LiteLLM: A Proxy to Unify Model Providers
Updated: 2026-07-07
The first integration with an LLM is always easy: one key, one SDK, three lines and a prompt. The second, six months later, is no longer so. A second provider appears because Claude reasons better on long tasks, or because a self-hosted model is needed for data that cannot leave the perimeter, or because Cohere multilingual embeddings cost a fraction of OpenAI’s equivalent. At that point application code stops being clean. Each SDK has its own client, message format, streaming semantics, errors, and function-calling rules. The team starts writing adapters, and every cross-cutting requirement (rate limiting, observability, per-tenant budget, fallback when a provider is down) has to be implemented twice or three times over.
The pattern that solves this is old and familiar in infrastructure: a proxy. Instead of each application talking directly to each provider, they all talk to a single internal service. LiteLLM[1] is, as of early 2024, the most serious open-source project for doing this in the LLM space. It offers an OpenAI-compatible API over more than a hundred providers, deploys as a library or HTTP server, and comes with most of what you would eventually write yourself.
Key Takeaways
-
An LLM proxy is not a revolutionary idea. It is the same indirection layer already placed between applications and databases, queues, and identity.
-
The four reasons that justify a proxy are: API homogeneity, governance (virtual keys + budgets), resilience (automatic fallbacks), and centralised observability.
-
Server mode is what matters for serious use: library mode loses almost all cross-cutting benefits.
-
Translation between APIs is not always perfect: the most provider-specific features (structured output, tool use) sometimes do not map 1:1.
-
With a single provider and no plan to change, the complexity does not pay; a local abstraction is enough.
Why Proxy at All
The justification must be concrete, because any proxy adds latency and another component to maintain. There are four reasons, and they usually arrive together.
The first is homogeneity. A single OpenAI-compatible client across all applications, pointing at an internal endpoint, replaces half a dozen SDKs. Switching models becomes a configuration field, not a refactor.
The second is governance. Once more than one team uses LLMs, someone asks how much each is spending, and wants to cap it. A central proxy issues virtual keys per team, user, or service, with budget and expiry. Real provider keys live in exactly one place.
The third is resilience. LLM providers fail, rate-limit, and degrade responses more often than expected. A proxy can declare fallbacks (if GPT-4 returns 429 or 5xx, it retries with Claude 3 Sonnet) without the applications noticing. This turns provider incidents into silent degradations rather than product outages.
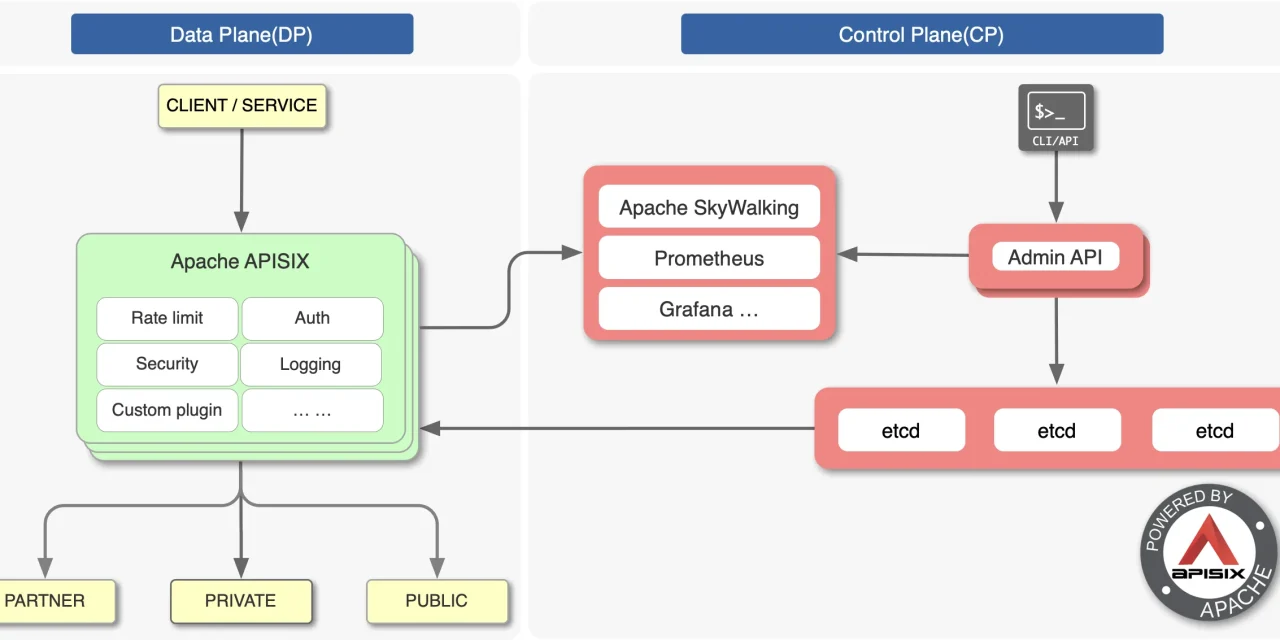
The fourth is observability. Cost, latency, and token metrics by model, tenant, and route, emitted from one point to Prometheus or Langfuse, avoid instrumenting every call in every application. Also the natural place for caching, PII redaction, auditing, and compliance.
Library or Server
