Receta probada en mayo de 2026: oMLX 0.3.8 en Mac M5 Max con 128 GB, TurboQuant a 3,5-bit, stack Qwen 3.6 35B-A3B, wiring para Claude Code y benchmarks reales.
La idea de que la UI se genere sobre la marcha en lugar de ser prediseñada llegó a producción en 2025. Tras un año de casos reales, el balance es más matizado que el entusiasmo inicial.
Direct Preference Optimization (DPO) y sus variantes, IPO, KTO y SimPO, han desplazado a RLHF como método preferido para alinear modelos de lenguaje: eliminan el modelo de recompensa separado, reducen el coste de entrenamiento y son más fáciles de reproducir. RLHF conserva ventaja solo en modelos frontera con presupuesto muy grande.
Los datos sintéticos han dejado de ser un sustituto precario de los datos reales para convertirse en un componente central del entrenamiento moderno de modelos: el patrón más fiable amplía un núcleo real de 500 ejemplos con miles de parafraseos sintéticos, siempre que se valide diversidad, corrección y distribución, y se mantenga al menos un 30% de datos reales para evitar el colapso del modelo.
El RAG híbrido en 2026 combina búsqueda densa y léxica fusionadas con RRF, reranking cross-encoder sobre los top-50, chunking consciente de estructura y evaluación continua con Ragas o TruLens. Es el patrón que sobrevive en sistemas serios tres años después del boom inicial de embeddings.
La primera factura de un agente en producción suele doblar o triplicar lo estimado. Este artículo repasa cinco palancas reales y en orden de prioridad, cacheo, routing, control de contexto, batching y telemetría, para recortar el coste sin tocar la calidad percibida.
El red teaming de modelos de lenguaje ha pasado de actividad esotérica a práctica obligatoria. Con OWASP Agentic Top 10 y CSA Agentic AI Red Teaming Guide convergiendo en un vocabulario común, este es el manual operativo que cualquier equipo que despliegue agentes necesita tener.
Prompt engineering ha madurado de trucos virales a disciplina con patrones reproducibles: few-shot, chain-of-thought y salida estructurada con function calling. Los equipos que tratan los prompts como código (versionados, probados y monitorizados) obtienen resultados consistentemente mejores que los que improvisan.
La factura de IA en las empresas ha dejado de ser anecdótica. Entre tokens de modelos frontera, GPUs reservadas que nadie usa y pipelines RAG con cachés mal configuradas, muchos equipos pagan diez veces lo que deberían. Guía de FinOps específico para IA sin relatos promocionales.
Los grafos de conocimiento llevaban dos décadas esperando su momento. Con los LLM como puente entre texto y ontología, y el patrón GraphRAG ya maduro, la tecnología vuelve al primer plano. Toca revisar por qué ahora sí encaja y dónde conviene usarla.
Los modelos grandes de lenguaje llevan dos años prometiendo documentar código, APIs y arquitecturas sin esfuerzo. Después de ver docenas de proyectos intentarlo, hay patrones claros de dónde funciona y dónde acaba siendo una deuda más.
Los frameworks de guardrails prometen filtrar entradas y salidas de modelos de lenguaje para bloquear fugas de datos, contenido dañino o alucinaciones. Tras evaluar cuatro de los más populares en producción, repaso qué hacen realmente, qué coste en latencia y factura añaden y cuándo compensan frente a controles más simples.
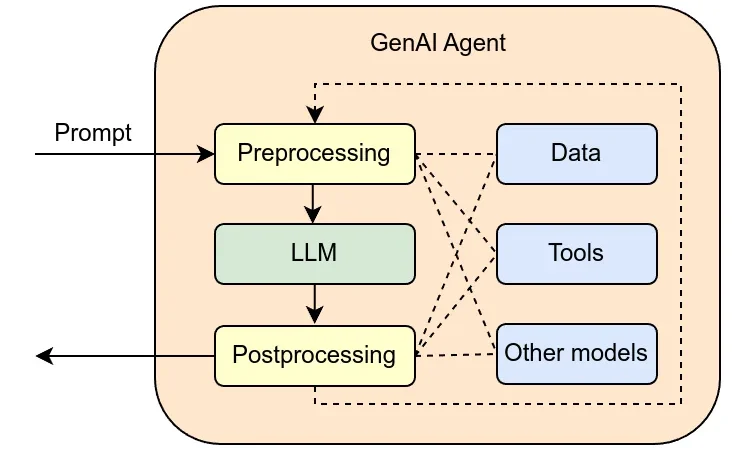
Los agentes que encadenan llamadas a modelos, herramientas y memoria son difíciles de depurar sin una instrumentación pensada para ellos. Después de un año largo operando agentes en producción, repaso qué hay que medir primero, qué estándares están consolidándose y qué errores caros evita tener trazas bien hechas desde el inicio.
