AI agents in the enterprise: from demo to measurable value
Updated: 2026-07-07
Over recent months the discourse on AI agents has gone through an interesting phase. Until recently it was almost all flashy demos: an agent browsing a website, another writing an email, another booking a flight. The infrastructure to build a serious agent exists: OpenAI published the Agents SDK and Responses API[1], Anthropic consolidated Computer Use and extended the Model Context Protocol[2], now past 100 million monthly downloads, and Google advanced with Gemini 2.0[3] and its tool integrations. The question is no longer whether it’s possible; it’s whether it pays off and, above all, how to measure it.
This post reflects on what separates agents that have generated real enterprise value from those that remained as POCs without metrics. It’s not a framework tutorial; it’s a reading of success and failure patterns from experience with several implementations.
Key takeaways
-
The agent with the most ROI is usually not the most sophisticated; it’s the one automating a well-defined process with high manual workload.
-
The most common mistake is starting with the agent instead of the process: without a clear flow, the agent adds complexity without value.
-
Human oversight is not a luxury; it’s the mechanism that makes the agent improve over time.
-
The real cost of a production agent includes ongoing prompt engineering, monitoring, and tool updates.
-
Measure before deploying: if you don’t have a baseline metric for the manual process, you can’t demonstrate agent value.
Why the demo doesn’t predict enterprise value
Agent demos are convincing because they show capability under controlled conditions. The agent browses, extracts, summarizes, writes. The problem is that the step from "works under controlled conditions" to "works in production with real data and irregular flows" is where most projects get stuck.
What the demo doesn’t show is the real failure rate on unanticipated inputs, the cost of error correction when the agent produces incorrect output reaching a downstream system, latency under real load, and the maintenance effort when the API, document format, or tool policy the agent uses changes. MIT’s 2025 report on the state of AI in business confirms it with an uncomfortable number: 95% of generative AI pilots never reach production with measurable return[4], and in my experience the reason is almost never the model; it’s the lack of upfront process instrumentation.
The most useful framework I’ve found for evaluating whether an agent use case makes enterprise sense starts with four questions:
-
Does the process the agent automates have a quantifiable manual workload?
-
Is the agent’s output verifiable without a human expert?
-
Is the cost of error tolerable or recoverable?
-
Is the process stable enough that the agent’s tools won’t become obsolete quickly?
Cases that answer yes to all four are much more likely to generate measurable value.
Cases where agents have worked in the enterprise
Agent use cases that have generated real ROI in organizations I’ve worked with share concrete characteristics:
Document processing with structured extraction. Invoices, contracts, forms. The agent extracts fields, validates against business rules, and produces a structured record. Accuracy rate is measurable (compared against manual review of a sample), errors have consequences but are recoverable, and volume justifies automation. Hour savings are direct and auditable.
Ticket or request classification and routing. The agent reads free text, classifies it according to a known taxonomy, extracts key data, and assigns it to the correct team or system. Value is reduced first-response time and elimination of manual classification work. The metric is clear: routing time before and after.
Multi-source information synthesis for internal briefings. The agent collects data from multiple internal or external APIs, combines it, and produces a structured summary (project status, market update, incident summary). Value is meeting or report preparation time. This case requires human output supervision, but volume justifies having it.
Onboarding or configuration flow automation. The agent executes predefined steps (create account, assign permissions, send communications) for new employees, new customers, or new environments. Value is reduced onboarding time and fewer manual configuration errors. Human oversight focuses on exceptions, not common cases.
Failure patterns that repeat
Agent projects that don’t generate value share equally recognizable patterns:
Starting with the agent, not the process. If you don’t have the flow the agent will automate documented (who does what, with which inputs, what the possible states are, what the common errors are), the agent inherits the ambiguity of the manual process and amplifies it. The agent is the solution to the flow problem, not the substitute for flow analysis.
No baseline metrics. If you haven’t measured how long the manual process takes or what its current error rate is, you can’t demonstrate the agent improved anything. "Works better" is not a business metric. Instrumenting the process before the agent is part of the project, not an extra.
Insufficient human oversight in the initial phase. Agents produce errors in ways humans don’t anticipate. Without a dense supervision period (where a human reviews every agent output before it acts), you can’t build the edge-case library that lets you improve prompting and tools. Initial oversight is not inefficiency; it’s reliability investment.
