Continuous integration with AI agents: early patterns
Updated: 2026-07-12
I’ve spent six months integrating AI agents into the CI pipelines of several projects and the experience has been a steep curve: first attempts were disappointing, early iterations generated more noise than value, and only after tuning context and limits did the patterns that actually help appear. This post gathers what I’ve learned about where and how to use agents in CI without turning every pull request into a debate with a machine that doesn’t fully understand what it’s reviewing. See also: AI tools for developers: the 2026 stack.
For the broader context of agents in production, the analysis of AI agents in the enterprise covers organizational adoption criteria. Agent security in pipelines is covered in LLM agent security. The code review pattern also connects with CodeQL and GitHub Advanced Security.
Key takeaways
-
Automatic diff review works well when the agent receives broad context: full files and recent branch history, not just changed lines.
-
Explicitly bounding what to review (error handling logic, naming, module coherence, coverage) eliminates 80% of noise.
-
Agent-generated tests need human review before merging; tautological assertions are the most common problem.
-
Automatic fix suggestions are only useful for problems the agent can explain in a sentence.
-
Approximate cost: 5–30 cents per mid-sized pull request; worthwhile when human review is the bottleneck.
Why right now
The reasonable question is why talk about this in 2025 and not earlier. The answer is twofold. Current models handle context windows large enough to analyze a real diff with its neighboring files, without artificial chunking. And platform integrations have matured: GitHub Actions, Gitea Actions, and their peers already have runners designed to execute steps with models, and the per-pull-request cost has dropped to where it pays off for small teams.
Until 2024, setting up an AI reviewer required custom plumbing: extracting the diff, trimming to fit the window, calling the model, processing the response. In 2025 there are tools that do the first layer of that work, so the entry barrier is much lower and the focus can be on configuring behavior.
Diff review as the base pattern
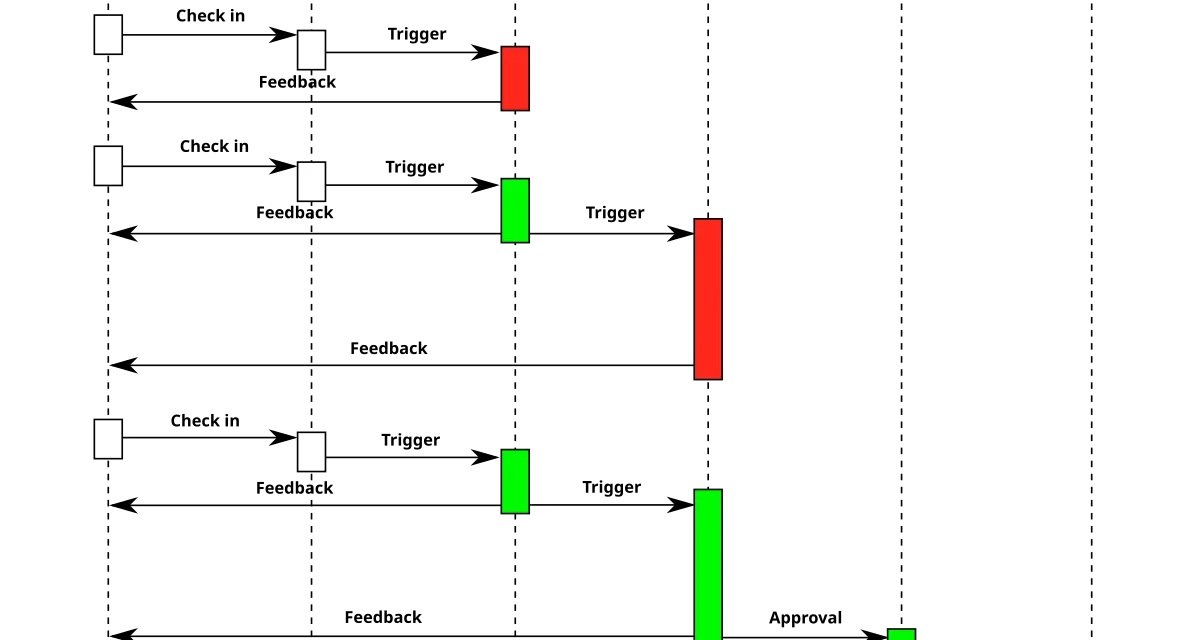
The most useful pattern I’ve found is automatic review of diffs in open pull requests. A CI job launches an agent that reads the diff, the changed files in their entirety, and the related files via imports. The agent publishes a comment with observations: possible logical errors, violations of project conventions, missing tests, new dependencies not justified.
