La Red Neuronal Totalmente Conectada: Un Enfoque Innovador en el Aprendizaje Automático
Actualizado: 2026-07-12
En una red neuronal totalmente conectada, cada neurona de una capa está enlazada con todas las neuronas de la capa anterior y de la siguiente. Esta conectividad total la convierte en la arquitectura más expresiva y también en la más costosa computacionalmente: es el punto de partida obligatorio para entender el aprendizaje profundo.
Puntos clave
-
Cada neurona recibe como entrada el resultado de todas las neuronas de la capa precedente, multiplicado por un peso aprendible.
-
La arquitectura puede modelar relaciones no lineales complejas entre entradas y salidas.
-
Su poder aumenta con la profundidad, pero también el riesgo de sobreajuste y el coste computacional.
-
En visión se combinan con capas convolucionales; en NLP, con mecanismos de atención.
-
La elección de función de activación (ReLU, sigmoide, tanh) determina la capacidad de aprender relaciones no lineales.
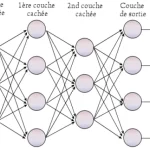
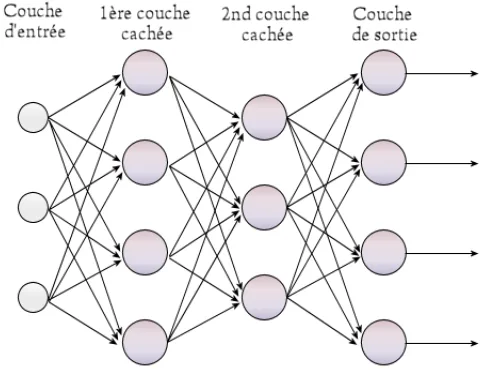
Arquitectura: cómo se conectan las capas
Una red totalmente conectada se organiza en tres tipos de capas:
-
Capa de entrada: recibe los datos en bruto (píxeles, valores tabulares, embeddings).
-
Capas ocultas: transforman la representación de forma sucesiva; cada neurona aplica una función de activación a su suma ponderada de entradas.
-
Capa de salida: produce la predicción final, un valor continuo para regresión o una probabilidad para clasificación.
 Diagrama de red neuronal perceptrón multicapa con cuatro capas totalmente conectadas
Diagrama de red neuronal perceptrón multicapa con cuatro capas totalmente conectadas
El número de parámetros (pesos) crece cuadráticamente con el número de neuronas: una capa de 1000 neuronas conectada a otra de 1000 tiene 10⁶ pesos. Esto hace que las redes densas sean inviables para imágenes de alta resolución sin arquitecturas especializadas como las convolucionales.
Propagación hacia adelante y entrenamiento
El flujo de datos en una red densa:
-
Las entradas se multiplican por los pesos de la capa 1 y se suman (producto escalar).
-
Se aplica la función de activación: ReLU, tanh, sigmoide, según la arquitectura.
-
La salida pasa a la siguiente capa y el proceso se repite.
-
En la capa final, la función de pérdida compara la predicción con la etiqueta real.
-
El gradiente de la pérdida se propaga hacia atrás (backpropagation), ajustando todos los pesos.
 Comparativa de funciones de activación utilizadas en las capas de una red densa
Comparativa de funciones de activación utilizadas en las capas de una red densa
La función escalón fue la primera función de activación usada en el perceptrón original. Las limitaciones de su no-diferenciabilidad llevaron al desarrollo de sigmoide, tanh y finalmente ReLU, que hoy domina.
Aplicaciones principales
Las redes totalmente conectadas funcionan bien en:
-
Clasificación de datos tabulares: predicción de churn, scoring crediticio, detección de fraude.
-
Reconocimiento de patrones: combinadas con capas de extracción de características (CNN para imágenes, RNN para secuencias).
-
Predicción de series temporales: con arquitecturas LSTM + densas en la capa de salida.
-
Procesamiento de lenguaje natural: como cabecera de clasificación sobre embeddings pre-entrenados.
En análisis de imágenes con visión computarizada, las capas densas aparecen típicamente al final de la red, después de que las capas convolucionales han extraído características espaciales. Los modelos pre-entrenados modernos usan capas densas en sus cabeceras de tarea, aunque el trunk (cuerpo) sea un transformer.
Para el aprendizaje federado, la arquitectura densa es frecuente porque es simple de serializar y agregar en el servidor central. Y en el contexto del aprendizaje por refuerzo, la red de política (policy network) suele ser una red densa de 2-4 capas.
Ventajas y limitaciones
Ventajas:
-
Capacidad universal de aproximación: con suficiente profundidad y anchura, puede modelar cualquier función continua (teorema de aproximación universal).
-
Versatilidad: funciona con cualquier tipo de entrada vectorizada.
-
Facilidad de interpretación de la capa de salida.
Limitaciones:
-
Coste computacional cuadrático en el número de neuronas.
-
Propenso al sobreajuste en conjuntos de datos pequeños: requiere regularización (dropout, L2).
-
No incorpora invariancia a traslación ni a permutación: para imágenes, las CNN son más eficientes; para secuencias, las RNN o transformers.
Conclusión
La red neuronal totalmente conectada es el bloque fundamental del aprendizaje profundo: el punto de partida conceptual y práctico de cualquier arquitectura más especializada. Entender cómo fluye la información a través de capas densas, qué papel juega cada función de activación y cómo el gradiente ajusta los pesos es la base sobre la que se construyen CNN, RNN, transformers y todo lo que ha venido después. Dominarlo no es opcional para quien quiera trabajar con IA aplicada.



