OpenRouter is a hosted gateway that gathers more than 400 AI models from over 70 providers behind a single OpenAI-compatible API. You change the base URL, use one key and one balance, and gain automatic routing, failover and pass-through token pricing. Unlike a self-hosted proxy such as LiteLLM, you run no infrastructure at all.
browser-use is an open-source Python library that lets an AI agent drive a web browser the way you do: it opens pages, reads the DOM, clicks and fills in forms. It was born on Playwright and in 2025 switched to speaking Chrome's CDP protocol directly for speed. This guide explains how it works and when to use it.
Firecrawl is an open-source API that turns any web page into clean Markdown, ready for a language model. With scrape and crawl endpoints plus schema-guided JSON extraction, it gives your AI agent reliable web data. This guide covers its formats, how to self-host it with Docker and when it beats a scraper of your own.
Composio connects your AI agent to more than a thousand applications (GitHub, Slack, Gmail, Notion) through pre-authenticated tools and managed OAuth authentication. Instead of writing each integration by hand, you request the tools by name and the agent acts on behalf of each user. This guide explains what it is, how it handles authentication and how to plug it into your agent framework.
Dify is an open-source platform for building AI applications and agents, with a visual workflow canvas, prompt management, a RAG knowledge base and LLMOps layers. You can self-host the whole thing with Docker Compose on top of Postgres, Redis and a vector database. This guide explains how to deploy it and when it beats Flowise and Langflow.
Flowise is an open-source tool that lets you build AI agents by dragging nodes onto a visual canvas, with barely any code. It is built on LangChain.js and you can self-host the whole thing with a single Docker container. This guide covers how to deploy it, the difference between chatflows and AgentFlow v2, and how it compares to Langflow and Dify.
Langflow is an open-source tool for building AI agents and workflows by dragging blocks onto a visual canvas, with barely any code. You can self-host it with Docker, wire up models, tools and vector databases, and publish every flow as an API or as an MCP server. This guide explains how to deploy it and build your first agent.
Durable execution lets an AI agent survive crashes, restarts and API rate limits without losing its progress. Temporal applies this model: your logic lives in a workflow that resumes exactly where it stopped, and every model or tool call runs as an activity that Temporal retries for you automatically on failure.
Deploying an AI agent to production means turning your local script into a containerised service, with external state, observability and managed secrets. In this guide you package an agent inside a minimal Docker image, expose an HTTP endpoint with FastAPI and add health checks, retries and rate limits so it survives real traffic.
E2B is open-source infrastructure that runs your agent's generated code inside isolated Firecracker microVMs, each with its own Linux kernel. It boots in about 150 ms, exposes a stateful interpreter from its Python SDK and can be self-hosted with Terraform. This guide explains why an agent needs a sandbox and how to use E2B.
Prompt caching stores the stable prefix of your prompt (instructions, documents, tools) so it isn't reprocessed on every call. Anthropic and Gemini discount those tokens by up to 90%; OpenAI discounts by 50% on classic models and up to 90% on GPT-5.6. This guide covers each provider, how to structure the prompt, and how to cache on your own machine with vLLM.
promptfoo is an open-source tool to test and evaluate prompts, agents and RAG systems with declarative YAML configs. It compares models like GPT, Claude or Gemini in one matrix, scores answers with automatic assertions and adds red teaming with over fifty vulnerability types. It plugs into your CI, and OpenAI acquired it in March 2026.
DeepEval is the open-source framework for evaluating AI systems as if you were writing Pytest tests: you define cases, pick research-backed metrics (G-Eval, faithfulness, tool correctness) and get a score from 0 to 1 that passes or fails each response, both on your machine and in continuous integration.
Helicone is an open-source LLM observability platform you integrate by changing a single line: your client's base URL. It logs cost, latency and tokens for every call, adds caching and rate limiting, and you can self-host it with Docker. It is Apache-2.0 and has nearly 6,000 GitHub stars, though since March 2026 it sits in maintenance mode.
Langfuse is an open-source platform to observe, debug and evaluate AI applications and agents. You can self-host it with Docker Compose on Postgres, ClickHouse, Redis and S3 storage, and its Python SDK, built on OpenTelemetry, captures traces, spans and generations with their cost and latency. This guide explains how to deploy it and instrument an agent.
DSPy is a Python framework from Stanford that treats calls to an LLM as code: you define signatures with typed inputs and outputs, pick a module such as chain of thought, and let an optimizer write the prompts for you from examples and a metric. That way you compile programs instead of hand-tuning prompts.
Outlines is a Python library for constrained generation: it forces the model to produce output that conforms to a JSON schema, a regular expression or a grammar, with a guarantee by construction rather than statistics. It works with vLLM, Transformers, Ollama and llama.cpp, and its Rust engine adds barely any overhead per token.
