Digital Twins: When the Factory Has a Software Replica
Actualizado: 2026-05-03
Digital twin is one of the most used — and most misunderstood — terms in Industry 4.0. The base idea is sound: a software replica of a physical asset (machine, production line, whole plant) synchronised with real-time data that can simulate, predict, and optimise. This article covers what a digital twin really is, when it adds value over simpler alternatives, and the mistakes that sink projects.
Key takeaways
- A digital twin requires a model, a bidirectional connection to the real asset, and simulation capability; without all three, it isn’t one.
- Most projects live at levels 1-2 (monitoring + analytics); the predictive level 3 is what justifies the larger investment.
- Predictive maintenance, energy optimisation, and operator training are the use cases with the clearest ROI.
- The most repeated mistake is starting with 3D visualisation instead of data quality and the predictive model.
- Without a dedicated team maintaining the model, the twin becomes outdated within 12-18 months.
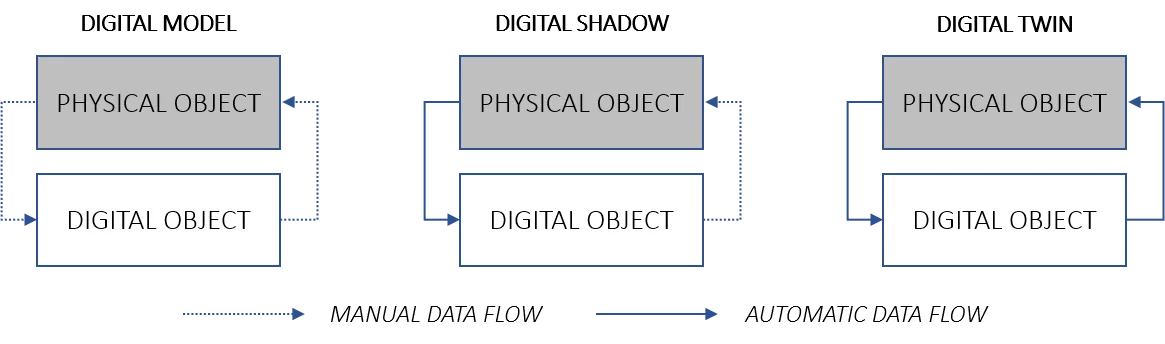
What It Is and What It Isn’t
A digital twin has three essential components:
- Software model of the physical asset — its geometry, behaviour, and operational parameters.
- Bidirectional or monitoring connection with the real asset via IoT sensors.
- Simulation or prediction capability — running “what if” scenarios on the model.
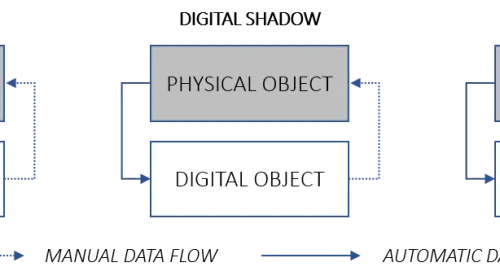
Without all three, it isn’t a digital twin. A dashboard with real-time data is monitoring. A CAD model without live data is just design. A simulation without sync to the real system is just a simulation.
Strict definition matters because a lot of what gets sold as “digital twin” is really one of those components only, with marketing on top.
Maturity Levels
Digital twins have four maturity levels:
- Level 1: Visual replica with real-time data. You visualise the asset in 3D with live metrics. Useful for monitoring, but not predictive.
- Level 2: Replica with history and analytics. Above plus trends, comparisons against baselines, and smart alerts.
- Level 3: Predictive. ML models trained on historical data predict failures, consumption, or quality before they happen.
- Level 4: Prescriptive / autonomous. The twin recommends actions — or executes them directly via control — to optimise the real system.
Most production projects live at levels 1-2 with aspirations of 3. Level 4 is rare outside large-company pilots. The IoT architecture supporting these levels builds on the same principles described in Industry 4.0 concepts about the Digital Twin of the Organisation.
Cases Where It Adds Real Value
Three cases with clear, demonstrable ROI:
- Predictive maintenance of critical equipment. Turbines, compressors, large motors. An unplanned failure can cost hours or days of production. A twin fed by vibration, temperature, and electrical consumption sensors predicts failures weeks in advance.
- Energy consumption optimisation. Modelling the thermal behaviour of a building or plant and simulating adjustments (setpoint temperatures, equipment schedules) without touching the real system. Tests that would be costly in production are done in software.
- Training and onboarding. New operators practise on the twin — including failure and emergency scenarios — without risk to the real system.
Cases Where It Doesn’t Pay Off
A digital twin is often proposed where something simpler would suffice:
- If you only need real-time monitoring → a Grafana dashboard with IoT data covers the case at 10% of the cost.
- If the asset is low-cost and easily maintained → the modelling investment isn’t recouped. If the bearing costs €50 and replacement takes 30 minutes, you don’t need to predict its failure.
- If the data isn’t reliable → a twin built on bad data predicts badly and undermines trust in the whole system.
- If there’s no operational capacity to maintain the model → physical processes change. Without updating the model, it becomes outdated in months.
Typical Architecture
A level 2-3 digital twin has this general shape:
Physical asset (plant, machine)
│
└── IoT sensors → Edge gateway → MQTT broker
│
┌─────────────────────────────────────┘
│
▼
TimescaleDB / InfluxDB ←── Stream processing
│ (filters, aggregation)
│
├──→ 3D Dashboard (Unity, Three.js, Unreal)
│ (current state visualisation)
│
├──→ Simulation engine
│ (physical model, FEM, CFD per case)
│
└──→ ML models
(failure prediction, optimisation)Each box is a significant project. That’s why a complete digital twin is a multi-year effort, not a quarter.

Frequent Mistakes
Five mistakes that repeat in real projects:
- Starting with 3D visualisation. It’s what “sells” best in demos but the least useful part. Without a predictive model behind it, it’s just an expensive diorama.
- Modelling everything at once. Wanting to cover the whole plant from the start. Better to start with one critical, well-understood piece of equipment and expand from there.
- Data without governance. Sensors that change units, lost calibrations, inconsistent naming across lines. A digital twin amplifies data-quality problems.
- Ignoring operators. If the real system is run by operators with decades of experience, their knowledge must be in the model. A twin built solely from data remains incomplete.
- Unmaintained twins. The model is code and configuration. Without a dedicated team, it drifts. In 12-18 months it’s outdated and stops being useful.
Who Is Well-Positioned to Start
Organisations where a digital twin is most likely to succeed share these characteristics:
- Critical assets with costly failures (energy, chemical, heavy manufacturing).
- Already-established data culture — previous IoT projects produced reliable data.
- Combined team of process engineering and software/data engineering. Without that interdisciplinarity, the project fails.
- Clear executive-level sponsorship — twin projects cross multiple areas and need backing.
The observability layer feeding these models relies on technologies like OpenTelemetry for metrics and traces collection from control systems.
Conclusion
Digital twins are a powerful tool when applied to the right problems with sufficient data maturity. They’re neither a hollow trend nor a universal solution: they’re a serious investment that returns in specific cases. Before starting one, make sure the problem justifies it, the data allows it, and the team can maintain it long-term.