Un proxy con caché delante de un modelo de lenguaje puede reducir la factura de tokens de forma significativa, pero introduce riesgos sutiles si el diseño no es cuidadoso. Qué tipos de caché funcionan en producción, dónde están las trampas habituales y cómo integrarlos sin degradar la experiencia.
Un enrutador de inferencia decide qué modelo atiende cada petición en función de coste, latencia y complejidad. Bien diseñados reducen la factura de tokens sin que el usuario perciba degradación; mal diseñados introducen fallos sutiles difíciles de depurar.
Probar sistemas que incluyen modelos de lenguaje rompe la primera regla del testing: la misma entrada da la misma salida. Analizo las estrategias que han funcionado tras un año largo integrando IA en productos reales, por qué los tests deterministas tradicionales no bastan y cómo plantear un cinturón de pruebas que capture regresiones sin bloquearse en la varianza.
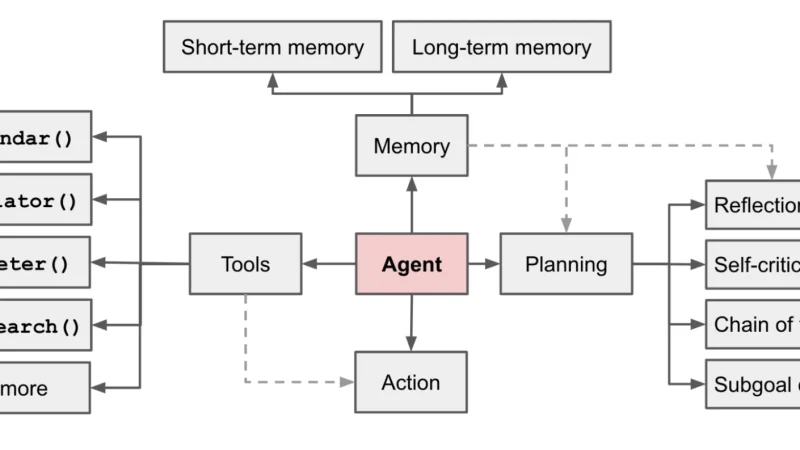
El término Agent OS lleva un año ganando tracción entre investigación y producto. Describe una capa que va más allá de una biblioteca de agentes: planificador, gestión de contexto, memoria persistente y aislamiento. Una lectura del estado real de ese concepto.
Model Context Protocol cumple diez meses desde su anuncio de Anthropic y ya no es una propuesta: hay cientos de servidores, implementaciones cruzadas entre proveedores y un registro público. Repaso de qué ha funcionado, qué sigue flojo y por qué 2025 marca el paso de curiosidad a infraestructura básica.
Tras meses de rumores, OpenAI publicó GPT-5 a principios de agosto. Las primeras semanas de uso real dejan una imagen menos espectacular que el marketing y más útil que lo que muchos esperaban. Vale la pena separar lo nuevo de lo incremental.
Los modelos pequeños de lenguaje se han vuelto útiles de verdad. Phi-3.5, Gemma 2 o Llama 3.2 caben en dispositivos modestos y resuelven tareas acotadas sin salir a la nube. Repaso de dónde encajan en planta y cuándo compensa saltarse el modelo grande.
El RAG de 2023 era búsqueda vectorial con un LLM detrás. El de 2025 es un sistema híbrido que combina vectores, búsqueda léxica y grafos de conocimiento. Qué ha cambiado, dónde funciona cada pieza y qué decisiones marcan la diferencia entre un RAG útil y uno decepcionante.
Google publicó Gemini 2.5 Pro en vista previa en marzo y la versión general llegó en junio. El salto respecto a Gemini 2.0 no está solo en puntuaciones sino en dos frentes prácticos: ventana de contexto utilizable en serio y multimodalidad que deja de ser demostración para convertirse en herramienta.