Instructor is the most widely used Python library for getting reliable structured outputs from a language model: you define the result you expect as a Pydantic model, Instructor patches the client so the model honours it, and it retries on its own, with the validation error included, until it returns a valid, already-typed object.
Not every open model calls tools equally well: the Qwen3 family, Nous Hermes, Llama 3.1 and Mistral stand out because they were trained for it. To choose, check the Berkeley Function-Calling Leaderboard, make sure a parser exists for the model's template, and match it to your GPU's VRAM.
Function calling lets a model you run with Ollama on your own machine ask your code to call a function (check the weather, query a database) and use the result to answer. Ollama has supported tools since July 2024; in 2026 models such as qwen3 and llama3.3 do it with reasonable reliability.
Qwen-Agent is the Qwen team's official framework for giving their models tools: function calling, a sandboxed code interpreter, RAG and MCP. It is on version 0.0.34, released in February 2026, has around 16,800 GitHub stars and holds the canonical implementation of Qwen3 tool calling, both in the cloud and on your own machine.
Hermes 4 is the family of open-weight models Nous Research released in August 2025, in 14B, 70B and 405B parameter sizes. Its headline change is hybrid reasoning: one model answers directly or deliberates with think tags before replying, and it keeps the Hermes tool-calling format for agents.
Hermes 3 is Nous Research's family of open-weight models, fine-tuned on Llama 3.1 in 8B, 70B and 405B sizes. Its strength is tool use through JSON-formatted function calls. You can run it on your own machine with Ollama or vLLM and give it agentic capabilities without depending on a paid API.
Haystack is a Python framework by deepset, Apache 2.0 licensed, for building AI applications as pipelines of connected components: retrievers, generators and routers. Since the 2.0 rewrite it allows cycles, which lets you add an Agent component that calls tools in a loop. It serves both RAG and production agents.
Agno, the Python framework formerly known as Phidata, builds AI agents with one clear goal: performance. It creates each agent in about two microseconds and uses roughly 3.75 KiB of memory, so it scales to thousands of concurrent agents. It offers agents, teams and workflows, over twenty model providers and the AgentOS runtime.
Mastra is an open-source TypeScript framework for building AI agents and applications with a single package: agents, tools, workflows, memory, RAG and evals. It was built by the team behind Gatsby, hit version 1.0 in January 2026 and connects to over 40 model providers through one interface.
Semantic Kernel is Microsoft's open-source kit for integrating AI models into C#, Python and Java through a kernel that orchestrates plugins and functions. In 2026 its successor is Microsoft Agent Framework, which merges Semantic Kernel and AutoGen; Semantic Kernel itself keeps support for at least one more year.
LlamaIndex is a Python framework focused on connecting your data to a language model. Its AgentWorkflow module lets you build agents that reason and call tools: FunctionAgent for models with function calling, and ReActAgent for any model. This guide shows how to turn a RAG pipeline into an agent that acts over your own documents.
Pydantic AI is the agent framework from the Pydantic team: you build agents in Python where every model output is validated against a type you define. You declare the expected answer as a Pydantic model and the agent guarantees that structure, with dependency injection, tools and support for more than twenty model providers.
The OpenAI Agents SDK is a lightweight Python framework for building agents and multi-agent workflows with few primitives: agents, tools, handoffs, guardrails, sessions and built-in tracing. It is the production-ready evolution of Swarm, works with the OpenAI API and with over 100 other LLMs.
Continue is an open-source coding assistant for VS Code and JetBrains that brings chat, autocomplete, inline editing and an agent mode into a single panel. Under the Apache 2.0 licence it works with more than a hundred models, including ones you run locally with Ollama, so you pick the model and keep control of your code.
Windsurf is the agentic code editor created by Codeium: a VS Code fork whose agent reads your project, plans and edits several files with your approval. In July 2025 Cognition, the company behind Devin, bought it, and on 2 June 2026 it was renamed Devin Desktop; its agent Cascade reached end of life on 1 July 2026 and was replaced by Devin Local.
Gemini CLI is Google's coding agent for the terminal: open source, with a one-million-token context window and the Gemini 3 model. Since 18 June 2026 its free tier for individuals moved to Antigravity CLI, but the tool still works with an API key from AI Studio or an enterprise licence.
Goose is an open-source AI agent created at Block that runs on your own machine as a desktop app, CLI and API. It reads and writes files, runs commands and tests, and works with more than fifteen model providers and MCP extensions. It is free, licensed under Apache 2.0, and you pay only for model usage.
OpenHands, formerly OpenDevin, is an open-source platform that solves programming tasks end to end: it takes a request, opens a sandbox container and edits files, runs commands and browses the web until it is done. It runs with Docker on your own machine and works with the model you choose.
