Redes neuronales y deep learning: Avances en inteligencia artificial
Actualizado: 2026-06-20
Las redes neuronales artificiales y el deep learning son las tecnologías que más han transformado la inteligencia artificial en la última década. Desde el reconocimiento facial hasta la traducción automática de idiomas, casi toda aplicación de IA moderna descansa sobre una arquitectura de red neuronal profunda. Este artículo explica cómo funcionan estas arquitecturas, qué las diferencia de los métodos clásicos y en qué campos concretos han producido avances medibles.
Puntos clave
- Una red neuronal profunda encadena múltiples capas de transformaciones no lineales aprendidas a partir de datos.
- El deep learning supera a los métodos clásicos cuando los datos son abundantes y las representaciones útiles son difíciles de definir a mano.
- Las aplicaciones más maduras están en visión computarizada, reconocimiento de voz y procesamiento del lenguaje natural.
- El entrenamiento eficiente requiere grandes volúmenes de datos etiquetados, hardware de aceleración (GPU/TPU) y técnicas de regularización.
- Las limitaciones reales incluyen opacidad interpretativa, coste energético y fragilidad frente a ejemplos adversariales.
Qué es una red neuronal y por qué el “deep” importa
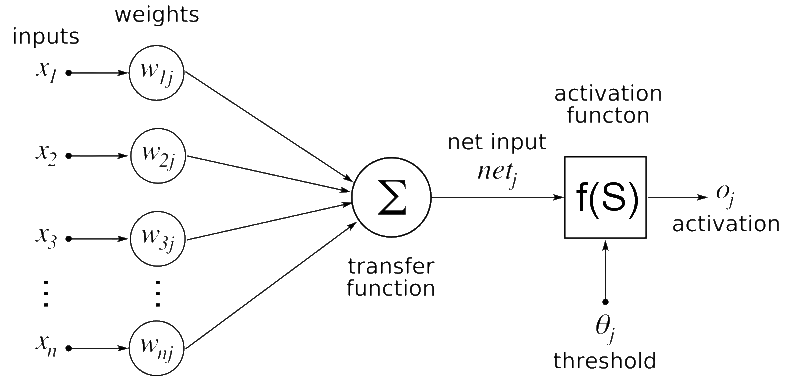
Una red neuronal artificial está formada por capas de unidades de cómputo (neuronas) conectadas entre sí. Cada neurona aplica una transformación al conjunto de sus entradas ponderadas y pasa el resultado a la capa siguiente. La profundidad de la red —el número de capas— es precisamente lo que distingue el deep learning del aprendizaje automático clásico.
En una red poco profunda (1-2 capas ocultas), la capacidad para aprender representaciones jerárquicas es limitada. Con docenas o centenares de capas, la red puede aprender características de bajo nivel (bordes en una imagen, fonemas en audio) y combinarlas progresivamente en conceptos de alto nivel (caras, palabras, sentimientos). Este proceso de composición jerárquica es lo que hace al deep learning especialmente potente para datos no estructurados.

Las arquitecturas más relevantes son:
- Redes convolucionales (CNN) — especializadas en procesamiento de imágenes y video.
- Redes recurrentes (RNN/LSTM) — diseñadas para secuencias temporales y texto.
- Transformers — arquitectura que domina el procesamiento del lenguaje natural desde 2017.
- Redes generativas adversariales (GAN) — dos redes en competición para generar datos sintéticos realistas.
Aplicaciones prácticas con resultados medibles
Los avances más significativos del deep learning se han producido en tres dominios:
Visión computarizada. Los modelos basados en CNN superan a los humanos en tareas de clasificación de imágenes estándar. Las aplicaciones van desde la detección de objetos en vehículos autónomos hasta el diagnóstico de enfermedades en imágenes médicas. En dermatología, modelos entrenados sobre millones de imágenes alcanzan precisiones comparables a las de especialistas en la detección de melanomas.
Procesamiento del lenguaje natural. Los modelos de tipo transformer (BERT, GPT, T5) han redefinido el estado del arte en traducción automática, resumen de texto, clasificación de sentimientos y generación de lenguaje. Esta línea es la base de los avances en NLP que han permitido sistemas como ChatGPT.
Reconocimiento de voz. La tasa de error en reconocimiento de habla en inglés ha caído por debajo del 5 % con arquitecturas recurrentes y transformers, nivel competitivo con la transcripción humana en condiciones de grabación limpias.

Entrenamiento: dónde está el coste real
Entrenar una red neuronal profunda requiere resolver un problema de optimización en un espacio de millones o miles de millones de parámetros. El proceso estándar es el descenso por gradiente estocástico con retropropagación: el error de salida se propaga hacia atrás capa a capa para ajustar los pesos en la dirección que lo reduce. El ciclo se repite sobre minilotes de datos durante centenares o miles de épocas.
Los factores que determinan el coste y la calidad del entrenamiento son:
- Volumen de datos etiquetados — el deep learning es data-hungry; pocas muestras conducen a sobreajuste.
- Arquitectura y profundidad — más capas permiten mayor capacidad expresiva, pero aumentan el riesgo de gradientes que se desvanecen o explotan.
- Regularización — técnicas como dropout, batch normalization y aumento de datos reducen el sobreajuste.
- Hardware de aceleración — las GPU y TPU permiten paralelizar los cálculos matriciales que dominan el entrenamiento; sin ellas, un modelo grande tardaría semanas en entrenar.
La conexión con el aprendizaje federado surge aquí: cuando los datos están distribuidos y no pueden centralizarse por motivos de privacidad, el entrenamiento federado permite que los gradientes viajen sin exponer los datos brutos.
Limitaciones que hay que conocer
El deep learning no es una bala de plata. Cuatro limitaciones reales:
- Opacidad interpretativa. Las decisiones de una red profunda son difíciles de explicar. El campo de la IA explicable (XAI) trabaja precisamente en este problema.
- Fragilidad adversarial. Pequeñas perturbaciones imperceptibles en la entrada pueden cambiar radicalmente la salida del modelo. El aprendizaje de máquina adversarial estudia tanto los ataques como las defensas.
- Coste energético. Entrenar grandes modelos de lenguaje consume cientos de megavatios-hora; la inferencia a escala también es cara.
- Dependencia de datos etiquetados. Los enfoques de pocos ejemplos (few-shot) y aprendizaje por transferencia mitigan este problema, pero no lo eliminan.
Conclusión
El deep learning ha desplazado a los métodos clásicos en cualquier dominio con datos abundantes y estructura compleja: imágenes, audio, texto. Su impacto ha sido tan amplio que hoy resulta difícil hablar de inteligencia artificial sin referirse implícitamente a redes neuronales. Sin embargo, entender sus costes, sus límites y las técnicas de regularización necesarias es tan importante como dominar la arquitectura — construir modelos que funcionen en producción exige las dos partes.



