Kubernetes 1.35 GA consolida tres versiones de trabajo: sidecars nativos con ciclo de vida completo, DRA generalizada para FPGAs y NPUs, y un scheduler que reduce el desperdicio un 15-25 % en clusters heterogéneos. Balance desde la operación diaria: qué activar ya, qué vigilar antes de migrar y qué plan seguir si vienes de 1.30.
Después de catorce meses probando herramientas DevOps con IA integrada en varios equipos, el stack que se queda es reducido: Claude Code, Cursor y Aider para código; PagerDuty AIOps, Datadog Bits AI y Grafana Assistant para triage de alertas; y OpenTofu con OPA para generar infraestructura acotada por reglas de política.
Los agentes de IA fallan en producción: lo que importa es cómo respondes en los primeros veinte minutos. Este runbook cubre clasificación de severidad, aislar antes de investigar, purgar memoria contaminada, comunicar sin inventar datos y convertir cada incidente en una prueba de regresión antes de darlo por cerrado.
Los cuadros de mando con IA llevan un par de años prometiendo detección de anomalías mágica y causa raíz automática. La realidad es más modesta pero también más útil, si se sabe separar el ruido del valor real. Repaso honesto de qué funciona y qué no.
Han pasado siete años desde que Google publicó el Workbook, y buena parte del libro no ha envejecido. Repaso los patrones que de verdad aplicamos en equipos pequeños y los que resultaron ser cultura de campus.
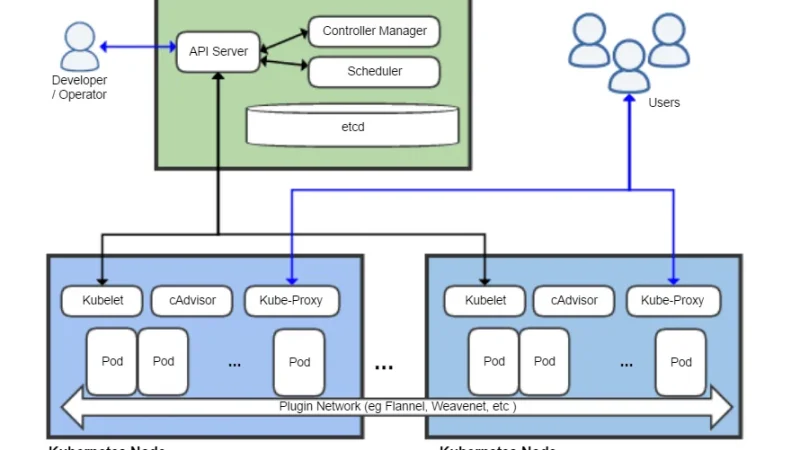
Kubernetes 1.32 Penelope se publicó en diciembre y lleva varios meses rodando en clusters. Es buen momento para mirar qué cambios han envejecido bien, cuáles han generado trabajo extra y qué aprendizajes llevarse al salto hacia 1.33.
La release 1.33 llega el 23 de abril con el nombre Octarine, y el sneak peek oficial de marzo ya deja ver las líneas fuertes: in-place pod resize pasa a beta con el gate activado por defecto, los sidecar containers alcanzan por fin GA, y llegan varias deprecaciones de seguridad y de la API de endpoints que conviene revisar antes del upgrade.
Chaos engineering es la práctica de inyectar fallos reales en producción de forma controlada para verificar que el sistema responde como se espera. Requiere hipótesis previas, blast radius mínimo y observabilidad madura. Herramientas open-source como Litmus y Chaos Mesh permiten adoptar la disciplina sin coste comercial; el ROI llega en forma de incidentes evitados y equipos mejor preparados.
Los SLOs y error budgets solo funcionan cuando el budget informa decisiones reales. Un feature freeze que se dispara al agotarse el presupuesto, una velocidad de despliegue que se ajusta al consumo. Con dos o tres SLIs bien elegidos, una policy de freeze clara y herramientas como Prometheus con Sloth, un equipo consigue equilibrar velocidad y fiabilidad de forma sostenible.
Los post-mortems blameless son fáciles de proclamar pero difíciles de ejecutar bien. Sin una cultura genuinamente sin culpas, un timeline factual, un análisis honesto de los factores contribuyentes y action items con responsable y plazo, el ejercicio degenera en un ritual vacío que no previene la repetición de incidentes.
El libro de SRE de Google (2016) es lectura canónica, pero está escrito para miles de ingenieros y datacenters propios: aplicarlo literal en un equipo pequeño produce fricción. Cinco principios sí se trasladan (SLO, error budget, postmortem sin culpa, toil management, on-call humano); lo que no escala es la infraestructura y los roles dedicados de Google.
La Directiva NIS2 amplía la ciberseguridad europea de 7 a 18 sectores, exige 10 medidas técnicas mínimas y notificación de incidentes en 24 horas, e impone sanciones de hasta 10 millones de euros o el 2% de la facturación global, con responsabilidad personal para los órganos directivos que incumplan.
Para escribir alertas de Prometheus que no acaben ignoradas, alerta sobre síntomas observables por el cliente (latencia, error rate, saturación) en vez de causas internas como CPU o memoria, define SLOs con burn rate multi-ventana para dosificar la gravedad, añade una alerta watchdog que confirme que el sistema sigue vivo y revisa el ratio señal/ruido cada trimestre.
Pixie usa eBPF para instrumentar automáticamente clústeres de Kubernetes sin modificar el código de la aplicación. Un agente por nodo captura tráfico HTTP, gRPC, SQL y Redis a nivel de kernel y expone en minutos mapa de servicios, perfiles de CPU y trazas SQL. Complementa a Prometheus para diagnóstico reactivo sin sidecars ni redeploys.
5 min314
Usamos cookies propias y de terceros para analizar el tráfico del sitio. Puedes aceptarlas, rechazarlas o configurar tu elección.
Más información sobre las cookies
Preferencias de cookies
NecesariasImprescindibles para el funcionamiento del sitio. Siempre activas.
AnalíticasNos ayudan a entender cómo se usa el sitio (Google Analytics).