Microsoft’s GraphRAG in enterprise: patterns that work
Actualizado: 2026-05-03
Microsoft released GraphRAG as an open project in early 2024 and since then it’s moved from academic curiosity to a tool with documented enterprise deployments. The core idea — using an LLM-built knowledge graph as an intermediate layer between documents and query — wasn’t new, but Microsoft was the first to offer a polished implementation and concrete benchmarks on question types where traditional RAG failed.
A year later, there’s enough material to evaluate where GraphRAG wins and where it isn’t worth the effort.
Key takeaways
- GraphRAG answers global questions about a corpus well (dominant topics, entity relationships, temporal evolution), where classic RAG fails because no individual chunk contains the answer.
- Indexing cost is real: for a medium corpus it can mean hundreds or thousands of dollars in API tokens.
- The most effective pattern is hybrid: classic RAG for local questions, GraphRAG for global ones.
- Incremental update is possible but more demanding than reindexing a classic RAG system.
- For constantly-changing corpora or simple local questions, GraphRAG doesn’t pay off.
The problem GraphRAG addresses
Classic RAG (text chunks, embeddings, similarity search, LLM) works very well for local questions: “what does document X say about topic Y?” It fails when the question requires aggregating information from many documents: “what are the main topics in this corpus?”, “how has the company’s stance on this topic evolved over the year?”
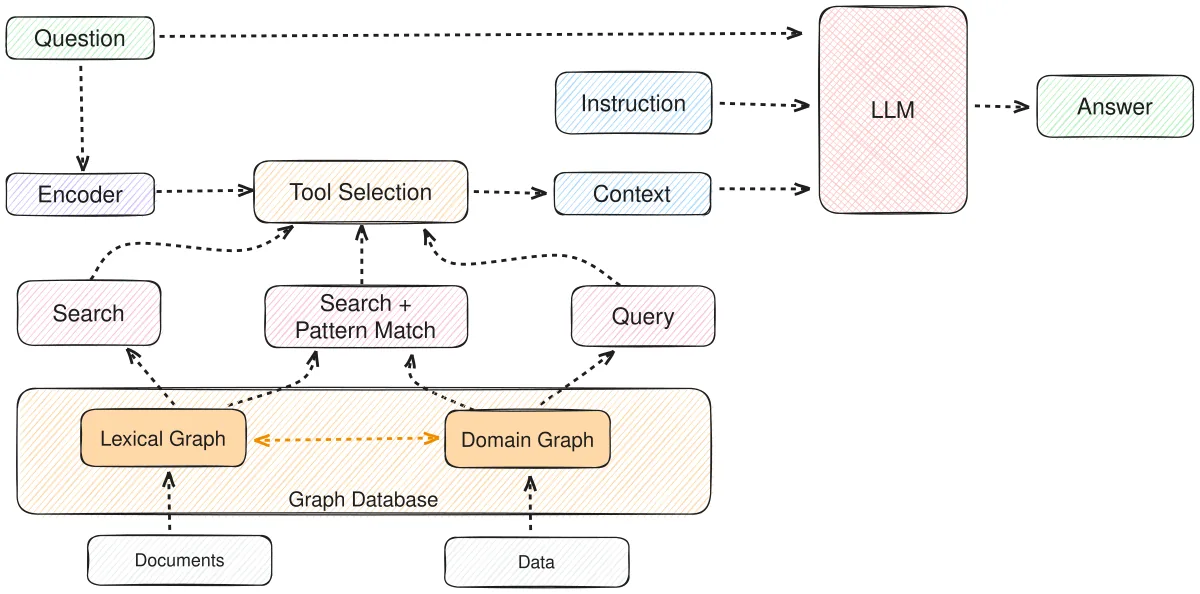
GraphRAG’s solution happens before query time. During indexing, an LLM reads the full corpus, extracts entities and their relationships, builds a graph, groups entities into communities, and generates a summary per community. When a global query arrives, GraphRAG retrieves community summaries instead of chunks.
Where it clearly wins
Medium-sized corpus analysis with strategic questions. Email archives, project documentation, meeting transcripts over a quarter: text bodies where the useful question isn’t “what exactly does X say?” but “what happened? what topics dominated? what changes are perceived?”
A paradigmatic case is customer feedback analysis. With thousands of support tickets, classic RAG answers “what’s the most recent issue of customer X?” well, but fails on “what are the three topics most worrying our customers this quarter?” GraphRAG, having built the graph during indexing, has that summary ready.
Another area where it shines: people or organization network analysis. Investigative journalism, corporate due diligence, pattern detection in complaints.
Where it doesn’t pay off
GraphRAG isn’t free:
- Indexing is expensive. Building the graph requires passing the full corpus through an LLM several times. For a medium corpus, indexing cost can climb to hundreds or thousands of dollars.
- Incremental update is possible but tricky. If the corpus changes constantly, keeping the graph in sync is non-trivial.
- For local questions, GraphRAG can be worse. Retrieving a summarized community when you want the literal chunk is an unnecessary detour.
That’s why the most effective pattern is hybrid: both systems in parallel, routing queries by type. Questions with concrete entities go to classic RAG; global thematic questions go to GraphRAG.
Patterns that have taken hold
- Reduce corpus scope. GraphRAG doesn’t scale well to giant corpora in a single indexing. Successful deployments index by domain.
- Use a powerful model for indexing, a cheap one for querying. Graph quality depends critically on the extraction model. Saving there is false economy.
- Keep classic RAG as fallback. For any query where GraphRAG doesn’t have a clearly relevant community, traditional search is cheap insurance.
- Invest in graph visualization. An interface letting users see what entities GraphRAG extracted brings a lot of confidence in results.
The decision
- Are useful questions local or global? If mostly local, classic RAG is enough. If mostly global, GraphRAG is very likely a good investment.
- Is the corpus stable or constantly changing? If it changes a lot, operational cost can exceed the benefit.
- Can you afford the indexing cost? For a 10,000-page corpus, indexing can cost between $200 and $2,000 depending on the model.
Looking ahead
Implementations will keep optimizing. Microsoft has released improvements reducing indexing cost 30 to 50 percent versus the initial version.
The hybrid pattern will become default. Serious 2026 RAG systems will likely combine several techniques: classic vector search, keyword search, knowledge graphs, and community-summary retrieval, all selected by query type. GraphRAG as we see it today is a step in that direction, not a final destination.
If your project has questions classic RAG doesn’t solve well, it’s worth spending two weeks on a prototype with a corpus subset. The results will tell you whether the bigger investment pays off.