The key for this pattern to work is context. An agent that only sees the changed lines often says nonsense; an agent that sees entire files and the recent branch history says useful things. In tests, going from 500-line context to 3,000-line context dropped the false-positive rate from about 40% to under 10%.
The second critical factor is bounding what to review. Asking the agent to review everything is asking it to say something about everything, including where it knows nothing. Giving it an explicit list works better: error-handling logic, variable names, coherence with the module pattern, tests that cover changes. Outside that list, silence. This removes noise and preserves the comment’s credibility.
Generation of missing tests
The second pattern my pipeline uses is generating tests for new functions without coverage. A separate job detects public functions added in the diff that lack associated tests, generates test cases with the agent, and proposes the result as an additional commit on the pull request.
This pattern is more delicate than review. Generated tests need to be good, not just exist, and you have to resist the temptation to raise coverage with tests that prove nothing substantial. What has worked is generating only happy paths and the most obvious edges, and explicitly asking the human to add error cases and adversarial cases.
The second caution is tests that look correct but always pass. AI tends to generate tautological assertions: it checks that the function returns what it returns. Reviewing generated tests before merging is mandatory; blindly trusting that coverage rises is the fast path to a test base worse than the one before.
Proposed fixes as suggestions
The third pattern, less mature but promising, is the proposal of automatic fixes. When the agent detects a concrete issue, besides describing it in text, it publishes a suggestion on the pull request that the author can accept with a click. This pattern is powerful because it turns an abstract comment into concrete code.
The limit is that it only works well for small, local problems: formatting, naming, missing input validations. For architectural changes or design decisions, the agent lacks the context to propose the right fix and ends up suggesting things worse than the original problem. My rule is to enable automatic suggestions only for problems the agent can explain in a sentence; for problems that require a paragraph, let the author decide.
Real costs and practical limits
A quality agent reviewing a mid-sized pull request costs between 5 and 30 cents per run depending on model and context size. For a project with 50 pull requests a week, that’s 10–60 euros a month. Not free but not expensive compared to the human review time saved on small pull requests.
The limit that frustrates most is memory between runs. Each agent invocation is independent: it doesn’t remember the team’s prior decisions, doesn’t learn from rejected suggestions, doesn’t refine criteria against project-specific conventions. There are mitigation strategies: including history fragments in the context, keeping a conventions file injected into each call. None is complete.
What isn’t worth automating
After several months I’ve ended up with a list of things not to ask the agent for in CI:
-
Security change review: false negatives are expensive and the agent lacks the full context of the project’s security policy. A classic security linter and dedicated human review is better here.
-
Changes touching public API contracts: the agent can detect syntactic breaks but doesn’t understand the semantic implications of a contract change.
-
Performance analysis: the agent can read code and speculate about complexity, but can’t measure. For performance decisions, you measure, you don’t opine.
How I configure the pipeline
My current setup has three distinct steps:
-
Fast, cheap step: syntactic and style analysis with classic tools. This filters 80% of trivial problems before the agent sees them, saving cost and improving signal.
-
Review agent: runs only if the first step passes and if the pull request changes more than 20 lines. For very small changes the cost doesn’t amortize. The agent receives the diff, touched files in full, recent branch history, and a project conventions file kept in the repository.
-
Test generator: triggered only if new functions without coverage are detected and the branch isn’t a hotfix. Hotfixes are quick and the author knows what they’re doing; blocking with generated proposals adds unnecessary friction.
When it pays off
My criterion for deciding whether a project benefits from agents in CI is simple: teams of three or more people where human review is the bottleneck, code with clear documented conventions, and budget for 20–100 euros a month in model cost. For smaller teams, human review is still cheaper and more precise.
For one-off or exploratory projects, agents in CI are noise. The fixed setup cost doesn’t amortize and the agent ends up commenting on things the author already knows and has decided to ignore. Project maturity is a requirement sometimes overlooked.
Within a year the pattern will be more sophisticated: agents that remember past decisions, refine criteria from team feedback, coordinate long reviews in multiple passes. For now, simple and bounded patterns are the ones that work. Resisting the temptation to ask the agent for everything and concentrating its work on three or four tasks where it adds value is the fast way to benefit without burning credibility.



