The Hyperbolic Tangent: A Powerful Activation Function
Table of contents
- Key takeaways
- Definition and properties
- Advantages over sigmoid
- Implementation in neural networks
- When to choose tanh over other functions
- Frequently asked questions
- Why does tanh converge faster than sigmoid in practice?
- Does tanh suffer the same vanishing gradient problem as sigmoid?
- Can ReLU replace tanh inside an LSTM cell?
- Conclusion
- Sources
Updated: 2026-07-17
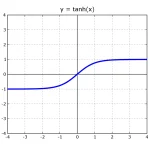
The hyperbolic tangent (tanh) solves one of the main defects of sigmoid: the lack of symmetry. By producing zero-centred outputs between -1 and 1, it facilitates training convergence and remains the preferred choice in recurrent architectures and contexts where balanced output matters.
Key takeaways
- Tanh maps any real value to the interval (-1, 1), with zero-centred output.
- It is mathematically a rescaled version of the sigmoid function: tanh(x) = 2·σ(2x) − 1.
- Symmetry around the origin facilitates optimisation: gradient updates are balanced.
- Shares with sigmoid the vanishing gradient problem at extreme inputs.
- It is the standard activation function in LSTM and GRU memory cells.
Definition and properties
The hyperbolic tangent is defined as:
tanh(x) = (eˣ − e⁻ˣ) / (eˣ + e⁻ˣ)
Its fundamental properties:
- tanh(0) = 0: output is zero-centred.
- tanh(x) → 1 as x → +∞.
- tanh(x) → -1 as x → -∞.
- It is odd: tanh(-x) = -tanh(x).
- Its derivative is tanh'(x) = 1 − tanh²(x), reaching a maximum value of 1 at x = 0.
This symmetry around the origin is the key difference from sigmoid. When activations are zero-centred, the gradients propagating backwards have no systematic bias towards positive or negative, which accelerates convergence.
Advantages over sigmoid
Both tanh and sigmoid are smooth, differentiable throughout their domain, and saturate at extremes. The practical difference between the two is measurable: the derivative of tanh at x=0 equals 1, four times larger than sigmoid’s 0.25 at the same point. But tanh has clear advantages in hidden layers:
- Zero-centred output: subsequent layers receive activations with approximate mean 0, not 0.5 as with sigmoid.
- Stronger gradients: the derivative of tanh at x=0 is 1, versus 0.25 for sigmoid. Larger gradients mean faster learning in the central zone.
- Natural interpretation for classification: negative outputs correspond to one class, positive to another.
The shared disadvantage: vanishing gradient. For |x| > 2, the derivative of tanh falls rapidly towards zero (below 0.07 at x = 2.5). In very deep networks, ReLU or Leaky ReLU are more robust.
Implementation in neural networks
In practice, tanh appears in:
- Hidden layers of recurrent networks (RNN): the hidden state update uses tanh to compress information to the (-1, 1) range.
- LSTM cells: the cell state update function uses tanh, while gates use sigmoid.
- GRU cells: like LSTM, combines tanh and sigmoid in its gates.
- Autoencoder networks: when output must be between -1 and 1 for domain symmetry.

When to choose tanh over other functions
The practical decision:
- Hidden layer in shallow network: tanh or sigmoid, with slight preference for tanh.
- Hidden layer in deep network (>5 layers): ReLU or Leaky ReLU for greater vanishing gradient resistance.
- Recurrent cells (LSTM, GRU): tanh is the standard, well established and stable since Hochreiter and Schmidhuber fixed it in the original 1997 LSTM proposal.
- Output layer for binary classification: sigmoid.
- Output layer for multi-class classification: softmax.
Frequently asked questions
Why does tanh converge faster than sigmoid in practice?
Because its output is zero-centred: the gradients reaching the next layer do not carry the systematic bias produced by sigmoid’s always-positive output (mean 0.5), so weight updates oscillate less and gradient descent moves more directly towards the minimum.
Does tanh suffer the same vanishing gradient problem as sigmoid?
Yes. For |x| > 2 the derivative of tanh falls below 0.07 and approaches zero as |x| grows, just as sigmoid saturates at its extremes. In very deep networks this remains a problem, which is why ReLU and its variants dominate the hidden layers of deep feedforward architectures.
Can ReLU replace tanh inside an LSTM cell?
Not directly: the original LSTM design depends on tanh bounding the cell state to the (-1, 1) range, something ReLU does not guarantee since its output is unbounded above. Swapping in tanh without redesigning the cell tends to destabilise training.
This guide is also available in Spanish: La Tangente Hiperbólica: Función de Activación Potente.
Conclusion
The hyperbolic tangent is the preferred activation function for recurrent layers and any context where output symmetry matters. Its symmetry around the origin makes it more stable than sigmoid in hidden layers, and its integration into LSTM and GRU architectures ensures it will remain relevant as long as recurrent networks have a place in the deep learning toolkit. For very deep feedforward networks, ReLU remains the most efficient option; for recurrent networks and autoencoders, tanh is hard to beat.
Sources: PyTorch (torch.nn.Tanh)[1], TensorFlow (tf.math.tanh)[2], Stanford CS231n, Neural Networks Part 1[3], Wikipedia, Hyperbolic functions[4].



