Hybrid RAG in 2026: the patterns that keep winning
Tres años después del boom inicial, el RAG en producción ha convergido en patrones híbridos que combinan búsqueda densa, léxica y reranking. Estos son los que sobreviven al paso del tiempo.
Tag
Tres años después del boom inicial, el RAG en producción ha convergido en patrones híbridos que combinan búsqueda densa, léxica y reranking. Estos son los que sobreviven al paso del tiempo.
Redis 8.2 incorpora búsqueda vectorial como tipo de dato nativo. La pregunta no es si funciona, sino si sustituye a un motor dedicado como Qdrant, Weaviate o pgvector en cargas reales con millones de vectores y latencias exigentes.
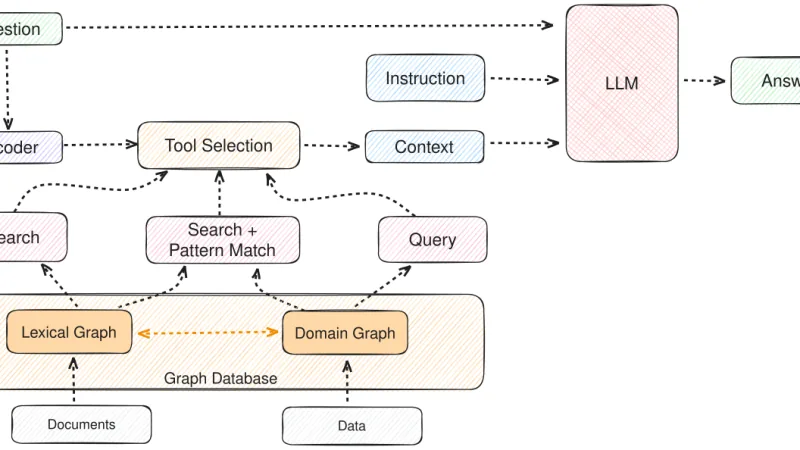
El RAG de 2023 era búsqueda vectorial con un LLM detrás. El de 2025 es un sistema híbrido que combina vectores, búsqueda léxica y grafos de conocimiento. Qué ha cambiado, dónde funciona cada pieza y qué decisiones marcan la diferencia entre un RAG útil y uno decepcionante.
Nomic liberó un modelo de embeddings con pesos, datos y código abiertos que rivaliza con text-embedding-3-small de OpenAI. Por qué importa y dónde encaja.
OpenAI liberó text-embedding-3 con calidad superior y dimensiones variables. Cómo aprovechar lo nuevo sin rehacer toda la pila RAG ni presupuestar mal el reindexado.
pgvector maduró en 2023-2024 con HNSW y construcción paralela. Cuándo PostgreSQL basta para RAG, cómo indexar bien y dónde empieza a sufrir.
Cohere Embed v3 añadió señales de calidad de documento y mantuvo su foco multilingüe. Cómo compara con OpenAI y cuándo encaja mejor en un pipeline RAG.
Las bases vectoriales han pasado de ser experimentales a base de productos LLM. Comparativa pragmática entre las tres opciones más usadas en 2023.
pgvector convierte PostgreSQL en una base vectorial competente. Por qué la búsqueda semántica necesita índices especializados y cuándo basta con extender Postgres.
Los embeddings convierten texto en vectores con significado semántico. Cómo se generan, qué modelos elegir y para qué casos sirven realmente.
Chroma es la opción más simple para empezar con embeddings y búsqueda semántica. Cuándo brilla, cuándo se queda corta y cómo desplegarla.
Qdrant, Pinecone y Weaviate comparados en búsqueda semántica, escalabilidad y modelo de despliegue. Cuál elegir según tu caso de uso.