Mature LLM-as-judge: when to trust and when not
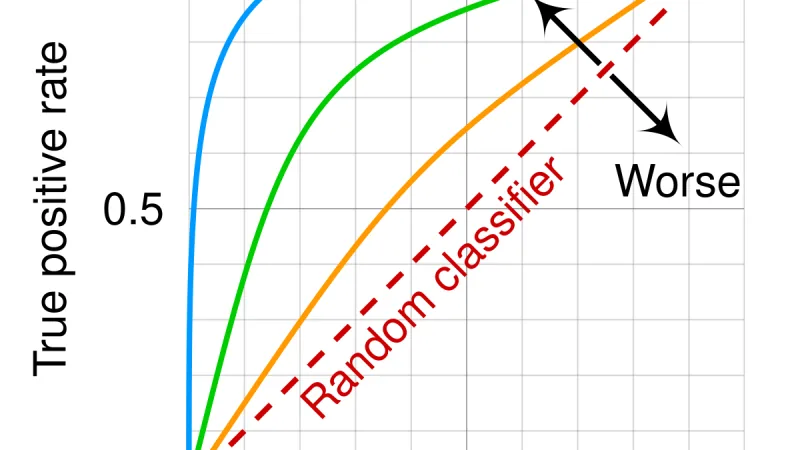
Using an LLM to judge another LLM became widespread in 2024 and remains the only scalable way to evaluate qualitative quality. The mature question is when to trust those numbers.
Tag
Using an LLM to judge another LLM became widespread in 2024 and remains the only scalable way to evaluate qualitative quality. The mature question is when to trust those numbers.
Después de año y medio llenando tableros con agentes en producción, la pregunta que separa equipos que envían fiable de los que van a ciegas sigue siendo la misma: ¿cómo mides que el agente está funcionando?
Durante 2025 cientos de equipos pusieron agentes IA en producción real. A principios de 2026, con datos suficientes, emergen lecciones consistentes sobre qué falla, qué funciona, cuánto cuesta y qué tareas no encajan. Repaso ordenado para equipos que empiezan ahora.
Medir la calidad de un sistema RAG es más sutil de lo que parece. Métricas, conjuntos dorados y los errores más comunes al evaluar.
Cinco meses después del lanzamiento de GPT-4, es momento de separar capacidades reales de hype. Dónde destaca y dónde sigue fallando.