LiteLLM has two modes. Library mode: import litellm.completion inside application code, no new deployment needed. Reasonable for monoliths, prototypes, one-off scripts, but loses almost all cross-cutting benefits.
Proxy mode: deploy a separate binary (container, pod, systemd unit) and applications talk to it as if it were OpenAI. This is the configuration for any serious use. Cost is an internal network hop of 5-20 ms, negligible versus the hundreds or thousands of milliseconds of an actual LLM call.
What the Proxy Declares
Minimal working configuration:
model_list:
- model_name: gpt-4
litellm_params:
model: openai/gpt-4
api_key: os.environ/OPENAI_API_KEY
- model_name: claude-3-sonnet
litellm_params:
model: anthropic/claude-3-sonnet-20240229
api_key: os.environ/ANTHROPIC_API_KEY
router_settings:
fallbacks:
- gpt-4: ["claude-3-sonnet"]
routing_strategy: least-busy
general_settings:
master_key: os.environ/LITELLM_MASTER_KEY
database_url: os.environ/DATABASE_URLmodel_list maps logical names to provider configurations. router_settings declares routing policy and fallbacks. general_settings sets the master key, points at Postgres for persisting budgets and usage, and optionally wires Redis for semantic cache. The rest of the surface (per-key budgets, caching with TTL, Langfuse or Helicone integration, Prometheus metrics) is described in the same file without touching application code.
What Not to Expect
LiteLLM translates between different APIs, and translation is not always perfect. Provider-specific features (structured output with complex schemas, OpenAI function calling vs Anthropic tool use, reasoning modes) sometimes do not map 1:1. Added latency is small but not zero, and can be more noticeable than expected for high-volume embedding workloads. The proxy itself is another piece to maintain. And if real usage is a single provider with no plan to change, the complexity does not pay: a local abstraction layer in the backend is enough.
A pattern that works
The deployment that stabilises in teams with serious use is always similar: two proxy replicas behind an internal service, shared Postgres for keys and usage, Redis for semantic cache, virtual keys per team or service with monthly budget, fallbacks declared for the critical models, Prometheus scrape with model, tenant, and route labels, and alerts on per-provider error rate. Applications see a single OpenAI-compatible endpoint and send their virtual key in a header; everything else happens inside the proxy.
Conclusion
An LLM proxy is not a revolutionary idea. It is the same indirection layer already placed between applications and databases, queues, and identity. It earns its place for the same reasons: isolates frequently-changing decisions, concentrates governance and observability, and lets the application ignore provider details. LiteLLM is the most complete open-source implementation, stable enough for production and flexible enough to absorb the changes that will keep arriving in the model stack. With a single provider and no foreseeable second, the component is dispensable. From the second model onwards, giving up on hand-written adapters and delegating to a proxy stops being a matter of taste and becomes basic hygiene.



