GraphRAG de Microsoft en empresa: patrones que funcionan

Actualizado: 2026-07-07
Microsoft publicó GraphRAG como proyecto abierto a principios de 2024 y desde entonces ha pasado de curiosidad académica a herramienta con despliegues empresariales documentados. La idea central —usar un grafo de conocimiento construido por el propio LLM como capa intermedia entre los documentos y la consulta— no era nueva, pero Microsoft fue el primero en ofrecer una implementación pulida y benchmarks concretos sobre tipos de pregunta donde el RAG tradicional fallaba.
Un año después, hay material suficiente para evaluar dónde GraphRAG gana y dónde no merece el esfuerzo.
Puntos clave
-
GraphRAG resuelve bien las preguntas globales sobre un corpus (temas dominantes, relaciones entre entidades, evolución temporal), donde el RAG clásico falla porque ningún chunk individual contiene la respuesta.
-
El coste de indexación es real: para un corpus mediano puede suponer cientos o miles de dólares en tokens de API.
-
El patrón más efectivo es híbrido: RAG clásico para preguntas locales, GraphRAG para preguntas globales.
-
La actualización incremental es posible pero más exigente que reindexar un RAG clásico.
-
Para corpus que cambian constantemente o preguntas locales simples, GraphRAG no compensa.
El problema que GraphRAG aborda
El RAG clásico (chunks de texto, embeddings, búsqueda por similitud, LLM) funciona muy bien para preguntas locales: «¿qué dice el documento X sobre el tema Y?». Falla cuando la pregunta requiere agregar información dispersa en múltiples documentos:
-
«¿Cuáles son los temas principales tratados en este corpus?»
-
«¿Qué relaciones hay entre los proyectos mencionados?»
-
«¿Cómo ha evolucionado la postura de la empresa sobre este tema a lo largo del año?»
Estas preguntas globales son frustrantes con RAG clásico porque ningún chunk individual contiene la respuesta. El modelo solo ve algunos fragmentos recuperados y tiene que adivinar el resto, con resultados erráticos.
La solución de GraphRAG es previa al momento de la consulta. Durante la indexación, un LLM:
-
Lee el corpus completo.
-
Extrae entidades (personas, proyectos, conceptos) y las relaciones entre ellas.
-
Construye un grafo.
-
Agrupa las entidades en comunidades (clústeres de nodos fuertemente conectados).
-
Para cada comunidad, genera un resumen que describe los temas y patrones que contiene.
Cuando llega una consulta global, en lugar de recuperar chunks, GraphRAG recupera resúmenes de comunidades y los combina para responder.
Dónde gana claramente
Análisis de corpus medianos con preguntas estratégicas. Archivos de correos de una empresa, documentación de proyectos, investigación acumulada, transcripciones de reuniones durante un trimestre: cuerpos de texto donde la pregunta útil no es «¿qué dice exactamente X?» sino «¿qué ha pasado? ¿qué temas han dominado? ¿qué cambios se perciben?»
Un caso paradigmático documentado es el análisis de feedback de clientes. Con miles de tickets de soporte o comentarios de encuestas, el RAG clásico responde bien a «¿cuál es el problema más reciente del cliente X?», pero falla en «¿cuáles son los tres temas que más preocupan a nuestros clientes este trimestre?». GraphRAG, al haber construido el grafo de temas durante la indexación, tiene ese resumen ya preparado.
Otro caso donde brilla: análisis de redes de personas u organizaciones. Investigación periodística, due diligence corporativa, detección de patrones en denuncias. Todo lo que implique entender quién está conectado con quién y cómo se beneficia enormemente del modelo de grafo explícito.
Para un análisis de cómo GraphRAG encaja en el conjunto más amplio de técnicas RAG, nuestro artículo sobre RAG en producción: patrones ofrece el contexto general. Y si te interesa cómo los grafos de conocimiento renacen en la era LLM, ver grafos de conocimiento y LLMs.
