Multilayer Neural Networks: Advancing Artificial Intelligence
Actualizado: 2026-05-03
Multilayer neural networks are the computational backbone of modern artificial intelligence. Without them there would be no speech recognition, machine translation, large language models, or computer vision as we know them. Understanding their architecture means understanding why deep learning changed the rules of the game.
Key takeaways
- A multilayer neural network consists of an input layer, one or more hidden layers, and an output layer.
- Learning happens through forward propagation and weight adjustment via backpropagation.
- Hidden layers allow learning hierarchical representations: edges → shapes → objects, or phonemes → words → sentences.
- GPUs transformed training by parallelising millions of matrix operations simultaneously.
- Interpretability remains the unsolved challenge: the more layers, the harder it is to understand why the network reached a decision.
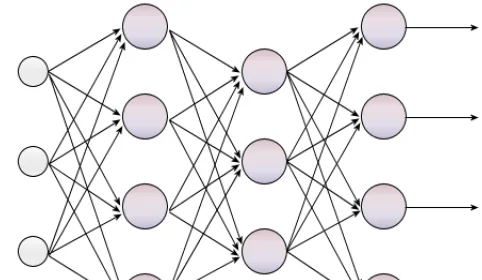
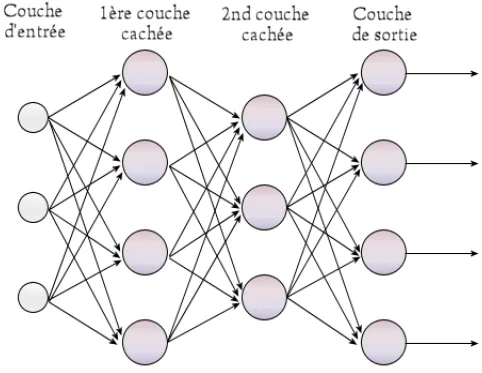
Architecture: Layers, Neurons, and Connections
A multilayer neural network — also called a multilayer perceptron or MLP — organises artificial neurons into sequential layers:
- Input layer: receives raw data (pixels, tokens, numeric values).
- Hidden layers: transform the representation through linear operations and non-linear activation functions.
- Output layer: produces the final result (class, value, probability distribution).

Each neuron computes a weighted sum of its inputs, applies a bias, and passes the result through an activation function. The most used functions are:
- ReLU (Rectified Linear Unit): returns zero for negative values and the value itself for positive ones. The default choice for hidden layers due to computational efficiency.
- Sigmoid: compresses output between 0 and 1. Useful in binary output layers.
- Softmax: converts a value vector into a probability distribution. Standard in multi-class classification.
- Tanh: a sigmoid variant with range (-1, 1), useful in recurrent networks.
How the Network Learns: Forward and Backpropagation
Neural network learning is a two-step iterative optimisation process:
Forward propagation: input data flows from the input layer, through each hidden layer applying transformations, and reaches the output layer producing a prediction.
Backpropagation: the error between prediction and true value is computed via a loss function (cross-entropy for classification, MSE for regression). The gradient descent algorithm propagates that error backwards, computing how much each weight contributed to the error and adjusting them accordingly.
This cycle repeats thousands or millions of times over mini-batches of data until the loss function converges. The hyperparameter controlling the adjustment size at each step is the learning rate — too high and the network oscillates without converging; too low and training takes too long.
Applications: Where Multilayer Networks Make the Difference
Multilayer neural networks underpin a wide variety of AI systems:
- Computer vision: object recognition, anomaly detection in medical images, autonomous driving. See image analysis with computer vision.
- Natural language processing: text classification, sentiment analysis, machine translation. See NLP advances.
- Recommendation systems: collaborative filtering, click prediction. See recommendation and collaborative filtering.
- Fraud detection: identifying anomalous patterns in financial transactions.
- Bioinformatics: protein structure prediction, genomic sequence analysis.
Deep learning takes this concept further: networks with dozens or hundreds of hidden layers learning increasingly abstract representations. Transformers — the architecture behind GPT, BERT, and similar models — are very deep networks with attention mechanisms that have redefined the state of the art in language.
Real Implementation Challenges
Three problems any team encounters when working with deep networks:
1. Massive data requirements Multilayer networks require large volumes of labelled data to generalise well. An image classification network may need hundreds of thousands of examples per class. Data augmentation and transfer learning (starting from pretrained models) alleviate but do not eliminate this problem.
2. Computational cost Training deep networks requires GPUs (or TPUs) for hours, days, or weeks. The energy and financial cost is significant. Efficient architectures like MobileNet or DistilBERT try to reduce this cost while retaining most of the performance.
3. Limited interpretability As the network gains depth, it becomes difficult — often impossible — to explain why it made a specific decision. This is a critical problem in high-stakes domains (medicine, justice, credit). The field of explainable AI (XAI) addresses this challenge with techniques like LIME, SHAP, and Grad-CAM.
Adversarial risks also exist: small perturbations in input data can fool the network in surprising ways. See adversarial machine learning.
Conclusion
Multilayer neural networks are the backbone of modern artificial intelligence. Their ability to learn hierarchical representations from raw data makes them irreplaceable for tasks where explicit rules cannot capture the complexity of the problem. The challenge now is not whether they work — that is proven — but making them more efficient, more interpretable, and more robust under adversarial conditions.




