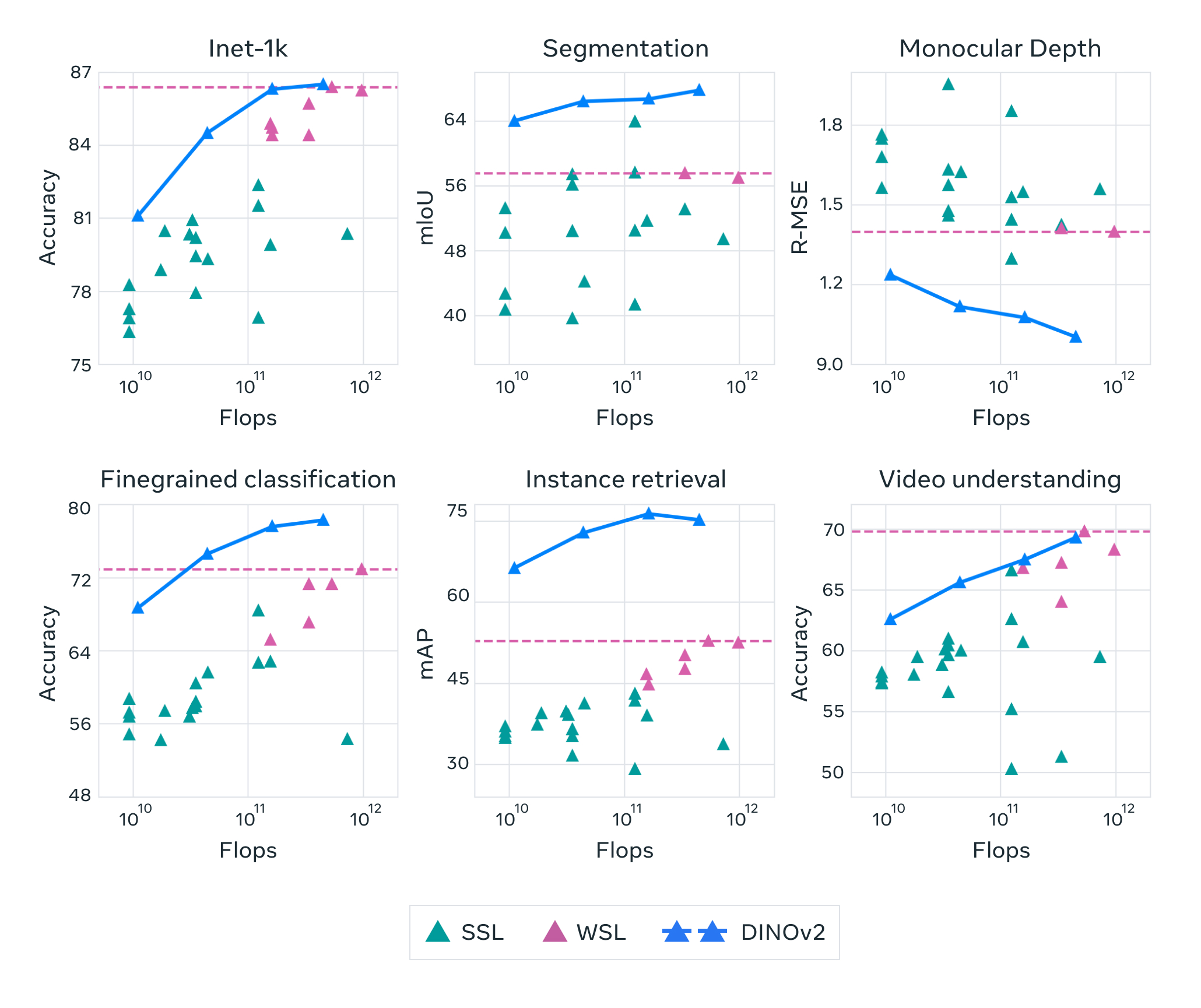
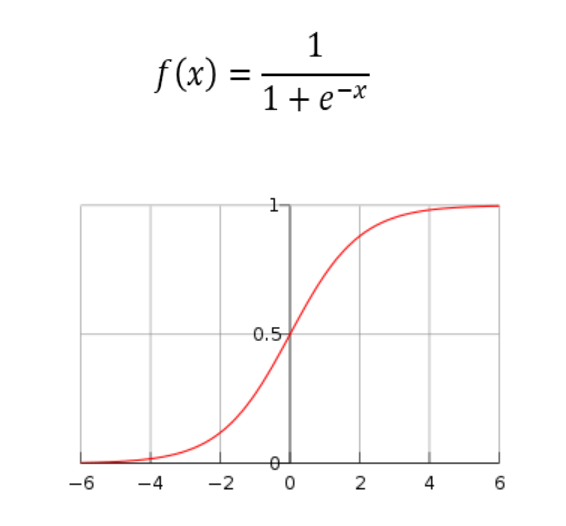
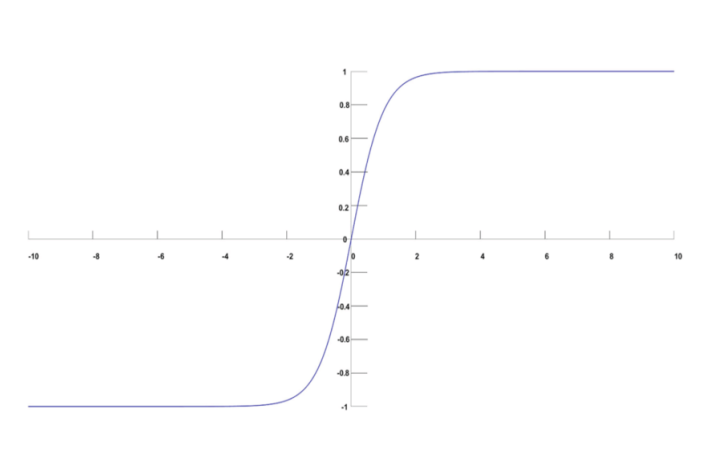
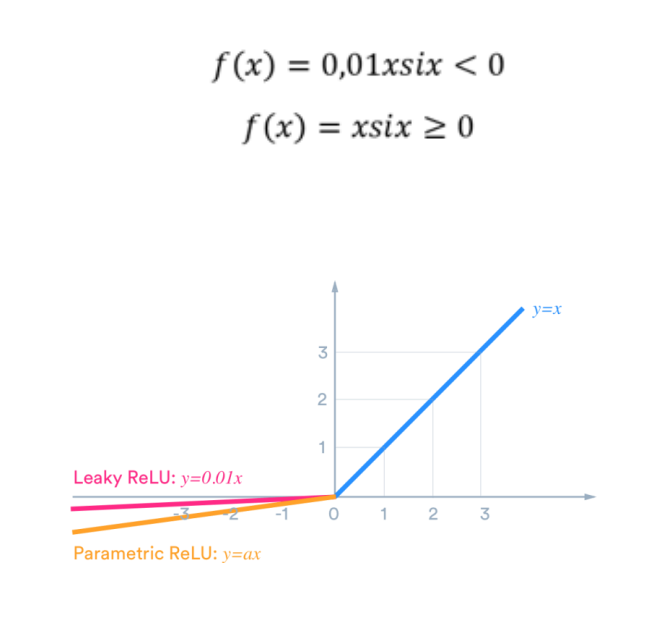
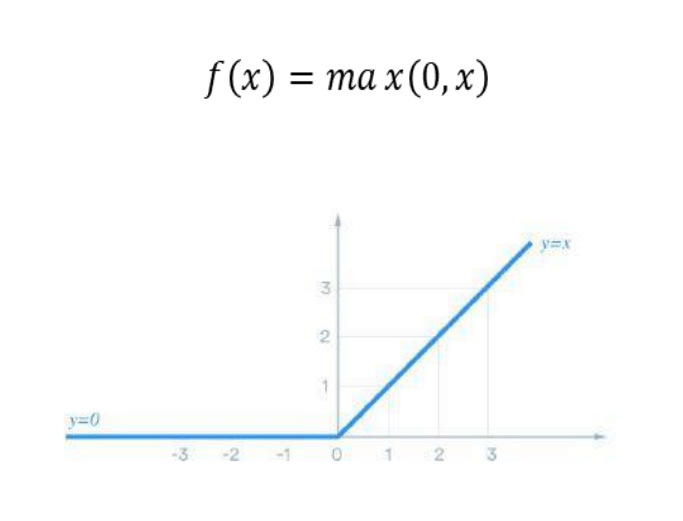
El equipo de Dinov2 ha logrado avances significativos en el autoaprendizaje de visión por computadora, utilizando técnicas de aprendizaje profundo y redes neuronales convolucionales. Los resultados prometen mejorar la capacidad de las máquinas para reconocer objetos y patrones en imágenes de manera autónoma, lo que tiene implicaciones importantes en áreas como la robótica y la Inteligencia Artificial.
Leer másDinov2: Avances en Autoaprendizaje de Visión por Computadora