Agentes de IA en empresa: de demo a valor medible
Actualizado: 2026-06-20
En los últimos meses el discurso sobre agentes de IA ha pasado por una fase interesante. A finales del año pasado todavía era casi todo demo llamativa: un agente navegando por una web, otro escribiendo un email, otro reservando un vuelo. La infraestructura para montar un agente serio existe: OpenAI publicó el Agents SDK y la Responses API, Anthropic consolidó Computer Use y extendió el Model Context Protocol, Google avanzó con Gemini 2.0 y la integración con sus herramientas. La pregunta ya no es si es posible; es si compensa y, sobre todo, cómo se mide.
Este post es una reflexión sobre qué separa los agentes que han generado valor empresarial real de los que han quedado en POC sin métricas. No es un tutorial de frameworks; es una lectura de patrones de éxito y fracaso desde la experiencia con varias implantaciones.
Puntos clave
- El agente con más ROI no suele ser el más sofisticado; es el que automatiza un proceso bien definido con alta carga de trabajo manual.
- El error más común es empezar por el agente en vez de por el proceso: sin flujo claro, el agente añade complejidad sin valor.
- La supervisión humana no es un lujo; es el mecanismo que hace que el agente mejore con el tiempo.
- El coste real de un agente en producción incluye prompt engineering continuo, monitorización y actualización de herramientas.
- Medir antes de desplegar: si no tienes una métrica de base del proceso manual, no puedes demostrar el valor del agente.
Por qué la demo no predice el valor empresarial
Las demos de agentes son convincentes porque muestran capacidad en condiciones controladas. El agente navega, extrae, resume, escribe. El problema es que el paso de «funciona en condiciones controladas» a «funciona en producción con datos reales y flujos irregulares» es donde la mayoría de proyectos se atasca.
Lo que la demo no muestra es la tasa de fallo real sobre entradas no anticipadas, el coste de corrección de errores cuando el agente produce un output incorrecto que llega a un sistema downstream, la latencia en condiciones de carga real, y el esfuerzo de mantenimiento cuando cambia la API, el formato del documento o la política de la herramienta que el agente usa.
El marco más útil que he encontrado para evaluar si un caso de uso de agente tiene sentido empresarial parte de cuatro preguntas:
- ¿El proceso que el agente automatiza tiene una carga de trabajo manual cuantificable?
- ¿El output del agente es verificable sin un experto humano?
- ¿El coste del error es tolerable o recuperable?
- ¿El proceso es lo suficientemente estable como para que las herramientas del agente no queden obsoletas rápidamente?
Los casos que responden sí a las cuatro tienen muchas más probabilidades de generar valor medible.
Casos donde los agentes han funcionado en empresa
Los casos de uso de agentes empresariales que han generado ROI real en organizaciones con las que he trabajado comparten características concretas:
Procesamiento de documentos con extracción estructurada. Facturas, contratos, formularios. El agente extrae campos, valida contra reglas de negocio y produce un registro estructurado. La tasa de precisión es medible (comparando contra revisión manual de muestra), el error tiene consecuencia pero es recuperable, y el volumen justifica la automatización. El ahorro de horas es directo y auditable.
Clasificación y enrutamiento de tickets o solicitudes. El agente lee el texto libre, lo clasifica según una taxonomía conocida, extrae datos clave y lo asigna al equipo o sistema correcto. El valor es reducción de tiempo de primera respuesta y eliminación del trabajo de clasificación manual. La métrica es clara: tiempo de enrutamiento antes y después.
Síntesis de información de múltiples fuentes para briefings internos. El agente recoge datos de varias APIs internas o externas, los combina y produce un resumen estructurado (estado de proyecto, actualización de mercado, resumen de incidentes). El valor es tiempo de preparación de reuniones o informes. Es un caso que requiere supervisión humana del output, pero el volumen justifica tenerlo.
Automatización de flujos de onboarding o configuración. El agente ejecuta pasos predefinidos (crear cuenta, asignar permisos, enviar comunicaciones) para nuevos empleados, nuevos clientes o nuevos entornos. El valor es reducir el tiempo de onboarding y los errores de configuración manual. La supervisión humana se centra en las excepciones, no en los casos habituales.
Patrones de fracaso que se repiten
Los proyectos de agentes que no generan valor comparten patrones igualmente reconocibles:
Empezar por el agente, no por el proceso. Si no tienes documentado el flujo que el agente va a automatizar (quién hace qué, con qué inputs, cuáles son los estados posibles, cuáles son los errores habituales), el agente hereda la ambigüedad del proceso manual y la amplifica. El agente es la solución al problema de flujo, no el sustituto del análisis de flujo.
Ausencia de métricas de baseline. Si no tienes medido cuánto tiempo tarda el proceso manual o cuál es su tasa de error actual, no puedes demostrar que el agente ha mejorado algo. «Funciona mejor» no es una métrica de negocio. La instrumentación del proceso antes del agente es parte del proyecto, no un extra.
Supervisión humana insuficiente en la fase inicial. Los agentes producen errores de formas que los humanos no anticipan. Sin un periodo de supervisión densa (donde un humano revisa cada output del agente antes de que actúe), no se puede construir la biblioteca de casos límite que permite mejorar el prompting y las herramientas. La supervisión inicial no es ineficiencia; es inversión en fiabilidad.
