La Tangente Hiperbólica: Función de Activación Potente
Índice de contenidos
Actualizado: 2026-07-07
La tangente hiperbólica (tanh) resuelve uno de los defectos principales de la sigmoide: la falta de simetría. Al producir salidas centradas en cero entre -1 y 1, facilita la convergencia del entrenamiento y sigue siendo la elección preferida en arquitecturas recurrentes y en contextos donde la salida balanceada importa.
Puntos clave
-
Tanh mapea cualquier valor real al intervalo (-1, 1), con salida centrada en cero.
-
Es matemáticamente una versión reescalada de la función sigmoide: tanh(x) = 2·σ(2x) − 1.
-
La simetría respecto al origen facilita la optimización: las actualizaciones de gradiente son balanceadas.
-
Comparte con sigmoide el problema del desvanecimiento del gradiente en entradas extremas.
-
Es la función de activación estándar en las celdas de memoria LSTM y GRU.
Definición y propiedades
La tangente hiperbólica se define como:
tanh(x) = (eˣ − e⁻ˣ) / (eˣ + e⁻ˣ)
Es la misma definición que recoge la entrada de Wikipedia sobre funciones de activación[1], y coincide con la que usan las bibliotecas de deep learning en producción.
Sus propiedades fundamentales:
-
tanh(0) = 0: la salida está centrada en cero.
-
tanh(x) → 1 cuando x → +∞.
-
tanh(x) → -1 cuando x → -∞.
-
Es impar: tanh(-x) = -tanh(x).
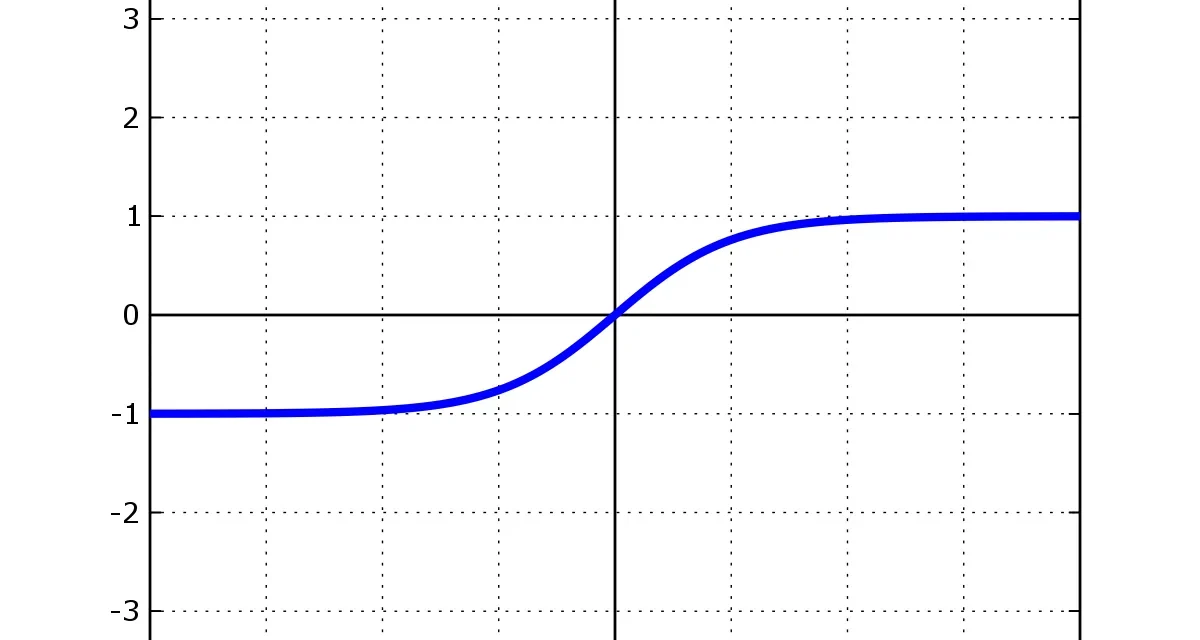
 Gráfica de la función tangente hiperbólica tanh mostrando simetría respecto al origen entre -1 y 1
Gráfica de la función tangente hiperbólica tanh mostrando simetría respecto al origen entre -1 y 1
Esta simetría respecto al origen es la diferencia clave respecto a la sigmoide. Cuando las activaciones están centradas en cero, los gradientes que se propagan hacia atrás no tienen un sesgo sistemático hacia positivo o negativo, lo que acelera la convergencia.