The Codex CLI is OpenAI's coding agent that works inside your terminal: you describe a task, it reads your repository, proposes the changes and runs commands inside a sandbox you control. It is open source, installs with npm and works with your ChatGPT account or with an API key.
Roo Code is an open-source VS Code extension, born as a fork of Cline, that turns the editor into a team of agents with specialised modes (Code, Architect, Debug, Ask and Orchestrator). The project was archived in May 2026 at version 3.54.0, but its community continuation ZooCode keeps the same features alive.
Cline is a VS Code extension that turns your editor into an autonomous coding agent: it reads your project, plans changes in Plan mode and carries them out in Act mode, showing every edit as a diff you approve. It is open source and works with your own API key or with local models.
A multi-agent system splits a task across several specialised agents coordinated by a design pattern. The three most common are orchestrator-workers, where a lead agent delegates to parallel subagents; hierarchical, with teams of teams; and network, where any agent hands control to another through a handoff.
ReAct and plan-and-execute are the two control patterns for an AI agent. ReAct decides one step at a time, reasoning and acting in a loop; plan-and-execute draws up a full plan first and then executes it step by step. The former adapts better to surprises; the latter uses fewer calls and plans long tasks with more order.
Context engineering is the craft of deciding what information enters a model's window at each step of an agent. Beyond prompt engineering, it manages the whole set of tokens: instructions, tools, memory and history. Its goal is the smallest possible set of high-signal tokens that still completes the task.
Human-in-the-loop is the pattern that keeps a person inside an AI agent's decision loop: the agent stops at an approval point before an irreversible action, waits for your confirmation and resumes with its state intact. Frameworks such as LangGraph and OpenAI's Agents SDK implement it with interruptions and tool approval.
Memory is what lets an AI agent remember beyond a single conversation. Its working memory is the context window, ephemeral and limited; its long-term memory stores facts, experiences and procedures in an external store, almost always a vector database, and retrieves them when they are needed to keep acting coherently.
The reflection pattern makes an agent critique its own output and rewrite it before accepting it. One model generates, a second step evaluates and flags mistakes, and a third revises, in a loop of one or two rounds. It improves quality on tasks with clear criteria, but each cycle adds model calls, tokens and latency.
Planning lets an AI agent solve long tasks: instead of improvising step by step, it first breaks the goal into an ordered list of subtasks and then runs them. The planner-executor pattern separates thinking from acting, cuts the number of model calls and lets the agent replan when a step fails midway through the job.
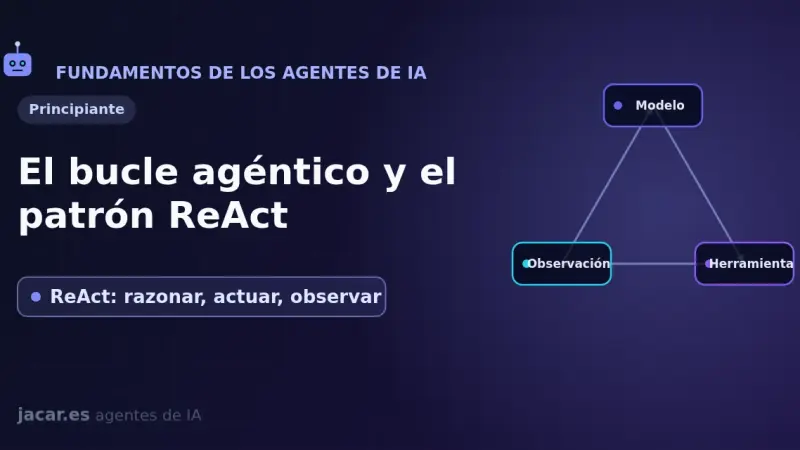
The ReAct pattern (Reason + Act) organizes an agent as a repeating three-step loop: reason about what to do, take an action with a tool, and observe the result. Introduced by Yao and colleagues in 2022, it interleaves reasoning and acting so the model can plan, consult external sources, and fix its own mistakes as it goes.
An AI agent is a program that uses a language model as its brain to decide for itself which steps to take toward a goal: it reasons, calls external tools, observes the result and repeats that loop until it is done. Unlike a chatbot, it does not just answer; it acts.
Tested May 2026 recipe: oMLX 0.3.8 on Mac M5 Max with 128 GB, TurboQuant at 3.5-bit, Qwen 3.6 35B-A3B model stack, Claude Code wiring and real benchmarks.
12 min2.8K5.0
We use first- and third-party cookies to analyze site traffic. You can accept them, reject them, or configure your choice.
Learn more about cookies
Cookie preferences
NecessaryEssential for the site to work. Always on.
AnalyticsHelp us understand how the site is used (Google Analytics).