Underestimating maintenance. Agents degrade when the environment changes: API updates, document format changes, access policy modifications. Without a monitoring and update process, reliability drops gradually until the agent fails more than it helps. Maintaining a production agent is not occasional; it’s continuous, and it’s the same decay pattern I document in AI agent incidents: recovery runbooks that work.
Design decisions that matter
When the use case makes sense and the process is clear, design decisions make the difference between an agent that improves over time and one that stagnates:
Design for oversight, not against it. An agent producing verifiable outputs (with evidence of the steps it followed, with cited sources, with explicit reasoning) is easier to supervise, correct, and improve. Opaque outputs make it hard to identify where the reasoning fails.
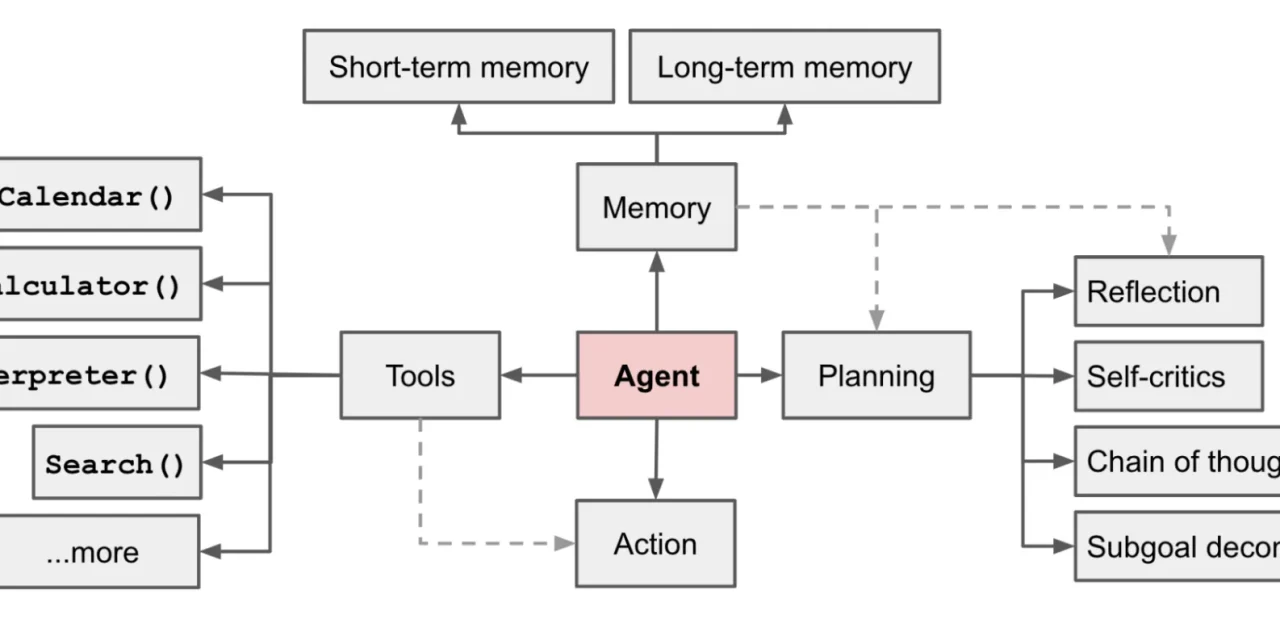
Separate tools from instructions. The tools the agent uses (APIs, databases, internal systems) must be well-documented with stable interfaces. When the tool changes, only the tool description needs updating, not rewriting the whole prompt.
Establish explicit limits on what the agent can do. An agent with unlimited write permissions is more dangerous than useful in production. The most trusted agents are those with bounded permissions that escalate to humans when they encounter a case outside their scope. For the security dimension of agents, the analysis of LLM agent security provides the relevant threat framework.
Measure the escalation rate. If the agent escalates to humans more than 20-30% of cases, the process isn’t well-defined enough to automate. Escalation rate is the use-case maturity metric, not the agent maturity metric. This structural control is one of the pillars I lay out in enterprise agent governance: the controls that are no longer optional.
My read
AI agents in the enterprise generate value when they solve well-defined processes with high manual workload, not when they demonstrate sophisticated reasoning capability. Agent sophistication is secondary to the clarity of the process it automates and the quality of the oversight infrastructure surrounding it.
Value doesn’t come from the demo; it comes from time saved, errors avoided, and capacity freed for higher-value work. Those three things are measurable if the project design accounts for them from the start. Without a before metric, there’s no after value demonstration.
Puedes leer este artículo en español en Agentes de IA en empresa: de demo a valor medible.



