La Función Sigmoide: Una Herramienta Clave en Redes Neuronales
Actualizado: 2026-06-20
La función sigmoide transforma cualquier valor real en un número entre 0 y 1, convirtiéndose en la herramienta natural para expresar probabilidades dentro de una red neuronal. Su característica forma de «S» la ha hecho protagonista en clasificación binaria durante décadas.
Puntos clave
- La sigmoide comprime la salida en (0, 1), ideal para interpretar resultados como probabilidades.
- Es diferenciable en todos los puntos, lo que permite usarla con backpropagation.
- Sufre de saturación y desvanecimiento del gradiente en entradas extremas.
- Sigue siendo la función estándar en la capa de salida para clasificación binaria.
- ReLU y tanh la han sustituido en capas ocultas profundas.
Definición y fórmula
La función sigmoide — también llamada función logística — se define como:
f(x) = 1 / (1 + e⁻ˣ)
donde e es la constante de Euler (~2.718). Sus propiedades fundamentales:
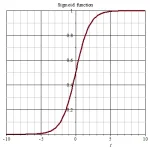
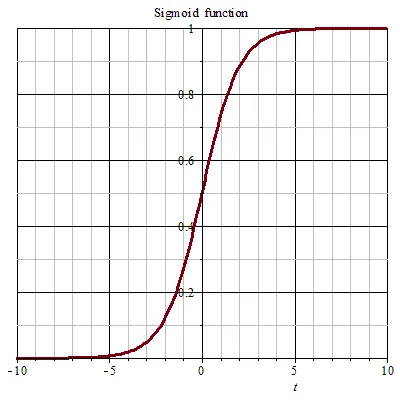
- Cuando x → +∞, f(x) → 1.
- Cuando x → −∞, f(x) → 0.
- En x = 0, f(0) = 0.5.

Curva logística sigmoide mostrando la forma de S característica entre 0 y 1
La suavidad de esta curva es clave: la derivada de la sigmoide existe en todos los puntos, lo que permite calcular gradientes y ajustar los pesos de la red durante el entrenamiento.
Implementación en redes neuronales
En una red neuronal, la sigmoide se aplica a la suma ponderada de las entradas de cada neurona:
- Se calcula z = w₁x₁ + w₂x₂ + … + b (suma ponderada + sesgo).
- Se aplica la sigmoide: a = σ(z).
- La salida a alimenta la siguiente capa o es la predicción final.
Durante el entrenamiento, la sigmoide participa en el cálculo del gradiente. Su derivada es σ’(x) = σ(x)(1 − σ(x)), una expresión elegante que se calcula directamente a partir de la salida ya computada, sin evaluar la función otra vez.

Representación simbólica de una neurona con función de activación sigmoide
Ventajas y desventajas
Ventajas:
- Salida interpretable como probabilidad entre 0 y 1.
- Diferenciable en todos los puntos: compatible con backpropagation.
- Monótona creciente: relaciones de orden preservadas.
Desventajas:
- Saturación: para |x| > 5, la función se aplana y el gradiente se acerca a cero.
- Desvanecimiento del gradiente: en redes profundas, los gradientes se multiplican capa a capa y se extinguen antes de llegar a las primeras capas.
- Salida no centrada en cero: todas las salidas son positivas, lo que puede ralentizar la convergencia.
Estos problemas son los que motivaron el desarrollo de ReLU para capas ocultas y de la función escalón para el análisis conceptual de activaciones binarias.
Casos de uso prácticos
La sigmoide sigue siendo la elección preferida en escenarios concretos:
- Clasificación binaria en capa de salida: ¿un paciente tiene riesgo cardíaco elevado? ¿un correo es spam?
- Modelado de probabilidades: predicción de conversión en campañas de marketing, scoring crediticio.
- Puertas en arquitecturas LSTM: las celdas de memoria usan sigmoide para controlar qué información retener o descartar.
- Regresión logística: la sigmoide es el núcleo matemático de uno de los modelos estadísticos más utilizados en la industria.
Un ejemplo aplicado: en sistemas de análisis de imágenes, la capa de salida de un clasificador binario (¿contiene este radiografía una lesión?) casi siempre usa sigmoide. Para clasificación multiclase, la alternativa es softmax.
La sigmoide también aparece en el contexto del aprendizaje por refuerzo, donde las políticas estocásticas a veces producen probabilidades de acción mediante esta función. Y en modelos pre-entrenados de lenguaje, las cabeceras de clasificación heredan este patrón.
Conclusión
La función sigmoide sigue siendo insustituible en la capa de salida de cualquier clasificador binario que necesite producir una probabilidad interpretable. Sus limitaciones en capas profundas son reales, pero bien comprendidas: usarla donde corresponde y delegar en ReLU o tanh donde no es su territorio es la clave de un diseño de red neuronal sólido.



