Cachés para LLM: ahorrar tokens sin tirar la calidad
Actualizado: 2026-07-12
Colocar un proxy con caché entre tu aplicación y el proveedor del modelo de lenguaje es una de esas optimizaciones que parecen obvias en cuanto alguien las menciona, y sin embargo muchos equipos tardan meses en implementarlas porque el diseño correcto tiene más aristas de las que parecen. La diferencia entre una caché bien hecha y una mal hecha puede ser un ahorro del 70 % en tokens frente a una experiencia de usuario degradada que nadie detecta hasta que es tarde.
Puntos clave
-
Las peticiones repetidas o casi repetidas son la base de todo ahorro por caché.
-
Cuatro variedades cubren los casos principales: exacta, normalizada, semántica y jerárquica.
-
La caché semántica captura mucho más tráfico pero introduce el riesgo de falsa equivalencia.
-
Los proveedores grandes ofrecen caché de prompt nativa que elimina parte del trabajo.
-
Sin métricas de calidad ejecutadas regularmente, la caché puede degradar la aplicación de forma invisible.
El punto de partida
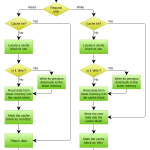
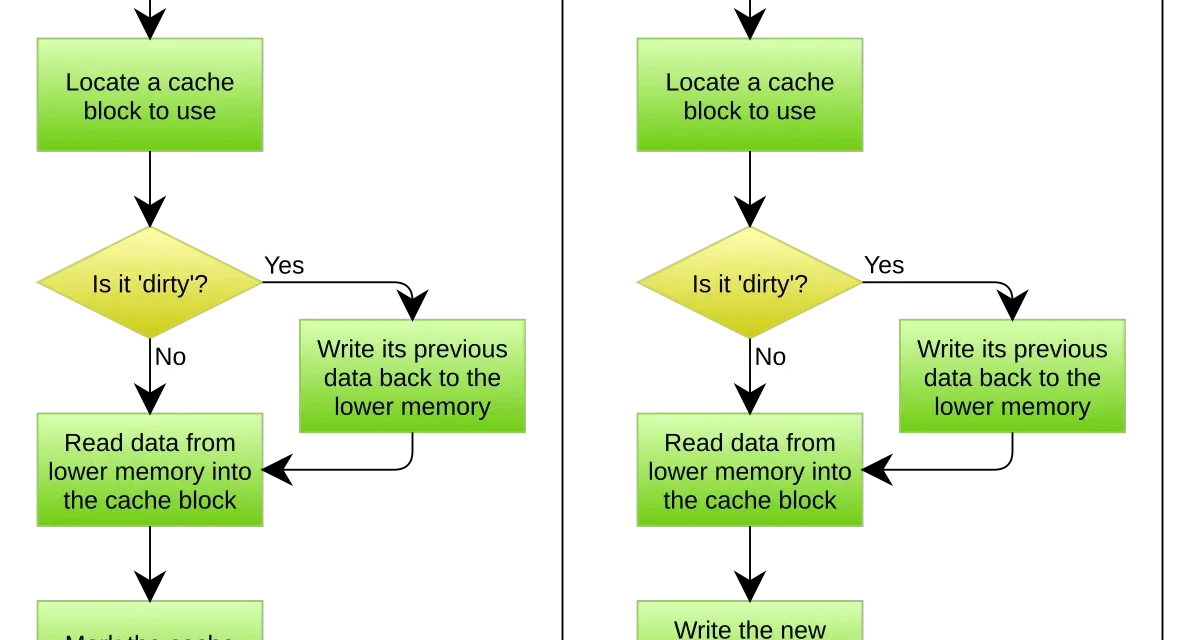
La tesis es sencilla: muchas peticiones que tu aplicación envía al modelo son repetidas o casi repetidas. Si detectas la repetición y devuelves la respuesta anterior sin llamar al proveedor, ahorras los tokens de esa petición. En aplicaciones con preguntas frecuentes, conversaciones sobre documentación o plantillas recurrentes, los porcentajes de repetición pueden ser altísimos.
La complicación aparece al definir qué significa "petición repetida". El caso trivial es cuando el texto de entrada es idéntico byte a byte. Pero la mayoría de peticiones interesantes tienen variaciones: espacios distintos, nombres sustituidos, fechas diferentes. Una caché exacta sin normalización ignora estas similitudes y deja ahorro sobre la mesa.
Caché exacta
El patrón más simple: hash del texto completo de la petición como clave, respuesta como valor. Se implementa en veinte líneas sobre Redis o Memcached. Funciona bien cuando las peticiones vienen de sistemas automatizados con entradas deterministas o cuando los usuarios preguntan exactamente lo mismo repetidamente.
Antes del hash conviene aplicar normalización: trim, colapso de espacios, minúsculas selectivas. Esto mejora la tasa de acierto sin cambiar la semántica y es casi siempre rentable.