Anthropic presentó Claude Opus 4 y Claude Sonnet 4 el 22 de mayo de 2025, el primer salto grande de nomenclatura desde la serie 3.5. Un mes de uso real en código, documentación técnica y agentes para separar lo que ha mejorado de lo que sigue igual.
Durante una década, los grafos de conocimiento fueron una idea académica con pocos casos de uso reales, frenada por el coste de construir y mantener el esquema. Los LLM han cambiado esa ecuación: ahora extraen entidades automáticamente y sirven para anclar respuestas, auditar razonamiento y sostener agentes sin alucinar.
Un sistema RAG sin evaluación continua se degrada en silencio. Los índices cambian, los modelos se actualizan, los usuarios preguntan cosas nuevas. Este es un repaso práctico de qué métricas vigilar y cómo montar el cuadro de mando que avisa antes del incidente.
Los agentes de IA han pasado de ser un tema de laboratorio a tener SDKs serios en tres grandes proveedores. Reflexión sobre cómo pasar de la demo llamativa a un caso de uso interno que mueva una métrica real.
Desde que Microsoft abrió GraphRAG, el patrón de usar grafos sobre tus propios datos ha pasado de experimento académico a técnica con aplicaciones prácticas. Reflexión sobre cuándo compensa, cómo se monta y qué errores se repiten.
Anthropic publicó Claude 3.7 Sonnet a finales de febrero con pensamiento extendido opcional y un compañero de consola llamado Claude Code. Reflexión sobre qué cambia de verdad y qué queda para la próxima familia.
vLLM sigue siendo el motor de referencia para servir LLM en GPU en 2025: el prefix caching automático recorta drásticamente la latencia con prompts repetidos, el speculative decoding acelera los modelos grandes y el soporte multi-LoRA abarata el SaaS multi-tenant, aunque el multi-GPU y el hardware no NVIDIA siguen siendo puntos débiles.
GraphRAG lleva más de un año en uso empresarial real: durante la indexación, un LLM construye un grafo de conocimiento que responde bien a preguntas globales sobre un corpus, justo donde el RAG clásico falla porque ningún fragmento aislado contiene la respuesta completa. Aquí comparo costes de indexación, casos donde compensa y el patrón híbrido que se ha impuesto entre equipos.
Tres años después de que RLHF se hiciera popular, el paisaje del alineamiento de modelos es más rico. Repaso de RLHF, DPO y los métodos más recientes como KTO o ORPO, con criterios para elegir.
Google publicó Gemma 2 a mediados de 2024 y ya lleva tiempo en uso real. Balance de cómo compite en el ecosistema de modelos abiertos, qué tamaños tienen sentido y dónde ha cuajado su adopción.
o3-mini, la primera versión pública de la serie de razonamiento o3 de OpenAI, mejora de forma clara la lógica, las matemáticas y el código complejo frente a GPT-4o, aunque tarda más en responder y sigue alucinando datos. Este análisis, basado en semanas de uso real, explica dónde compensa usarlo y dónde no.
Google ha lanzado Gemini 2.0 con un énfasis claro en uso de herramientas y agentes. Repaso de qué aporta, dónde está por detrás de la competencia y en qué tipo de aplicaciones encaja mejor.
Los procesadores Copilot+ de Qualcomm, Intel y AMD han normalizado la presencia de una NPU en el PC doméstico. Una NPU de 40 TOPS puede ejecutar Phi-3 Mini cuantizado consumiendo entre 5 y 10 W, frente a los 40-50 W de una GPU de portátil haciendo la misma tarea. Qué cambia realmente para ejecutar modelos localmente y cuándo merece la pena.
LoRA reduce el coste del fine-tuning de modelos de lenguaje al entrenar solo pequeñas matrices de adaptación de rango bajo, no todos los parámetros del modelo base. QLoRA añade cuantización a 4 bits, lo que recorta la memoria de GPU necesaria entre un 65 % y un 75 %, con una pérdida de calidad de solo 1-3 %.
Claude 3.5 Sonnet (Anthropic, junio de 2024) iguala la calidad de Claude 3 Opus al precio del tier Sonnet, con 200 k tokens de contexto y un 92 % en HumanEval. Destaca especialmente en coding y seguimiento de instrucciones largas, y fue el primer modelo en integrar la función Artifacts en Claude.ai.
