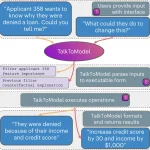
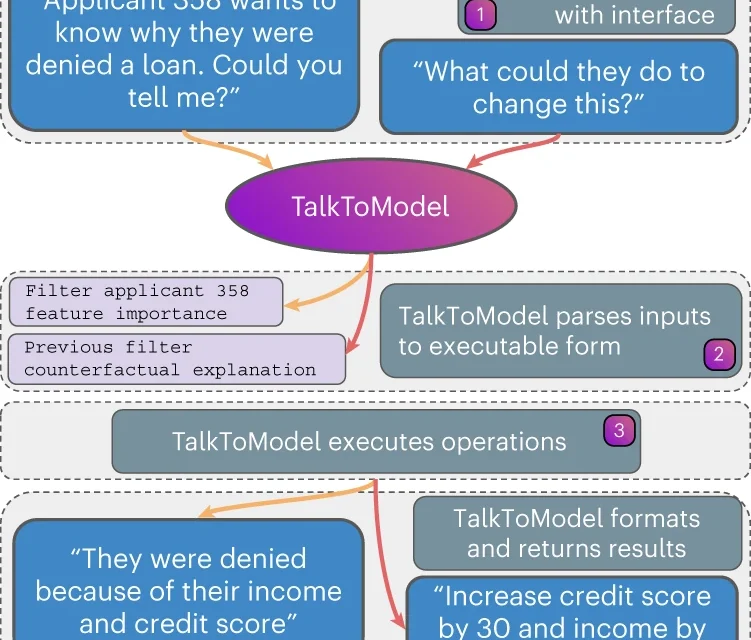
La explicación de la IA a través de XAI
Actualizado: 2026-06-20
Los modelos de inteligencia artificial toman decisiones que afectan a personas —en diagnósticos médicos, en sentencias judiciales, en la concesión de créditos— y sin embargo, durante años, esas decisiones han sido cajas negras. XAI (Explainable Artificial Intelligence, IA explicable) es el conjunto de técnicas y marcos que permiten abrir esa caja y responder a la pregunta más importante: ¿por qué el modelo tomó esta decisión?
Puntos clave
- XAI no es una técnica única, sino un conjunto de métodos para hacer comprensibles las decisiones de los modelos de IA.
- Los enfoques más extendidos son LIME (aproximaciones locales lineales), SHAP (valores de Shapley) y la visualización de mapas de activación.
- La explicabilidad es necesaria para detectar sesgos, cumplir normativas como el RGPD y generar confianza entre los usuarios finales.
- Los sectores con mayor adopción son salud, justicia y servicios financieros.
- Existe una tensión real entre rendimiento del modelo y explicabilidad: los modelos más precisos suelen ser los menos interpretables.
Por qué la opacidad de la IA es un problema
Los sistemas de IA modernos —redes neuronales profundas, transformers, modelos de gradient boosting de miles de árboles— alcanzan un rendimiento excepcional en tareas concretas. Pero esa capacidad viene de la composición de millones de parámetros que ningún humano puede leer de forma intuitiva.
La opacidad genera tres problemas concretos:
- Confianza: los usuarios no adoptan decisiones de sistemas que no entienden, especialmente cuando el coste de un error es alto.
- Sesgo encubierto: si no se puede ver qué variables influyen en la decisión, es imposible detectar discriminaciones indirectas basadas en raza, género o código postal.
- Cumplimiento normativo: el artículo 22 del Reglamento General de Protección de Datos (RGPD) reconoce el derecho de las personas a no ser sujetas a decisiones automatizadas sin explicación. Normativas sectoriales en banca y seguros añaden capas adicionales de exigencia.
XAI es la respuesta técnica a estos tres problemas.
Métodos principales de XAI
La IA explicable no es una sola herramienta: es una familia de enfoques con distintos compromisos entre fidelidad, computación y comprensibilidad.
LIME (Local Interpretable Model-agnostic Explanations) LIME construye un modelo simple —habitualmente lineal— que aproxima localmente el comportamiento del modelo complejo alrededor de una predicción específica. La idea es: aunque el modelo global sea opaco, su comportamiento en el vecindario de un ejemplo concreto puede ser aproximado de forma comprensible. Muy útil para explicaciones por instancia: “este correo fue marcado como spam porque contenía las palabras X e Y.”