Caché semántica
El siguiente paso es reconocer peticiones similares aunque no idénticas. "¿Cuál es el horario del soporte?" y "¿A qué hora atiende el soporte?" son la misma pregunta con distintas palabras. Una caché semántica captura esta equivalencia embebiendo la petición con un modelo pequeño, buscando en un índice vectorial peticiones anteriores cercanas y reutilizando la respuesta si la similitud supera un umbral.
Las ventajas son enormes; los riesgos, también. La falsa equivalencia es la trampa principal: dos preguntas que parecen similares semánticamente pueden requerir respuestas distintas por algún detalle sutil. La calibración del umbral es empírica y hay que repetirla si la distribución de peticiones cambia.
Una mitigación útil es verificar la respuesta cacheada antes de devolverla con una llamada barata al modelo: "¿esta respuesta es correcta para esta petición? Sí o no". Añade coste pero protege contra falsos positivos. Herramientas como GPTCache[1], una biblioteca open source de Zilliz, ilustran el patrón a nivel de producto: sus propios mantenedores anuncian reducciones de coste de hasta 10 veces y mejoras de velocidad de hasta 100 veces cuando el caché acierta.
Caché jerárquica
En aplicaciones con conversaciones largas el patrón más interesante es cachear no la petición completa sino partes estructurales: la instrucción de sistema, el contexto de la aplicación, los documentos recuperados. Los proveedores grandes han introducido mecanismos de caché de prompt nativa que hacen esto de forma integrada: marcas algún fragmento como cacheable y si una petición posterior lo reutiliza, esa parte se cobra a un precio reducido. La documentación de caché de prompts de Anthropic[2] cobra las lecturas de caché a una décima parte del precio de entrada estándar, con una prima de 1,25 veces para escrituras con retención de cinco minutos y de 2 veces para una hora. La guía equivalente de OpenAI[3] activa el cacheo automáticamente a partir de 1024 tokens y declara reducciones de hasta el 90 % en coste y el 80 % en latencia, con una retención de entre cinco y diez minutos por defecto y hasta 24 horas en el nivel extendido.
Esta caché jerárquica es complementaria a las anteriores, no sustituta. Una aplicación bien diseñada puede combinar caché exacta local para peticiones triviales, semántica para equivalencias y caché de prompt del proveedor para la parte común de contextos largos. Cada capa captura un tipo distinto de repetición y los ahorros se suman.
Trampas operativas
-
Privacidad. Si la aplicación cachea respuestas a peticiones con datos personales, esos datos quedan almacenados. Hay que definir políticas claras: qué se cachea, durante cuánto tiempo y con qué mecanismos de borrado.
-
Invalidación. Una respuesta cacheada hace tres días puede estar obsoleta si los datos subyacentes cambiaron. Conviene tiempo de vida corto para respuestas sensibles al tiempo y mecanismos de invalidación explícita.
-
Degradación silenciosa. Una caché que funciona mal devuelve respuestas que parecen razonables. Sin métricas de calidad ejecutadas regularmente sobre tráfico cacheado, el equipo puede creer que todo va bien durante meses.
-
Tratar la caché como parche. Una caché cambia las propiedades del sistema: latencia, consistencia, comportamiento bajo fallos. Hay que diseñar para estos cambios desde el inicio, no instalarla como último recurso cuando la factura sube.
Métricas que importan
Tres métricas permiten evaluar la salud de la caché:
-
Tasa de acierto. Qué porcentaje de peticiones se resolvió desde la caché. Por debajo del 10 % la complejidad no compensa; por encima del 40 % ya es claramente rentable.
-
Ahorro efectivo en tokens. Tasa de acierto × tamaño medio de petición, convertido a euros o dólares. Es el número real que importa al CFO.
-
Calidad percibida. Evaluación automatizada sobre peticiones reales con y sin caché, comparando resultados. Si esta métrica no se vigila, la caché puede degradar la aplicación de forma invisible.
La vigilancia de calidad es especialmente crítica cuando se introduce caché semántica. Esta misma disciplina de métricas se aplica cuando se combina la caché con un enrutador de inferencia para maximizar el ahorro. Para aplicaciones que dependen de agentes de IA o de pipelines de RAG conversacional, la caché de contexto largo del proveedor es especialmente valiosa.
La decisión de producción
La pregunta que usaría como control antes de desplegar es si el equipo sabe cómo detectar si la caché está devolviendo respuestas malas. Si la respuesta es no, la caché no está lista para producción aunque técnicamente funcione. Si la respuesta es sí, con métricas automáticas y revisiones periódicas, entonces la caché es una palanca enorme.
Empezar por caché exacta normalizada es prudente: aporta ahorro inmediato con riesgo mínimo. Añadir caché de prompt del proveedor cuando sea aplicable captura otro tramo sin riesgo adicional. Solo pasar a caché semántica cuando se haya construido la disciplina de medición necesaria. Esa progresión es lo que separa las cachés que ahorran dinero de las que ahorran dinero a costa de otra cosa.
Esta entrada también está disponible en inglés: LLM caches: saving tokens without dropping quality.


