Synthetic training data in 2026: when it works
Synthetic data has moved from precarious substitute for real data to central component of modern training. These are the patterns that work and those still failing.
Tag
Synthetic data has moved from precarious substitute for real data to central component of modern training. These are the patterns that work and those still failing.
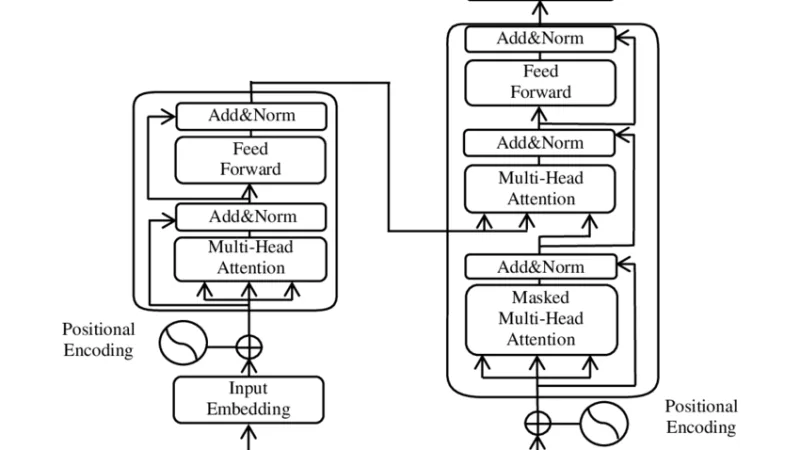
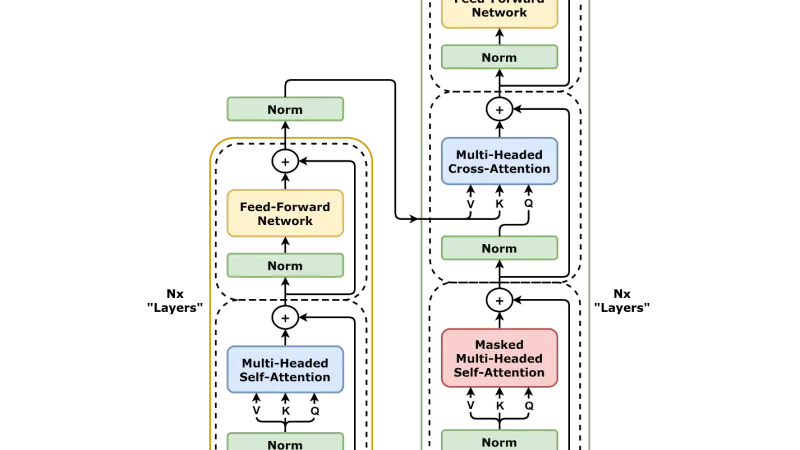
Direct Preference Optimization and its relatives have displaced RLHF as the preferred alignment method in much of the ecosystem. This is the practical state of the field in 2026.
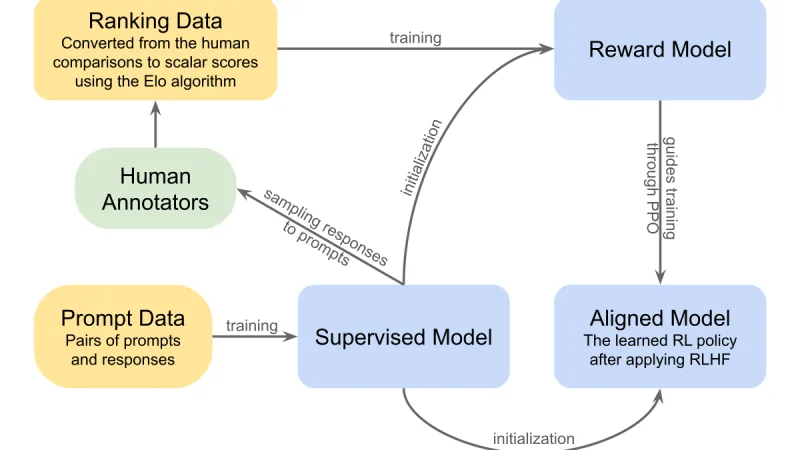
Tres años después de que RLHF se hiciera popular, el paisaje del alineamiento de modelos es más rico. Repaso de RLHF, DPO y los métodos más recientes como KTO o ORPO, con criterios para elegir.
LoRA reduce el coste del fine-tuning de forma dramática. QLoRA va aún más allá combinando cuantización y adaptadores de bajo rango. Cómo funcionan, cuándo usarlos y qué calidad esperar.
Fine-tuning sigue siendo caro y operativamente complejo. Guía para decidir entre RAG, prompt engineering y entrenamiento propio.
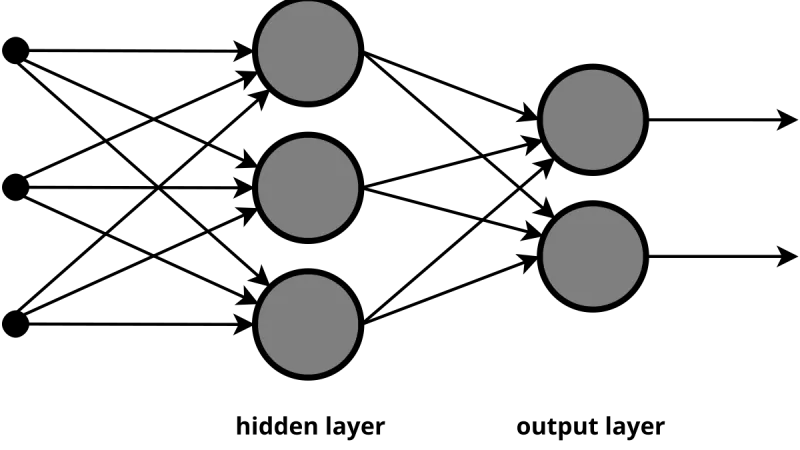
La transferencia de aprendizaje permite reutilizar modelos entrenados en grandes conjuntos de datos para resolver tareas nuevas con mucho menos datos y tiempo de cómputo. Cómo funciona y cuándo usarla.