Linear Function: A Common Activation Function
Actualizado: 2026-05-03
The linear function f(x) = ax + b is the simplest activation function a neuron can use. Its role in neural networks is limited but concrete: it is the standard choice for the output layer in regression problems. Understanding why it is not used in hidden layers is as important as knowing when to use it.
Key takeaways
- The linear function f(x) = ax + b produces an output directly proportional to the input, with no non-linear transformation.
- It is the standard activation function in the output layer for regression problems (prediction of continuous values).
- Using linear functions in hidden layers is mathematically equivalent to collapsing the entire network into a single linear layer.
- Its constant derivative avoids the vanishing gradient problem, but this does not compensate for its inability to model non-linearities.
- In problems with outliers, its sensitivity to the data range requires prior normalisation.
Definition and mathematical properties
The linear function in the context of neural network activations takes the general form:
f(x) = ax + b
Where a is the slope and b the intercept. In practice, for output layers in regression, the most common case is a = 1, b = 0, simplifying to the identity function: f(x) = x — the neuron simply passes its weighted sum without transformation.
The mathematical properties of the linear function are:
- Domain: all reals (−∞, +∞).
- Range: all reals (−∞, +∞) — no saturation, which is advantageous for regression.
- Derivative: constant (f’(x) = a), meaning the gradient does not vanish when propagating backwards.
- Continuity: continuous and differentiable at all points.

Why the linear function fails in hidden layers
This is the critical limitation every neural network practitioner must internalise: if all layers of a network use linear activation functions, the entire network is equivalent to a single linear layer.
The proof is direct. If layer 1 computes h₁ = W₁x and layer 2 computes h₂ = W₂h₁, then:
h2 = W2(W1x) = (W2W1)x = W′x
The composition of two linear transformations is still a linear transformation — matrix multiplication. Adding more linear layers adds no expressive capacity. Therefore, a deep network with linear activations has exactly the same expressiveness as simple linear regression.
This is precisely why functions like ReLU, tanh, and sigmoid exist: they introduce the non-linearity that allows the network to learn complex representations in successive layers.
When to use the linear function correctly
The linear function does have a well-defined place:
Output layer in regression. When the goal is to predict an unconstrained continuous value (house price, temperature, speed), the output layer must use the identity function. Applying sigmoid or ReLU would truncate the range of possible values.
Input normalisation. At the input layer, a linear transformation is sometimes applied to scale data to a standard range (min-max normalisation or Z-score standardisation). This is a preprocessing operation, not an activation function in the strict sense.
Autoencoder bottleneck layers. In some encoder-decoder architectures, the bottleneck layer can be linear to produce a compact, unbounded representation.
The relationship with ReLU and the activation universe
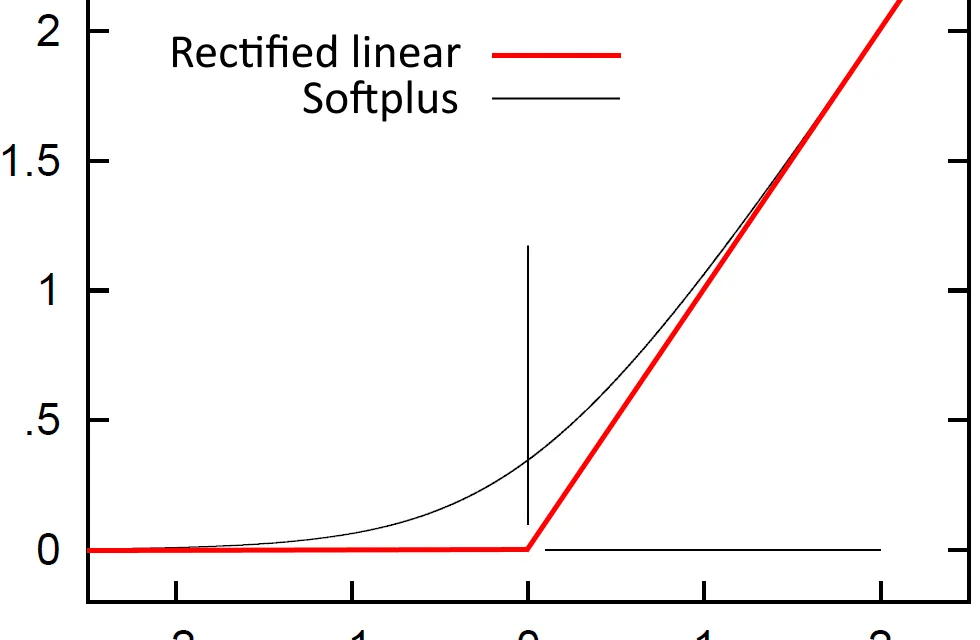
ReLU (Rectified Linear Unit) is, in a sense, an extension of the linear function:
ReLU(x) = max (0, x)
It is linear for x > 0 and constant (0) for x ≤ 0. This linear piece is what gives ReLU its computational efficiency and resistance to the vanishing gradient, while the discontinuity at x = 0 introduces the necessary non-linearity. See the full comparison in mathematical formulation of neural network input.
For the output layer in multi-class classification, the alternative is the Softmax function, which converts a vector of arbitrary outputs into a probability distribution.
Sensitivity to outliers
A practical limitation of the linear function in the regression output layer is its sensitivity to outliers. Without saturation, extreme values in training data disproportionately affect the MSE loss function slope, biasing the model. Standard mitigations are:
- Using MAE (Mean Absolute Error) or Huber loss instead of MSE — less sensitive to outliers.
- Normalising outputs before training and denormalising predictions when interpreting them.
- Removing or bounding outliers in preprocessing when they originate from measurement errors.
For a broader context on how these functions fit into full network design, see neural networks and deep learning. If using networks in production, initial benchmarking with LazyPredict helps confirm whether a neural network beats linear alternatives before investing in architecture design.
Conclusion
The linear function occupies a precise and irreplaceable place in neural networks: the output layer for regression. Outside that role, using linear activations in hidden layers eliminates the computational benefit of stacking layers. Knowing its mathematical limitations — especially the equivalence of linear compositions to a single layer — is the first step toward understanding why non-linear activation functions are the true heart of any useful neural network.




