Kubernetes 1.32: what the first jump of 2025 brings
Actualizado: 2026-05-03
Kubernetes 1.32, code name Penelope, shipped on December 11, 2024. Five months on, it’s been in production long enough to evaluate without relying solely on release notes. This post is a review from operations, not a full KEP list: I focus on what changes daily work for teams managing medium clusters and on adoption decisions worth revisiting with perspective.
Key takeaways
- Dynamic Resource Allocation (DRA) moves to v1beta1 with a redesigned API: only needed for clusters with GPUs or specialised hardware.
- Structured Authorization Configuration goes GA, closing the path to composing multiple authorisers in configurable order.
- Container-level sidecar metrics let you precisely separate proxy resource consumption from the application’s.
- Three deprecations created more work than expected: gitRepo volume plugin, FlowSchema v1beta3, and the unstructured authorisation variant.
- Configurable-per-endpoint AnonymousAuth reduces attack surface without breaking load-balancer probes.
Dynamic Resource Allocation at v1beta1
The most interesting 1.32 piece is the promotion of Dynamic Resource Allocation to v1beta1, with an API redesigned from the previous alpha. DRA is the project’s answer to managing resources that are neither CPU nor memory and carry shared or exclusive access semantics, like GPUs, specialised network adapters, or custom devices.
The new model builds on ResourceClaim and ResourceClaimTemplate, with an external driver publishing available devices and managing allocation. It’s much cleaner than the alpha, but still complex for teams coming from the simple requests-and-limits abstraction.
In practice, only clusters managing GPUs or specialised hardware need DRA. Those with normal workloads can ignore it at no cost. The DRA driver ecosystem is forming, with NVIDIA publishing theirs. Setting up DRA with the NVIDIA driver is doable but not trivial: it requires reviewing scheduler policies, driver permissions, and dedicated observability to catch failures the cluster doesn’t make explicit.
Structured Authorization stabilisation
Structured Authorization Configuration goes GA in 1.32, closing a road that began in alpha in 1.29. The change lets you compose multiple authorisers in configurable order from a single file, with capability to evaluate remote webhooks between internal steps.
The most immediate utility is for clusters combining RBAC with external policy like OPA Gatekeeper, Kyverno, or a custom authorisation service. With the previous model, combining authorisers was cumbersome or outright unsupported depending on the combination. With structured configuration, you declare order, exceptions, and failure criteria explicitly.
For teams that already had complex authorisation set up with prior hacks, migration is worthwhile.
Sidecar containers: the fine detail
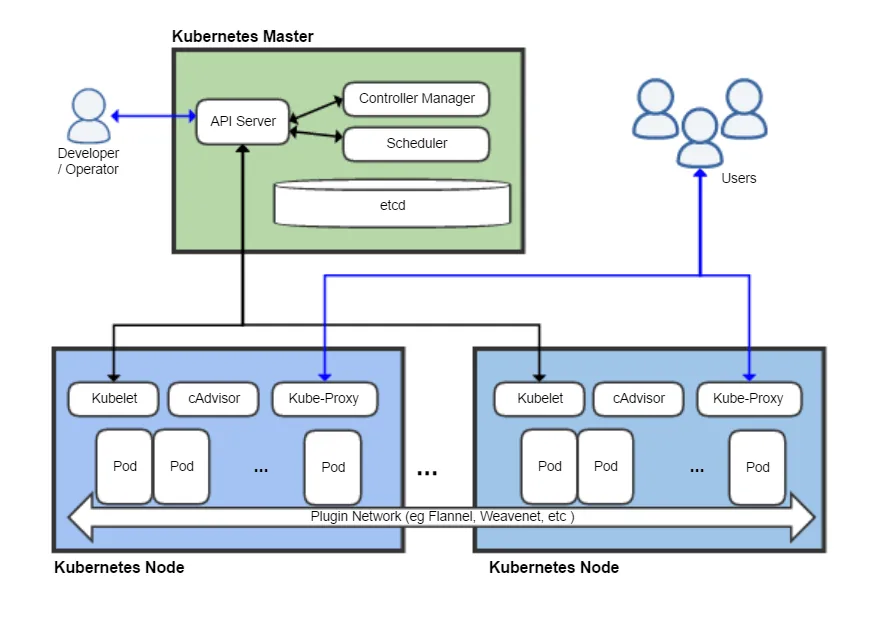
Sidecar containers reached GA in 1.29 as init containers with restartPolicy: Always. The specific change in 1.32 is more discreet but useful: container-level metrics differentiating sidecar from main container and regular init container.
Teams using service mesh with Envoy sidecars or OpenTelemetry collectors as sidecars can now precisely separate proxy resource consumption from the application’s. Previously that required name-based correlation, fragile in environments with varying names. Now it’s direct from kubelet metrics. This granular observability complements continuous eBPF profiling for diagnosing performance regressions.
Deprecations that hurt
Three 1.32 deprecations created more work than expected:
- Removal of the in-tree gitRepo volume plugin. Teams with old Helm charts or legacy manifests using gitRepo to fetch configuration had to migrate to initContainers running git clone or pipeline-generated ConfigMaps.
- Deprecation of FlowSchema and PriorityLevelConfiguration v1beta3 in favour of v1. The API change is minor but affects integrations that used the beta version directly, including some operators updated with delay.
- Deprecation signalling for the unstructured authorisation variant, which stops receiving fixes except critical ones.
The advice is to do the full deprecation review exercise once and document new patterns so the next jump is less painful.
AnonymousAuthConfigurableEndpoints
A small but useful change is the beta capability to restrict anonymous authentication to specific endpoints. Previously it was all-or-nothing. Now anonymous can be permitted for endpoints like /livez or /readyz and prohibited for the rest.
This reduces attack surface without breaking load-balancer probes that depend on anonymous auth for health checks. Teams who had anonymous auth disabled and struggled with external LBs not supporting client authentication gain a clean path.
What has been most used in production
Five months on, the 1.32 features most enabled in real clusters are, in order:
- Structured Authorization GA: near-automatic when upgrading kube-apiserver.
- Sidecar metrics: free observability gain.
- Configurable AnonymousAuth: to clean up lax configurations.
DRA v1beta1 only in GPU-bearing clusters, with mixed success. Some teams deployed it without issue; others found complex integration with pre-existing GPU operators and postponed migration to 1.33.
Paving the way to 1.33
Kubernetes 1.33 shipped on April 23 with in-place pod resize GA as the main star. For clusters already running 1.32, the jump is small in API changes but deserves preparation:
- Review DRA state if used: v1beta1 APIs can keep working, but incremental changes require driver updates.
- Operators handling FlowSchema should be on v1 if they already migrated in 1.32; if not, it’s now mandatory.
- 1.32 continues receiving patches through approximately April 2026, so there’s no physical rush, but don’t stack two jumps either.
My read
Penelope isn’t one of the flashy versions. It doesn’t bring the dramatic change 1.30 or 1.31 did. What it brings is consolidation and debt closure, and that has value often undersold in the moment but felt when you start adopting 1.33 on a clean cluster.
What created most work is the cleanup of deprecations: old Helm manifests with gitRepo, operators on old versions with beta FlowSchema, admission configurations with earlier syntax. All invisible work until upgrade time. With Kubernetes, investment in cluster hygiene always pays back in the following cycle. The same hygiene practices apply to the containerd 2.0 migration, which shares several of these incremental-upgrade patterns.



