Redes neuronales multicapa: avanzando en la inteligencia artificial
Actualizado: 2026-05-03
Las redes neuronales multicapa son la base computacional de la inteligencia artificial moderna. Sin ellas no existirían el reconocimiento de voz, la traducción automática, los modelos de lenguaje grandes ni la visión por computadora tal como los conocemos. Entender su arquitectura es entender por qué el deep learning cambió las reglas del juego.
Puntos clave
- Una red neuronal multicapa está formada por una capa de entrada, una o más capas ocultas y una capa de salida.
- El aprendizaje ocurre mediante propagación hacia adelante (forward propagation) y ajuste de pesos por retropropagación (backpropagation).
- Las capas ocultas permiten aprender representaciones jerárquicas: bordes → formas → objetos, o fonemas → palabras → frases.
- Las GPUs transformaron el entrenamiento al paralelizar millones de operaciones matriciales simultáneamente.
- La interpretabilidad sigue siendo el desafío no resuelto: a más capas, más difícil entender por qué la red llegó a una decisión.
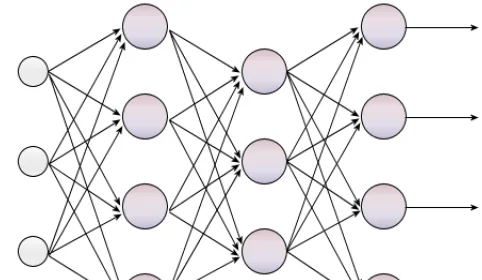
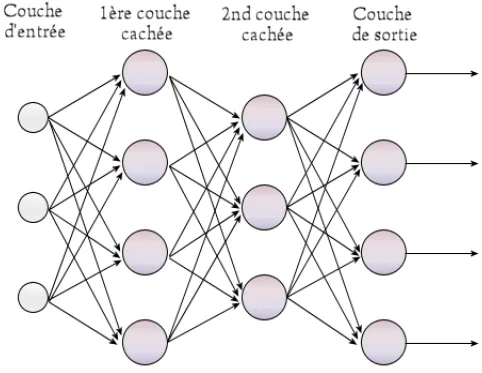
Arquitectura: capas, neuronas y conexiones
Una red neuronal multicapa — también llamada perceptrón multicapa o MLP por sus siglas en inglés — organiza las neuronas artificiales en capas secuenciales:
- Capa de entrada: recibe los datos en bruto (píxeles, tokens, valores numéricos).
- Capas ocultas: transforman la representación mediante operaciones lineales y funciones de activación no lineales.
- Capa de salida: produce el resultado final (clase, valor, distribución de probabilidad).

Cada neurona calcula una suma ponderada de sus entradas, aplica un sesgo (bias) y pasa el resultado a través de una función de activación. Las funciones más usadas son:
- ReLU (Rectified Linear Unit): devuelve cero para valores negativos y el valor mismo para positivos. Es la opción por defecto en capas ocultas por su eficiencia computacional.
- Sigmoide: comprime el resultado entre 0 y 1. Útil en capas de salida binaria.
- Softmax: convierte un vector de valores en distribución de probabilidad. Estándar en clasificación multiclase.
- Tanh: variante de la sigmoide con rango (-1, 1), útil en redes recurrentes.
Cómo aprende la red: forward y backpropagation
El aprendizaje de una red neuronal es un proceso de optimización iterativa en dos pasos:
Forward propagation (propagación hacia adelante): los datos de entrada fluyen desde la capa de entrada, pasan por cada capa oculta aplicando transformaciones, y llegan a la capa de salida produciendo una predicción.
Backpropagation (retropropagación): se calcula el error entre la predicción y el valor real mediante una función de pérdida (cross-entropy para clasificación, MSE para regresión). El algoritmo de gradiente descendiente propaga ese error hacia atrás, calculando cuánto contribuyó cada peso al error y ajustándolos en consecuencia.

Este ciclo se repite miles o millones de veces sobre mini-lotes de datos (mini-batches) hasta que la función de pérdida converge. El hiperparámetro que controla el tamaño del ajuste en cada paso es la tasa de aprendizaje (learning rate) — demasiado alta y la red oscila sin converger; demasiado baja y el entrenamiento tarda demasiado.
Aplicaciones: dónde las redes multicapa marcan la diferencia
Las redes neuronales multicapa son la base de una amplia variedad de sistemas de IA:
- Visión por computadora: reconocimiento de objetos, detección de anomalías en imágenes médicas, conducción autónoma. Ver análisis de imágenes con visión computarizada.
- Procesamiento de lenguaje natural: clasificación de texto, análisis de sentimientos, traducción automática. Ver avances en NLP.
- Sistemas de recomendación: filtrado colaborativo, predicción de clics. Ver recomendación y filtrado colaborativo.
- Detección de fraude: identificación de patrones anómalos en transacciones financieras.
- Bioinformática: predicción de estructura de proteínas, análisis de secuencias genómicas.
El deep learning lleva este concepto más lejos: redes con decenas o cientos de capas ocultas que aprenden representaciones cada vez más abstractas. Los transformers — la arquitectura detrás de GPT, BERT y similares — son redes muy profundas con mecanismos de atención que han redefinido el estado del arte en lenguaje.
Desafíos reales de implementación
Tres problemas que cualquier equipo encuentra al trabajar con redes profundas:
1. Necesidad de datos masivos Las redes multicapa requieren grandes volúmenes de datos etiquetados para generalizar bien. Una red de clasificación de imágenes puede necesitar cientos de miles de ejemplos por clase. Las técnicas de data augmentation y el transfer learning (partir de modelos preentrenados) alivian este problema pero no lo eliminan.
2. Coste computacional El entrenamiento de redes profundas requiere GPUs (o TPUs) durante horas, días o semanas. El coste energético y económico es significativo. Arquitecturas eficientes como MobileNet o DistilBERT intentan reducir este coste manteniendo la mayor parte del rendimiento.
3. Interpretabilidad limitada A medida que la red gana profundidad, se vuelve difícil — a menudo imposible — explicar por qué tomó una decisión concreta. Esto es un problema crítico en dominios de alto riesgo (medicina, justicia, crédito). El campo de la IA explicable (XAI) aborda este desafío con técnicas como LIME, SHAP y Grad-CAM.
También existen riesgos adversariales: pequeñas perturbaciones en los datos de entrada pueden engañar a la red de formas sorprendentes. Ver aprendizaje de máquina adversarial.
Conclusión
Las redes neuronales multicapa son la columna vertebral de la inteligencia artificial moderna. Su capacidad para aprender representaciones jerárquicas a partir de datos en bruto las hace insustituibles para tareas donde las reglas explícitas no pueden capturar la complejidad del problema. El reto no es ya si funcionan — está demostrado — sino hacerlas más eficientes, más interpretables y más robustas ante condiciones adversas.




