Función Lineal: Una Función de Activación Común
Actualizado: 2026-07-07
La función lineal f(x) = ax + b es la función de activación más simple que puede usar una neurona. Su papel en redes neuronales es limitado pero concreto: es la elección estándar para la capa de salida en problemas de regresión. Entender por qué no se usa en capas ocultas es tan importante como saber cuándo sí usarla.
Puntos clave
-
La función lineal f(x) = ax + b produce una salida directamente proporcional a la entrada, sin transformación no lineal.
-
Es la función de activación estándar en la capa de salida para problemas de regresión (predicción de valores continuos).
-
Usar funciones lineales en capas ocultas equivale matemáticamente a colapsar toda la red en una sola capa lineal.
-
Su derivada constante evita el problema del gradiente desvanecido, pero no compensa su incapacidad para modelar no linealidades.
-
En problemas con valores atípicos, su sensibilidad al rango de los datos requiere normalización previa.
Definición y propiedades matemáticas
La función lineal en el contexto de activaciones de redes neuronales adopta la forma general:
f(x) = _a_x + b
Donde a es la pendiente y b el intercepto. En la práctica, para capas de salida en regresión, el caso más común es a = 1, b = 0, lo que simplifica a la función identidad, f(x) = x: la neurona simplemente pasa su suma ponderada sin transformación.
Las propiedades matemáticas de la función lineal son:
-
Dominio: todos los reales (−∞, +∞).
-
Rango: todos los reales (−∞, +∞), sin saturación, lo que es ventajoso para regresión.
-
Derivada: constante (f'(x) = a), lo que significa que el gradiente no se desvanece al propagarse hacia atrás.
-
Continuidad: continua y diferenciable en todos sus puntos.
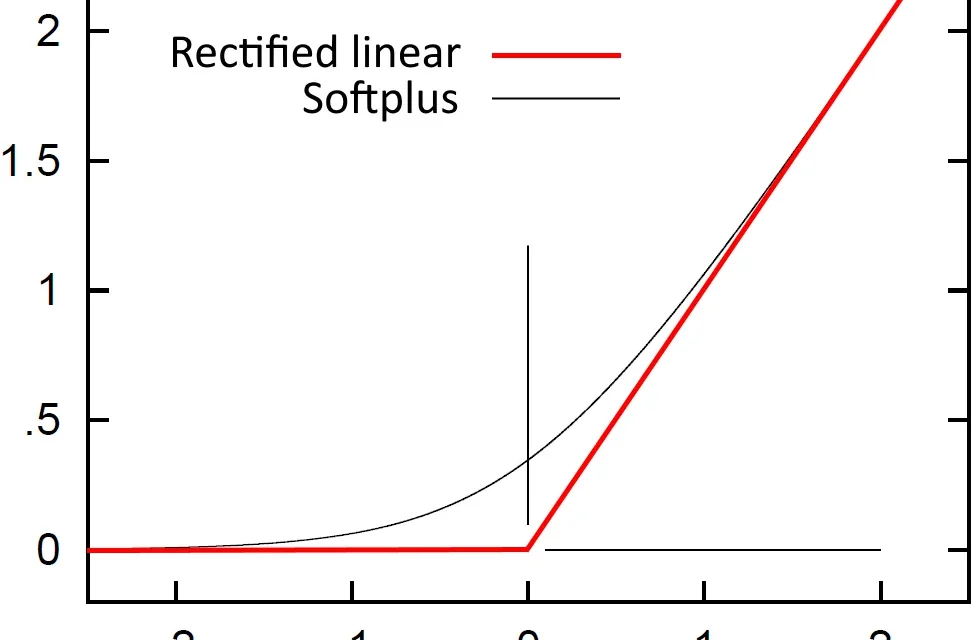
 Gráfica de función lineal rectificada (ReLU) y Softplus mostrando la relación entre linealidad y no linealidad en activaciones
Gráfica de función lineal rectificada (ReLU) y Softplus mostrando la relación entre linealidad y no linealidad en activaciones
Por qué la función lineal falla en capas ocultas
Esta es la limitación crítica que cualquier practicante de redes neuronales debe interiorizar: si todas las capas de una red usan funciones de activación lineales, la red entera es equivalente a una sola capa lineal.
