Neural Networks and Deep Learning: Advances in Artificial Intelligence
Actualizado: 2026-05-03
Artificial neural networks and deep learning are the technologies that have most transformed artificial intelligence over the last decade. From facial recognition to machine translation, almost every modern AI application rests on a deep neural network architecture. This article explains how these architectures work, what sets them apart from classical methods, and in which fields they have produced measurable advances.
Key takeaways
- A deep neural network chains multiple layers of non-linear transformations learned from data.
- Deep learning outperforms classical methods when data is abundant and useful representations are hard to define by hand.
- The most mature applications are in computer vision, speech recognition, and natural language processing.
- Efficient training requires large volumes of labelled data, acceleration hardware (GPU/TPU), and regularisation techniques.
- Real limitations include interpretability opacity, energy cost, and fragility against adversarial examples.
What a neural network is and why “deep” matters
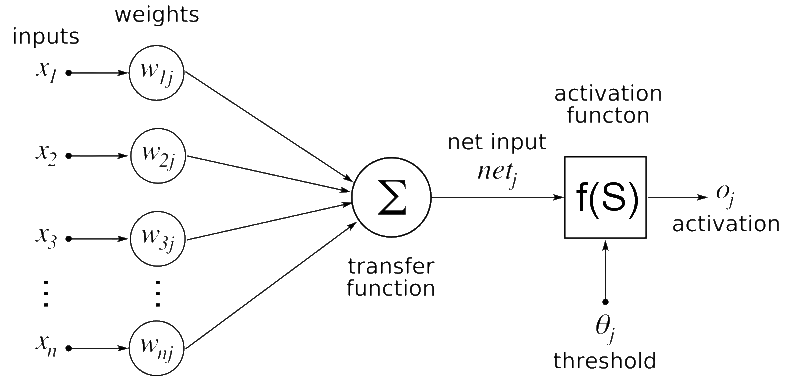
An artificial neural network is made up of layers of computing units (neurons) connected to each other. Each neuron applies a transformation to its weighted inputs and passes the result to the next layer. The depth of the network — the number of layers — is precisely what distinguishes deep learning from classical machine learning.
In a shallow network (1-2 hidden layers), the capacity to learn hierarchical representations is limited. With dozens or hundreds of layers, the network can learn low-level features (edges in an image, phonemes in audio) and progressively combine them into high-level concepts (faces, words, sentiments). This hierarchical composition is what makes deep learning especially powerful for unstructured data.

The most relevant architectures are:
- Convolutional networks (CNN) — specialised for image and video processing.
- Recurrent networks (RNN/LSTM) — designed for temporal sequences and text.
- Transformers — the architecture dominating natural language processing since 2017.
- Generative adversarial networks (GAN) — two competing networks that generate realistic synthetic data.
Practical applications with measurable results
Deep learning’s most significant advances have occurred in three domains:
Computer vision. CNN-based models surpass humans on standard image classification benchmarks. Applications range from object detection in autonomous vehicles to disease diagnosis in medical imaging. In dermatology, models trained on millions of images reach precision comparable to specialists in melanoma detection.
Natural language processing. Transformer models (BERT, GPT, T5) have redefined the state of the art in machine translation, text summarisation, sentiment classification, and language generation. This line underpins the NLP advances that enabled systems like ChatGPT.
Speech recognition. Word-error rates for English speech recognition have fallen below 5 % with recurrent and transformer architectures — competitive with human transcription under clean recording conditions.

Training: where the real cost lies
Training a deep neural network means solving an optimisation problem in a space of millions or billions of parameters. The standard process is stochastic gradient descent with backpropagation: the output error is propagated backwards layer by layer to adjust weights in the direction that reduces it. The cycle repeats over mini-batches of data for hundreds or thousands of epochs.
The factors that determine training cost and quality are:
- Labelled data volume — deep learning is data-hungry; few samples lead to overfitting.
- Architecture and depth — more layers allow greater expressive capacity but increase the risk of vanishing or exploding gradients.
- Regularisation — techniques like dropout, batch normalisation, and data augmentation reduce overfitting.
- Acceleration hardware — GPUs and TPUs parallelise the matrix calculations that dominate training; without them, a large model would take weeks to train.
The connection to federated learning emerges here: when data is distributed and cannot be centralised for privacy reasons, federated training lets gradients travel without exposing raw data.
Limitations to understand
Deep learning is not a silver bullet. Four real limitations:
- Interpretability opacity. The decisions of a deep network are hard to explain. The explainable AI (XAI) field works precisely on this problem.
- Adversarial fragility. Small imperceptible perturbations to the input can drastically change the model’s output. Adversarial machine learning studies both the attacks and the defences.
- Energy cost. Training large language models consumes hundreds of megawatt-hours; inference at scale is also expensive.
- Labelled data dependency. Few-shot and transfer learning approaches mitigate but do not eliminate this problem.
Conclusion
Deep learning has displaced classical methods in any domain with abundant data and complex structure: images, audio, text. Its impact has been so broad that talking about artificial intelligence today implicitly means talking about neural networks. However, understanding its costs, limits, and the regularisation techniques it requires is just as important as mastering the architecture — building models that work in production demands both.