SHAP (SHapley Additive exPlanations) SHAP usa la teoría de juegos cooperativos —los valores de Shapley— para asignar a cada variable una contribución justa a la predicción. A diferencia de LIME, SHAP tiene propiedades matemáticas sólidas (consistencia, eficiencia) y permite comparar la importancia de variables entre varios ejemplos. Se ha convertido en el estándar de facto para explicabilidad en modelos tabulares.
Visualización de activaciones En modelos de visión por computadora, técnicas como Grad-CAM (Gradient-weighted Class Activation Mapping) generan mapas de calor que muestran qué regiones de una imagen activaron más la predicción. Son la herramienta habitual para validar que el modelo mira donde debe: si un clasificador de neumonía se activa sobre la esquina con el nombre del hospital en lugar del tejido pulmonar, hay un problema de contaminación de datos.
Modelos intrínsecamente interpretables A veces la mejor solución de XAI es no usar un modelo opaco. Los árboles de decisión de profundidad limitada, las regresiones logísticas con pocas variables y los modelos de atención con arquitecturas bien diseñadas ofrecen interpretabilidad directa sin necesidad de una capa de explicación adicional.
Aplicaciones prácticas de XAI
Salud Los sistemas de apoyo a la decisión clínica que usan modelos de IA para predecir riesgos (sepsis, readmisión hospitalaria, progresión tumoral) deben poder explicar sus recomendaciones a los médicos. Sin explicabilidad, los clínicos no confían en el sistema o no pueden detectar cuándo falla. SHAP se usa de forma extensa aquí para mostrar qué valores de laboratorio o constantes vitales han influido más en la predicción de riesgo.
Justicia y evaluación de riesgo Sistemas como COMPAS, utilizado en EE.UU. para estimar la probabilidad de reincidencia, han sido criticados por falta de transparencia y sesgo racial. La presión regulatoria y académica ha impulsado el uso de XAI en este dominio para auditar las variables que determinan las puntuaciones de riesgo.
Servicios financieros La aprobación o denegación de créditos y seguros está sujeta a normativas que exigen explicaciones individualizadas. Bancos y aseguradoras usan XAI para generar las cartas de denegación reglamentarias y para detectar variables proxy que puedan actuar como discriminadores indirectos.
Marketing y personalización Los sistemas de recomendación y segmentación se benefician de XAI para que los equipos de marketing comprendan por qué el modelo agrupa a determinados clientes o propone ciertos productos. Esto conecta con las técnicas de sistemas de recomendación y filtrado colaborativo que se detallan en otro artículo.
La tensión entre precisión y explicabilidad
El problema más honesto de XAI es que existe una compensación real entre rendimiento y interpretabilidad. Un modelo de gradient boosting con 5.000 árboles superará en precisión a un árbol de decisión de profundidad 4 en la mayoría de tareas. Si se necesita el modelo más preciso, la explicabilidad debe añadirse como capa post-hoc (LIME, SHAP); si se prioriza la interpretabilidad directa, puede aceptarse una merma en el rendimiento.
Esta tensión conecta con la que se describe en el contexto del código interpretable en herramientas como GitHub Codespaces: la legibilidad del código es un valor en sí mismo, no solo una comodidad. Lo mismo aplica a los modelos: la explicabilidad no es un adorno, es parte de la calidad del sistema.
La tendencia reciente en investigación apunta a modelos que son precisos y más interpretables simultáneamente —transformers con mecanismos de atención más transparentes, modelos de reglas neuronales—, aunque ninguno ha resuelto aún la tensión de forma definitiva.
Conclusión
XAI responde a la demanda legítima de que los sistemas de IA justifiquen sus decisiones. Métodos como LIME y SHAP permiten abrir la caja negra sin renunciar al rendimiento de los mejores modelos. La adopción de XAI no es opcional en entornos regulados o de alto impacto: es la diferencia entre un sistema de IA que genera confianza y uno que genera resistencia.



