NVIDIA alternatives in 2026: where the market is heading
NVIDIA domina el entrenamiento de IA, pero la inferencia tiene cada vez más alternativas viables. Este es el mapa del ecosistema en 2026.
Tag
NVIDIA domina el entrenamiento de IA, pero la inferencia tiene cada vez más alternativas viables. Este es el mapa del ecosistema en 2026.
Las NPU dejaron de ser un accesorio para convertirse en el componente que define rendimiento real en portátiles, teléfonos y servidores pequeños. Repaso práctico del hardware que domina 2026, qué cargas compensan y dónde sigue ganando la GPU tradicional.
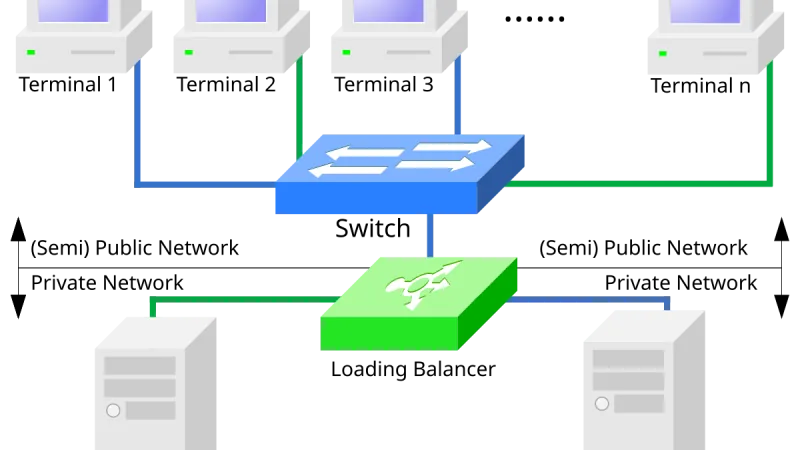
Un enrutador de inferencia decide qué modelo atiende cada petición en función de coste, latencia y complejidad. Bien diseñados reducen la factura de tokens sin que el usuario perciba degradación; mal diseñados introducen fallos sutiles difíciles de depurar.
TypeScript 5.5 llegó con inferencia de predicados, tipos de expresiones regulares estrictos y mejoras de declaraciones aisladas. Un año de uso real para separar lo que cambia el código diario de lo que es novedad cosmética, y cuándo conviene actualizar.
vLLM se ha consolidado como el motor de serving de LLM más adoptado en producción. Repaso de las mejoras recientes, qué cambia para quien lo opera y qué sigue siendo punto débil.
Un modelo, muchos destinos. ONNX Runtime resuelve la fragmentación de runtimes ML a costa de ceder algo de techo en cada plataforma concreta.
Text Generation Inference es la pila de servicio de Hugging Face para LLM abiertos. Cuándo tiene sentido, qué optimizaciones aporta gratis y sus límites reales.