AI-integrated DevOps tools in my daily flow
Después de un año midiendo cuáles de las herramientas DevOps con IA integradas realmente aportan y cuáles son humo, este es el stack que se queda en mi flujo diario.
Tag
Después de un año midiendo cuáles de las herramientas DevOps con IA integradas realmente aportan y cuáles son humo, este es el stack que se queda en mi flujo diario.
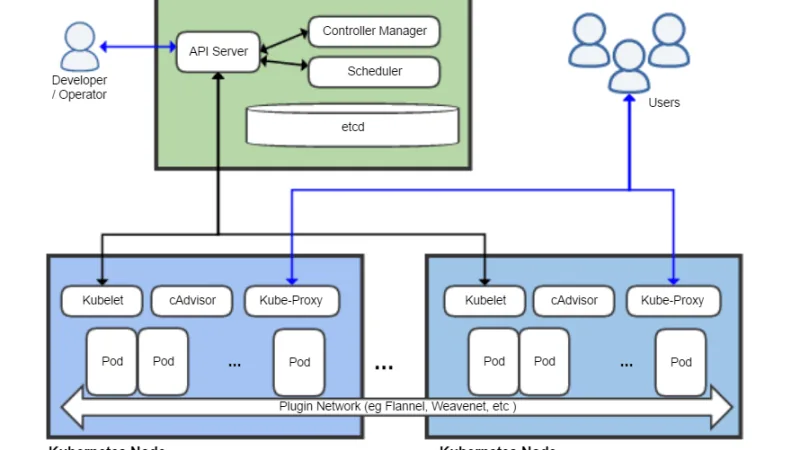
Kubernetes 1.35 llega a GA en 2026 consolidando mejoras gestadas durante tres versiones. Este es el balance desde la operación diaria: qué usar, qué probar y qué evitar.
Los agentes fallan. La pregunta no es si, sino cómo y qué haces en los primeros veinte minutos. Este es el runbook que distingue un incidente contenido de una reputación dañada.
Los cuadros de mando con IA llevan un par de años prometiendo detección de anomalías mágica y causa raíz automática. La realidad es más modesta pero también más útil, si se sabe separar el ruido del valor real. Repaso honesto de qué funciona y qué no.
Han pasado siete años desde que Google publicó el Workbook, y buena parte del libro no ha envejecido. Repaso los patrones que de verdad aplicamos en equipos pequeños y los que resultaron ser cultura de campus.
Kubernetes 1.32 Penelope se publicó en diciembre y lleva varios meses rodando en clusters. Es buen momento para mirar qué cambios han envejecido bien, cuáles han generado trabajo extra y qué aprendizajes llevarse al salto hacia 1.33.
La release 1.33 llega el 23 de abril y el sneak peek oficial de marzo ya deja ver las líneas fuertes: in-place resize GA, sidecars terminando de madurar y un puñado de deprecaciones importantes.
Chaos engineering es más que romper producción. Cómo implementar con hipótesis, blast radius controlado y ROI medible en organizaciones reales.
Los SLOs solo funcionan si el error budget se gestiona de verdad. Cómo definirlos sin ceremonia y usarlos para equilibrar velocidad y fiabilidad.
Los post-mortems blameless son fáciles de decir, difíciles de hacer bien. Técnicas concretas para extraer aprendizaje real sin que se conviertan en teatro.
El libro de SRE de Google es lectura canónica pero su aplicación literal no escala a equipos pequeños. Guía de qué adoptar y qué adaptar.
NIS2 amplía el alcance de la regulación europea de ciberseguridad a más sectores y endurece las obligaciones. Guía práctica para equipos técnicos.