La demostración es directa. Si la capa 1 computa h₁ = W₁x y la capa 2 computa h₂ = W₂h₁, entonces:
_h_2 = _W_2(_W_1x) = (_W_2_W_1)x = W′x
La composición de dos transformaciones lineales sigue siendo una transformación lineal: la multiplicación de matrices no gana nada por apilarse. Añadir más capas lineales no añade capacidad expresiva. Por tanto, una red profunda con activaciones lineales tiene exactamente la misma expresividad que una regresión lineal simple.
Esto es precisamente por qué funciones como ReLU, tanh y sigmoide existen: introducen la no linealidad que permite a la red aprender representaciones complejas en capas sucesivas.
Cuándo usar la función lineal correctamente
La función lineal sí tiene un lugar bien definido:
Capa de salida en regresión. Cuando el objetivo es predecir un valor continuo sin restricciones (precio de una vivienda, temperatura, velocidad), la capa de salida debe usar la función identidad. Aplicar sigmoide o ReLU truncaría el rango de valores posibles.
Normalización de entradas. En la capa de entrada, a veces se aplica una transformación lineal para escalar los datos a un rango estándar (normalización min-max o estandarización Z-score). Esta es una operación de preprocesamiento, no una función de activación en sentido estricto.
Redes de autoencoder en la capa central. En algunas arquitecturas de codificador-decodificador, la capa de cuello de botella puede ser lineal para producir una representación compacta no acotada.
La relación con ReLU y el universo de activaciones
ReLU (Rectified Linear Unit) es, en cierta forma, una extensión de la función lineal:
ReLU(x) = max (0, x)
Es lineal para x > 0 y constante (0) para x ≤ 0. Esta pieza lineal es lo que le da a ReLU su eficiencia computacional y su resistencia al gradiente desvanecido, mientras que la discontinuidad en x = 0 introduce la no linealidad necesaria. Ver la comparativa completa en formulación matemática de entrada de red neuronal.
Para la capa de salida en clasificación multiclase, la alternativa es la función Softmax, que convierte un vector de salidas arbitrarias en una distribución de probabilidad.
 Curva logística (sigmoide) comparada con la función lineal, mostrando la saturación de la sigmoide vs. el rango ilimitado de la función lineal
Curva logística (sigmoide) comparada con la función lineal, mostrando la saturación de la sigmoide vs. el rango ilimitado de la función lineal
Sensibilidad a valores atípicos
Una limitación práctica de la función lineal en la capa de salida de regresión es su sensibilidad a outliers. Al no tener saturación, valores extremos en los datos de entrenamiento afectan desproporcionadamente la pendiente de la función de pérdida MSE, sesgando el modelo. Las mitigaciones estándar son:
-
Usar la función de pérdida MAE (Mean Absolute Error) o Huber loss en lugar de MSE, que son menos sensibles a outliers.
-
Normalizar las salidas antes del entrenamiento y desnormalizar las predicciones al interpretarlas.
-
Eliminar o acotar los outliers en el preprocesamiento cuando tengan origen en errores de medición.
Para un contexto más amplio sobre cómo estas funciones encajan en el diseño de redes completas, ver redes neuronales y deep learning. Si usas redes en producción, el benchmarking inicial con LazyPredict ayuda a confirmar si una red neuronal es mejor que alternativas lineales antes de invertir en diseño de arquitectura.
Conclusión
La función lineal ocupa un lugar preciso y no sustituible en las redes neuronales: la capa de salida para regresión. Fuera de ese rol, usar activaciones lineales en capas ocultas elimina el beneficio computacional de apilar capas. Conocer sus limitaciones matemáticas, especialmente la equivalencia de composiciones lineales a una sola capa, es el primer paso para entender por qué las funciones de activación no lineales son el corazón real de cualquier red neuronal útil.
Este artículo también está disponible en inglés: Linear Function: A Common Activation Function.



