Synthetic training data in 2026: when it works
Synthetic data has moved from precarious substitute for real data to central component of modern training. These are the patterns that work and those still failing.
Tag
Synthetic data has moved from precarious substitute for real data to central component of modern training. These are the patterns that work and those still failing.
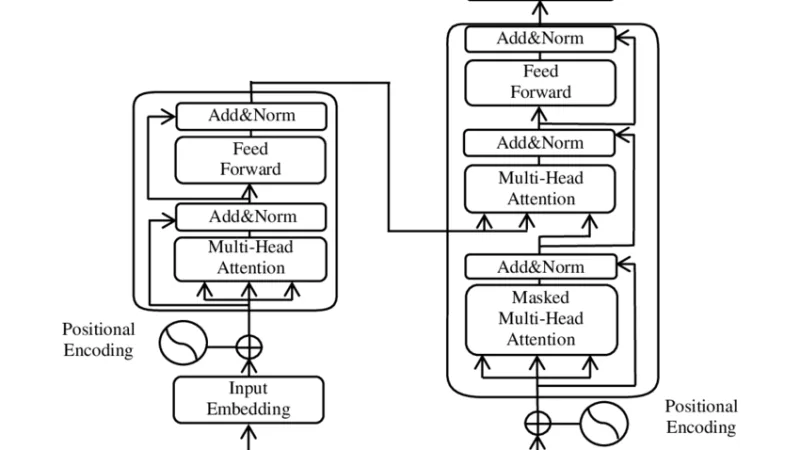
Direct Preference Optimization and its relatives have displaced RLHF as the preferred alignment method in much of the ecosystem. This is the practical state of the field in 2026.
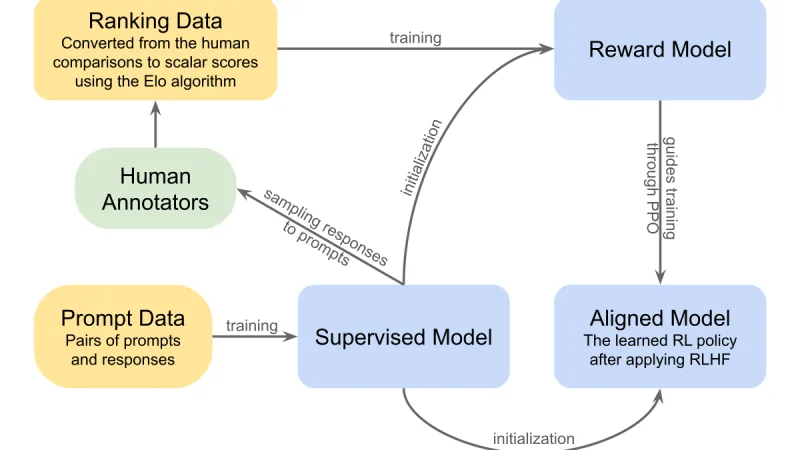
Tres años después de que RLHF se hiciera popular, el paisaje del alineamiento de modelos es más rico. Repaso de RLHF, DPO y los métodos más recientes como KTO o ORPO, con criterios para elegir.
El aprendizaje por refuerzo enseña a los sistemas de IA a tomar decisiones óptimas mediante recompensas y penalizaciones. Componentes, aplicaciones y limitaciones de esta técnica clave.