Herramientas
Ollama en 2024: ejecutar LLM localmente sin dolor
Ollama consolidó como estándar para LLMs locales. Catálogo curado, API compatible con OpenAI, soporte multiplataforma y cuándo usarlo frente a vLLM.
Archivo
Ollama consolidó como estándar para LLMs locales. Catálogo curado, API compatible con OpenAI, soporte multiplataforma y cuándo usarlo frente a vLLM.
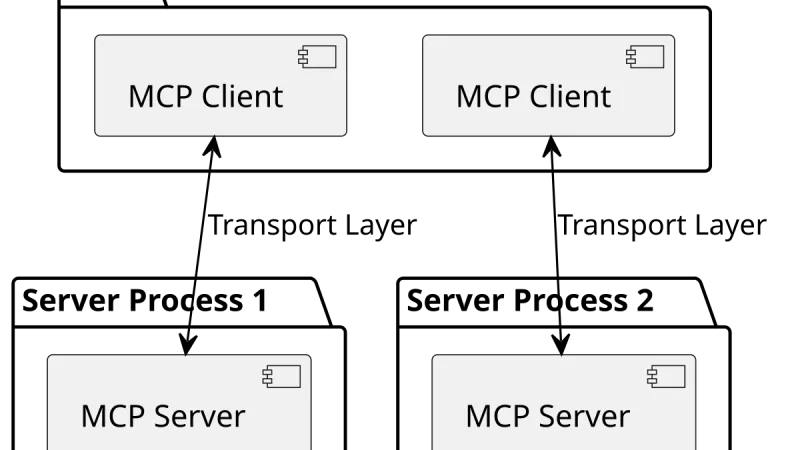
Anthropic presenta MCP, un estándar abierto para conectar modelos de lenguaje con datos y herramientas. Qué resuelve, cómo se diferencia del function calling y por qué puede convertirse en el LSP de los agentes.
Las reglas del product-market fit han cambiado en la era de la IA. Baseline de calidad alto, moats distintos y nuevas métricas. Una guía pragmática para evaluar PMF en productos con LLM.
Profiling 24/7 en todo el clúster sin instrumentar aplicaciones. Parca, Grafana Beyla y Pyroscope conforman el stack moderno de observabilidad de rendimiento.
NIST publicó los primeros estándares PQC en agosto de 2024: ML-KEM, ML-DSA y SLH-DSA. Qué significa para tu stack de seguridad y cómo prepararse para la transición.
MariaDB 11.7 trajo vector search nativo, mejoras en JSON y optimizaciones de rendimiento. Cómo se diferencia de MySQL 8 y cuándo sigue siendo la elección correcta.
Las aplicaciones LLM necesitan observabilidad específica: trazas de prompt/respuesta, costes de tokens y métricas de calidad. Herramientas y patrones para 2024.
Rust 1.75 estabilizó async fn en traits y return-position impl Trait. Rust 1.76 mejoró el debug info y los tipos de puntero. Releases iterativas que acumulan ergonomía real.
TensorRT-LLM es el techo de rendimiento para inferencia LLM en NVIDIA. Complejo de desplegar pero 2-3x más rápido que vLLM en casos óptimos. Cuándo merece la complejidad.
DuckDB es el motor analítico embebido que ha cambiado el panorama. Lee Parquet y CSV directamente, vectoriza la ejecución y cabe dentro de tu proceso Python. Un repaso a cuándo sustituye de verdad a un data warehouse.