Computer Use in production: agents that drive the interface
Actualizado: 2026-05-03
When Anthropic released Computer Use in October 2024 the reaction was a mix of awe and skepticism: on one hand, a model that could look at a screen, move the mouse, and type; on the other, too many doubts about reliability, security, and cost to imagine it in production. Nearly nine months later, the question has changed. Some teams have taken it to real tasks and patterns are emerging about where it works, where it isn’t yet suitable, and how to configure it so the promise doesn’t collide with operational reality.
For broader context on AI agents in enterprise flows, the analysis of AI agents in the enterprise covers adoption criteria. Security patterns for agents operating with system access are covered in LLM agent security. The post on CI with AI agents describes a more bounded and controlled agentic use scenario.
Key takeaways
- Current error rates are 5–15% on well-specified tasks, down from 30–40% at launch; per-step latency and cost have roughly halved.
- Works well for data extraction from interfaces without an API, repetitive bureaucratic flow navigation, and visual validation of web application changes.
- Not suitable for tasks with irreversible consequences without human approval, information-dense interfaces, or tasks exceeding 50 steps without intervention.
- The double-check pattern — agent captures result and compares to the stated expectation before advancing — reduces error on long tasks at the cost of doubling token spend.
- Approximate cost: 50–150 cents per 20-step task; around 200 euros annually for a task run once per day.
What has changed since October 2024
The initial version of Computer Use was a functional proof of concept. The model understood screenshots, could decide where to click and how to type, but latency was high, error rate on long tasks was 30–40%, and each step consumed significant tokens. For demos it impressed; for real work it frustrated.
Later releases have improved on three axes:
- Per-step latency has dropped roughly in half.
- Error rate on well-specified tasks has come down to the 5–15% range depending on complexity.
- Token consumption per step has dropped thanks to better visual compression.
Not magic yet, but it has crossed the threshold where certain tasks begin to be economically viable.
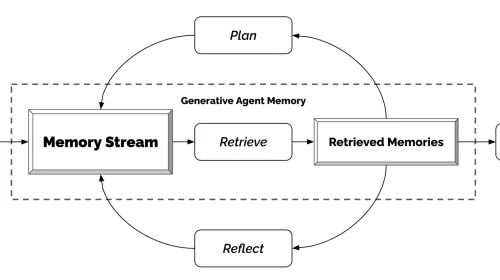
Where it’s working now
The first category where Computer Use shines is data extraction from interfaces without an API. There are old enterprise applications, vendor portals, internal systems with green-screen layouts where navigating with an agent is cheaper than writing a fragile scraper or paying for custom integration. In a project seen up close, a team replaced four weeks of scraper development with two days of agent configuration, with better maintainability because the agent adapts to minor interface changes without sharp breakage.
The second category is navigation of repetitive bureaucratic flows: filling multipage forms with conditional logic, downloading periodic reports from portals with authentication, marking sets of items in filtered lists. These are tasks where classic RPA works, but where RPA configuration cost exceeds that of an agent that understands natural language and doesn’t need every step explicitly recorded.
The third, more experimental, is visual validation of changes in web applications. An agent can open a preview branch, navigate critical screens, describe what it sees, and compare with the previous version. It doesn’t replace automated tests, but catches visual and flow regressions that unit tests don’t cover.
Where it isn’t yet suitable
The list of cases where Computer Use is still problematic is longer than where it works well:
- Tasks with irreversible consequences without human approval: purchases, shipments, financial approvals. The error cost is asymmetric: the agent can err with low probability but the loss when it does is large.
- Information-dense interfaces: large spreadsheets, dashboards with dozens of fields, tables with complex horizontal scroll. The agent loses track often.
- Multilingual or ambiguous content: if the agent has to decide whether a button says “Send” or “Cancel” in a medium-resolution screenshot, the outcome depends too much on factors the model doesn’t control.
- Tasks exceeding 50 steps without intervention: if each step has 95% success, a 50-step task has 7% probability of completing without error. For 500-step tasks, completing without intervention is essentially impossible.
Emerging patterns
The first pattern consolidating is double-check execution. The agent makes a step, captures the result, compares against the expectation declared at the start, and only advances if there’s a match. This pattern roughly doubles token cost but notably lowers error rate on long tasks. It’s the equivalent of programming with assertions at each step.
The second is supervised execution. A cheaper model or a classic rule system watches the main agent’s actions and stops execution if trouble signs appear: click loops in the same place, error messages, unexpected screens. Separating execution and supervision into two processes is more expensive but much more robust.
The third, more recent, is execution in an isolated environment with deferred commit. The agent works on a temporary environment — virtual machine, container, private browser session — and changes only apply to the real environment after a review step approves them. This pattern is heavier but fits well for high-impact tasks.
Real cost
A task the agent completes in 20 steps consumes on the order of 50 to 150 cents, depending on the model and screenshot size. For tasks run once a day, the annual cost per task is around 200 euros. For tasks run several times a day, the math scales fast.
The useful comparison isn’t against zero, it’s against the cost of an alternative:
- A custom scraper costs weeks of development and ongoing maintenance.
- Formal integration via API, when it exists, costs double.
- A person doing the same task costs much more per hour.
Computer Use starts to make economic sense when the task is repetitive but changing, the API doesn’t exist, and volume is enough to amortize initial configuration.
Practical security
The least-discussed risk is security. An agent operating interfaces with credentials lives close to any data visible on screen. If the machine where the agent operates has access to email, internal systems, or authenticated browsers, any agent failure — or malicious instruction injected into what it sees — can lead it to act outside the intended perimeter.
The recommendation for any serious use is to run the agent in a dedicated virtual machine, with credentials scoped to the specific task, without access to anything else. The temptation to reuse the user’s authenticated session is huge because it simplifies setup, but it’s the quick door to an incident. Security incidents with computer use agents almost all come through that door: overly generous credentials, overly wide perimeters, no supervision.
When it pays off
My practical rule is: Computer Use pays off when the task is repetitive, lacks an API, the error cost is low or reversible, and volume justifies the initial setup. Outside those four requirements, the equation complicates fast.
For teams that want to explore, the best path is a specific, measured task with bounded budget. Configure the agent, measure success rate for two or three weeks, compute real cost and decide whether to scale. Starting with big ambition and vague strategy is the fast way to spend money without learning anything.
Within two years Computer Use will be in many more flows than we imagine today, but not to replace people in complex tasks — rather to replace integration layers currently done with fragile scrapers and RPA. The likely pattern is agents as bridges between old systems and new ones, operating in short supervised shifts with limited authority.