Subestimar el mantenimiento. Los agentes se degradan cuando cambia el entorno: actualizaciones de APIs, cambios de formato en documentos, modificaciones de políticas de acceso. Sin un proceso de monitorización y actualización, la fiabilidad baja gradualmente hasta que el agente falla más de lo que ayuda. El mantenimiento de un agente en producción no es ocasional; es continuo.
Decisiones de diseño que importan
Cuando el caso de uso tiene sentido y el proceso está claro, hay decisiones de diseño que marcan la diferencia entre un agente que mejora con el tiempo y uno que se estanca:
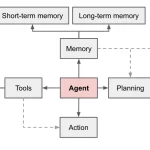
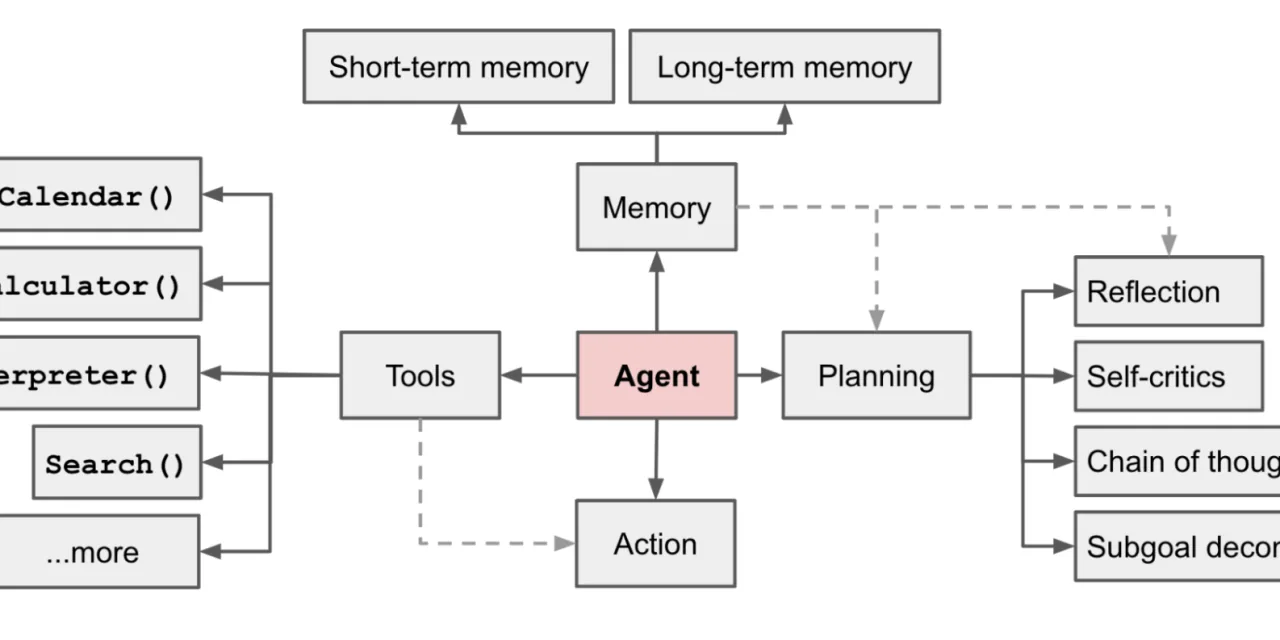
Diseñar para la supervisión, no contra ella. El agente que produce outputs verificables (con evidencia de los pasos que siguió, con las fuentes citadas, con el razonamiento explícito) es más fácil de supervisar, corregir y mejorar. Los outputs opacos dificultan identificar dónde falla el razonamiento.
Separar las herramientas de las instrucciones. Las herramientas que el agente usa (APIs, bases de datos, sistemas internos) deben estar bien documentadas y con interfaces estables. Cuando la herramienta cambia, solo hay que actualizar la descripción de la herramienta, no reescribir el prompt completo.
Establecer límites explícitos de lo que el agente puede hacer. El agente con permisos de escritura sin límites es más peligroso que útil en producción. Los agentes de mayor confianza son los que tienen permisos acotados y escalan a humanos cuando encuentran un caso fuera de su ámbito. Para la dimensión de seguridad de los agentes, el análisis de seguridad de agentes LLM ofrece el marco de amenazas relevante.
Medir la tasa de escalado. Si el agente escala a humanos más del 20-30% de los casos, el proceso no está suficientemente bien definido para automatizarlo. La tasa de escalado es la métrica de madurez del caso de uso, no del agente.
Mi lectura
Los agentes de IA en empresa generan valor cuando resuelven procesos bien definidos con alta carga manual, no cuando demuestran capacidad de razonamiento sofisticado. La sofisticación del agente es secundaria a la claridad del proceso que automatiza y a la calidad de la infraestructura de supervisión que lo rodea.
El valor no viene de la demo; viene del tiempo ahorrado, los errores evitados y la capacidad liberada para trabajo de mayor valor. Esas tres cosas son medibles si el diseño del proyecto las tiene en cuenta desde el principio. Sin métrica de antes, no hay demostración de valor de después.