Mistral Large 2, lanzado por la startup francesa Mistral AI en julio de 2024, es un modelo de 123.000 millones de parámetros con ventana de contexto de 128k tokens que rivaliza con GPT-4o y Claude 3.5 Sonnet en varios benchmarks. Su residencia de datos en la UE y su precio de 3 EUR por millón de tokens de entrada lo convierten en la alternativa europea más seria frente a los proveedores estadounidenses.
GPT-4 Turbo, lanzado en noviembre de 2023, amplió el contexto de GPT-4 a 128.000 tokens y redujo el precio de entrada 3 veces, hasta 10 dólares por millón de tokens. GPT-4o lo supera en precio, velocidad y calidad de respuesta, pero Turbo sigue siendo válido en apps productivas estables, contratos con versión fija y pruebas deterministas que dependen de su comportamiento concreto.
La decodificación restringida garantiza matemáticamente que la salida de un LLM cumpla el esquema JSON. En cada paso de generación se enmascaran los tokens ilegales y es imposible producir JSON roto. Outlines, Guidance e Instructor son las implementaciones de referencia. Gana a los reintentos en extracción masiva y agentes con tool calling.
Mixtral 8x22B es el modelo Mixture of Experts de Mistral AI liberado en abril de 2024: 141B parámetros totales pero solo 39B activos por token, licencia Apache 2.0 sin restricciones comerciales y rendimiento multilingüe superior a Llama 3 70B en español, francés, italiano y alemán. Requiere GPU de datacenter para servirlo en producción real.
Claude 2, lanzado por Anthropic en julio de 2023, ofrece una ventana de contexto de 100.000 tokens y seguridad basada en Constitutional AI. Frente a GPT-4, gana en analisis de documentos largos y codigo con contexto amplio; GPT-4 sigue adelante en razonamiento matematico complejo y en su ecosistema de herramientas.
LangChain es un framework Python que unifica la construcción de aplicaciones con LLM: prompt templates, retrievers sobre bases vectoriales, agentes con function calling y memoria conversacional. Aporta valor real en prototipos rápidos y sistemas con varios modelos, pero en producción de un caso único bien definido el código directo suele ser más mantenible.
Function calling en OpenAI formaliza la comunicación entre el LLM y el código externo mediante JSON Schema declarativo: el modelo devuelve datos estructurados en lugar de texto libre. Introducido en junio de 2023 con GPT-3.5-turbo y GPT-4, es el estándar para agentes, extracción de datos y APIs conversacionales.
Cinco meses después de su lanzamiento, GPT-4 destaca en razonamiento encadenado, escritura técnica y código de mediana complejidad, pero sigue fallando en aritmética, información posterior a su corte de datos y consistencia entre conversaciones. Claude 2 gana en contexto largo; LLaMA 2, en coste y privacidad.
Google lanzó Bard en febrero de 2023 con PaLM 2 como respuesta a ChatGPT, y presentó el modelo en mayo del mismo año en cuatro tamaños: Gecko, Otter, Bison y Unicorn. PaLM 2 compite con GPT-3.5 y GPT-4 en benchmarks como MMLU y BIG-bench, pero la ventaja real de Google está en la integración con Workspace, no en el modelo en sí.
El fine-tuning de un LLM propio compensa en tres casos: necesitas un estilo o voz muy específicos, un formato de salida rígido y estructurado, o quieres reducir coste y latencia con un modelo pequeño especializado. LoRA y QLoRA han bajado el coste de GPU, pero preparar datos y operar el modelo en producción siguen siendo caros. Para el resto, RAG y prompt engineering bastan.
Cerebras-GPT es una familia de 7 modelos de lenguaje open-source, de 111 millones a 13.000 millones de parámetros, entrenados por Cerebras Systems en sus procesadores CS-2 con arquitectura GPT-3 estándar. Publicados en Hugging Face y GitHub bajo licencia Apache 2.0, sirven para fine-tuning, investigación e inferencia local, aunque solo entienden inglés.
5 min391
Usamos cookies propias y de terceros para analizar el tráfico del sitio. Puedes aceptarlas, rechazarlas o configurar tu elección.
Más información sobre las cookies
Preferencias de cookies
NecesariasImprescindibles para el funcionamiento del sitio. Siempre activas.
AnalíticasNos ayudan a entender cómo se usa el sitio (Google Analytics).