Ventajas sobre la sigmoide
Tanto tanh como sigmoide son suaves, diferenciables en todo su dominio y saturan en los extremos. Pero tanh tiene ventajas claras en capas ocultas:
-
Salida centrada en cero: las capas siguientes reciben activaciones con media aproximada de 0, no de 0.5 como con sigmoide.
-
Gradientes más fuertes: la derivada de tanh en x=0 es 1, frente a 0.25 de la sigmoide. Gradientes más grandes = aprendizaje más rápido en la zona central.
-
Interpretación natural para clasificación: salidas negativas corresponden a una clase, positivas a otra.
La desventaja compartida: el desvanecimiento del gradiente. Para |x| > 2, la derivada de tanh cae rápidamente hacia cero. En redes muy profundas, ReLU o Leaky ReLU son más robustas.
Implementación en redes neuronales
En la práctica, tanh aparece en:
-
Capas ocultas de redes recurrentes (RNN): la actualización del estado oculto usa tanh para comprimir la información al rango (-1, 1).
-
Celdas LSTM: la función de actualización del estado de celda usa tanh, mientras que las puertas usan sigmoide.
-
Celdas GRU: igual que LSTM, combina tanh y sigmoide en sus puertas.
-
Redes de autoencoder: cuando la salida debe estar entre -1 y 1 por simetría del dominio.
La implementación de referencia en PyTorch, documentada en torch.nn.Tanh[2], aplica exactamente esta fórmula sin aproximaciones adicionales.
 Comparativa de funciones de activación incluyendo tanh frente a sigmoide y ReLU
Comparativa de funciones de activación incluyendo tanh frente a sigmoide y ReLU
En el contexto del aprendizaje automático adversarial, las redes generativas suelen usar tanh en la última capa del generador cuando el espacio de salida es (-1, 1), por ejemplo imágenes normalizadas en ese rango. Para el aprendizaje por refuerzo, las redes de política con acciones continuas a veces usan tanh para limitar el rango de salida.
Cuándo elegir tanh frente a otras funciones
La decisión práctica:
-
Capa oculta en red poco profunda: tanh o sigmoide, con ligera preferencia por tanh.
-
Capa oculta en red profunda (>5 capas): ReLU o Leaky ReLU por mayor resistencia al desvanecimiento del gradiente.
-
Celdas recurrentes (LSTM, GRU): tanh es el estándar, bien establecido y estable.
-
Capa de salida para clasificación binaria: sigmoide.
-
Capa de salida para clasificación multiclase: softmax.
Para entender la función escalón como punto de partida histórico y comparar estas funciones en el marco de redes neuronales totalmente conectadas es útil ver cómo cada elección de activación afecta la arquitectura completa. Las notas del curso CS231n de Stanford sobre redes neuronales[3] recogen la misma recomendación práctica: preferir tanh sobre sigmoide en capas ocultas por su salida centrada en cero.
Preguntas frecuentes
¿Por qué tanh converge más rápido que la sigmoide en capas ocultas?
Porque su salida está centrada en cero: los gradientes que se propagan hacia atrás no tienen un sesgo sistemático hacia positivo o negativo, así que las actualizaciones de peso son más balanceadas y el entrenamiento avanza con menos pasos de corrección.
¿Sigue usándose tanh en arquitecturas modernas?
Sí, sobre todo en las puertas internas de LSTM y GRU, donde combina con sigmoide para controlar el flujo de información. En capas ocultas de redes feedforward muy profundas, ReLU y sus variantes la han desplazado por ser más resistentes al desvanecimiento del gradiente.
Conclusión
La tangente hiperbólica es la función de activación preferida para capas recurrentes y para cualquier contexto donde la simetría de la salida importa. Su simetría respecto al origen la hace más estable que la sigmoide en capas ocultas, y su integración en las arquitecturas LSTM y GRU garantiza que seguirá siendo relevante mientras las redes recurrentes tengan un lugar en el repertorio de herramientas de aprendizaje profundo. Para redes muy profundas tipo feedforward, ReLU sigue siendo la opción más eficiente; para recurrentes y autoencoders, tanh es difícil de superar.
Este artículo también está disponible en inglés: The Hyperbolic Tangent: A Powerful Activation Function.



