones de machine learning con datos tabulares, los modelos de gradient boosting dominan consistentemente. Ver el poder del big data en la toma de decisiones para entender los contextos donde estos modelos aportan más valor.
Stacking: un metamodelo sobre predictores base
El stacking lleva la idea un paso más lejos: en lugar de combinar modelos con reglas fijas (votación, promedio), entrena un metamodelo que aprende a combinar las predicciones de los modelos base de forma óptima.
Proceso típico de stacking con k-fold:
- Dividir el dataset en k folds.
- Para cada fold: entrenar los modelos base en los k-1 folds restantes, predecir en el fold actual.
- Usar las predicciones out-of-fold de los modelos base como features del metamodelo.
- Entrenar el metamodelo sobre estas predicciones.
El metamodelo aprende qué modelos base son más fiables en qué tipos de ejemplos. Una combinación clásica para datos tabulares: Random Forest + XGBoost + regresión logística como base, con LightGBM como metamodelo.
Selección de modelos para el ensamble
La condición necesaria para que el ensamble supere a sus componentes es la diversidad. Si todos los modelos base cometen los mismos errores, promediarlos no ayuda.
Fuentes de diversidad:
- Diversidad de algoritmos: combinar modelos con sesgos inductivos distintos (árboles, redes neuronales, regresión lineal, SVM).
- Diversidad de datos: bagging y sus variantes (pasting, random patches, random subspaces).
- Diversidad de hiperparámetros: mismos algoritmos con configuraciones distintas.
- Diversidad de features: modelos entrenados sobre subconjuntos distintos de variables.
Para evaluar la diversidad, la matriz de correlación entre las predicciones de los modelos base es el indicador más directo: alta correlación indica poca diversidad adicional.
Evaluación y validación
Los métodos estándar de evaluación aplican al ensamble, pero hay que tener cuidado con una trampa frecuente:
Data leakage en stacking: si el metamodelo se entrena sobre predicciones in-sample de los modelos base (en lugar de out-of-fold), aprende patrones del overfitting y no de la generalización real. La validación cruzada anidada (nested cross-validation) es la forma correcta de evaluar la cadena completa.
Sobreoptimización del ensamble: añadir más modelos base no siempre mejora el rendimiento y siempre aumenta el coste computacional. El retorno marginal suele decrecer rápidamente.
La conexión con aprendizaje federado y privacidad es relevante: en escenarios donde los datos no pueden centralizarse, cada participante entrena su propio modelo y el servidor central puede usar técnicas de ensamble para combinar los modelos locales preservando la privacidad.
Interpretabilidad: el coste del ensamble
Un árbol de decisión único es completamente interpretable: se puede seguir el camino de cada predicción de la raíz a la hoja. Un ensamble de 500 árboles no lo es. Esta tensión entre rendimiento e interpretabilidad es fundamental en dominios de alto riesgo.
Técnicas que alivian el problema:
- Feature importance de Random Forest o XGBoost: indica qué variables contribuyen más al poder predictivo global.
- SHAP values: descomponen la predicción de cada ejemplo individual en contribuciones por feature. Es el estándar actual para explicabilidad de ensambles.
- Partial Dependence Plots (PDP): muestran el efecto marginal de una feature sobre la predicción, promediado sobre el dataset.
Ver la explicación de la IA a través de XAI para el contexto más amplio de interpretabilidad en modelos complejos.
Conclusión
Los métodos de ensamble son la tecnología más madura y probada del machine learning clásico para datos tabulares. Bagging reduce la varianza, boosting reduce el sesgo, y stacking combina lo mejor de múltiples enfoques. La condición para que funcionen es la diversidad: modelos que fallen de forma diferente se complementan; modelos que fallen de la misma forma solo suman ruido.