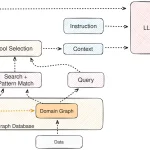
 Arquitectura de GraphRAG mostrando la extracción de grafo de conocimiento desde documentos
Arquitectura de GraphRAG mostrando la extracción de grafo de conocimiento desde documentos
Dónde no compensa
GraphRAG no es gratis:
-
La indexación es cara. Construir el grafo implica pasar el corpus completo por un LLM varias veces: extracción de entidades, extracción de relaciones, generación de resúmenes de comunidad. Para un corpus mediano (decenas de miles de páginas), el coste puede ascender a cientos o miles de dólares en tokens de API.
-
La actualización incremental es posible pero complicada. Si el corpus cambia constantemente, mantener el grafo sincronizado es no trivial.
-
Para preguntas locales, GraphRAG no mejora el resultado: a menudo lo empeora. Recuperar una comunidad resumida cuando quieres el chunk literal es un rodeo innecesario.
Por eso el patrón más efectivo es híbrido: tener los dos sistemas en paralelo y rutear las consultas según el tipo. Las preguntas con entidades concretas van al RAG clásico; las preguntas temáticas globales van al GraphRAG. Clasificar la pregunta con un LLM ligero al principio de cada consulta es suficiente para decidir.
Los patrones que han cuajado
Después de un año de despliegues, los patrones que se repiten entre equipos con éxito:
-
Reducir el ámbito del corpus. GraphRAG no escala bien a corpus gigantescos en una sola indexación. Los despliegues exitosos suelen indexar por dominio (un proyecto, una división, un año de datos) con varios grafos en paralelo.
-
Usar un modelo potente para la indexación, uno barato para la consulta. La calidad del grafo depende críticamente del modelo que extrae entidades y genera resúmenes. Ahorrar ahí es falso ahorro.
-
Mantener el RAG clásico como fallback. Para cualquier consulta donde GraphRAG no tenga una comunidad relevante clara, caer atrás a búsqueda tradicional es un seguro barato.
-
Invertir en la visualización del grafo. Tener una interfaz que permita al usuario ver qué entidades ha extraído GraphRAG y cómo las ha relacionado aporta mucha confianza en los resultados.
La decisión
El criterio práctico que uso:
-
¿Las preguntas útiles son locales o globales? Si son mayoritariamente locales, RAG clásico es suficiente. Si son mayoritariamente globales, GraphRAG es muy probablemente una buena inversión.
-
¿El corpus es estable o cambia constantemente? Si cambia mucho, el coste operativo puede superar el beneficio. Para corpus que se actualizan una vez por semana, GraphRAG va bien.
-
¿Puedes permitirte el coste de indexación inicial? Para un corpus de 10.000 páginas, la indexación puede costar entre 200 y 2.000 dólares según el modelo. Hay que hacer números.
Mirando adelante
Las implementaciones van a seguir optimizándose. El propio equipo de Microsoft Research ha ido publicando reducciones de coste sucesivas: la versión GraphRAG 1.0 recorta un 43% el espacio en disco total (un 80% solo en los parquet de salida) y baja el arranque de la interfaz de línea de comandos de 148 a 2 segundos, según su blog de investigación[1]. Más radical es LazyGraphRAG, la variante que evita el resumen previo de comunidades: Microsoft afirma que su coste de indexación iguala al de un RAG vectorial normal, un 0,1% del coste de un GraphRAG completo, con consultas globales hasta 700 veces más baratas que el Global Search original, según Microsoft Research[2]. Van a aparecer más alternativas ligeras que aplican la misma idea con menos ceremonia.
El patrón híbrido va a convertirse en el estándar. Los sistemas RAG serios de 2026 probablemente combinen varias técnicas: vector search clásico, búsqueda por palabras clave, grafos de conocimiento y recuperación por resúmenes de comunidad, todo seleccionado según el tipo de consulta. GraphRAG como lo vemos hoy es un paso en esa dirección, no un destino final.
Si tu proyecto tiene preguntas que el RAG clásico no resuelve bien, vale la pena dedicar dos semanas a un prototipo con un subconjunto del corpus. Los resultados te dirán si la inversión mayor compensa.
Lee también la versión en inglés: Microsoft’s GraphRAG in enterprise: patterns that work.


