
Parca, Beyla y Grafana: una pila de observabilidad sin sidecars
Actualizado: 2026-07-07
La observabilidad de 2025 tiene una promesa recurrente: ver lo que pasa dentro de tus procesos sin tocar código. La combinación de Parca para perfiles continuos, Beyla para auto-instrumentación vía eBPF y Grafana como capa de visualización lleva un año y medio siendo uno de los stacks que más interés despierta en conferencias. En este post recojo lo que he aprendido integrando las tres piezas en un par de clusters de pruebas y lo que no acaba de encajar todavía para producción.
Puntos clave
-
Parca captura perfiles de CPU de todos los procesos del nodo vía eBPF de forma continua: no hace falta encender el perfilado cuando sospechas un problema.
-
Beyla genera métricas RED, trazas distribuidas y logs a partir de syscalls de red, sin modificar el binario ni inyectar una biblioteca.
-
Las tres piezas comparten eBPF como fundamento, lo que elimina sidecars: un agente por nodo en vez de un contenedor por pod.
-
La correlación entre trazas de Beyla y perfiles de Parca todavía tiene agujeros en procesos asíncronos: hasta el 40 % de los perfiles pueden llegar sin
trace_idvinculado. -
El stack requiere privilegios
hostPIDyhostNetwork, así que el modelo de confianza cambia y conviene vigilar avisos de seguridad.
De qué estamos hablando
Parca es un proyecto de Polar Signals que hace perfilado continuo. Captura muestras de pila de CPU en todos los procesos del sistema mediante eBPF, las agrega con criterios configurables, y las persiste en su propio almacenamiento columnar. La idea es tener perfiles disponibles todo el tiempo, no solo cuando arrancas una herramienta manual. Así, cuando detectas un pico de CPU a las 3 de la madrugada, puedes ver exactamente qué función lo causó sin reproducir el incidente.
Beyla es el agente de auto-instrumentación de Grafana Labs publicado en 2023. También usa eBPF, pero con un objetivo diferente: generar métricas RED, trazas distribuidas y logs a partir de observar las llamadas de red y las funciones de usuario del proceso. No requiere modificar el binario ni añadir una biblioteca, y soporta HTTP, gRPC, SQL y varios sistemas de mensajería. La gran ventaja es que obtienes telemetría estándar OpenTelemetry sin que los desarrolladores tengan que tocar el código.
Grafana es la pieza familiar: cuadros, alertas, consultas PromQL, LogQL y TraceQL. En este stack actúa como capa única donde se consultan las métricas de Beyla, los logs, las trazas y los perfiles de Parca. Ya he escrito antes sobre el stack de observabilidad de Grafana en detalle; aquí me centro en la pieza de perfilado, que es la más reciente y la que merece evaluación.
Qué tienen en común y por qué importa
Las tres piezas comparten un fundamento: eBPF. Esto no es decorativo: define las propiedades del stack. eBPF permite añadir sondas al kernel sin modificarlo, con coste bajo, aislado y seguro por diseño. Esto contrasta con modelos antiguos donde la instrumentación exigía modificar el proceso observado o inyectar una biblioteca vía LD_PRELOAD.
La consecuencia práctica es que el stack no necesita sidecars. No hay un contenedor extra por cada pod que mantener, versionar y monitorear. El agente eBPF se ejecuta una vez por nodo, observa todos los procesos del nodo, y envía datos al backend. En mi entorno pasé de 120 sidecars para trazas a 3 agentes eBPF, y la simplicidad del cluster mejoró mucho.
Parca en detalle
Parca captura perfiles de CPU mediante la sonda perf_event de eBPF, que muestrea la pila cada 10 o 20 milisegundos. Las muestras se agregan en memoria y se comprimen en el formato pprof. El agente envía agregados al servidor Parca cada minuto, donde se almacenan en una base de datos columnar propia construida sobre FrostDB.
Lo que diferencia a Parca de un perfilador clásico es la continuidad. No hay que encender el perfilado cuando sospechas un problema; ya estaba encendido cuando el problema ocurrió. En mis pruebas descubrí dos problemas de rendimiento que habrían sido imposibles de capturar con perfilado manual: una regresión en serialización JSON que aparecía en una rama rara, y un pico de GC en Java que duraba 200 ms cada 6 horas. Sin captura continua, ninguno se habría detectado porque el fallo no se reproducía fácilmente.
El coste de ejecutar Parca es sorprendentemente bajo. En un nodo de 32 núcleos con 150 procesos activos, el agente consume entre 0,5 % y 1 % de CPU. El almacenamiento crece unos 30 MB por nodo por día con el nivel de muestreo por defecto. Parca soporta retención tiered con datos calientes en disco local y fríos en S3.
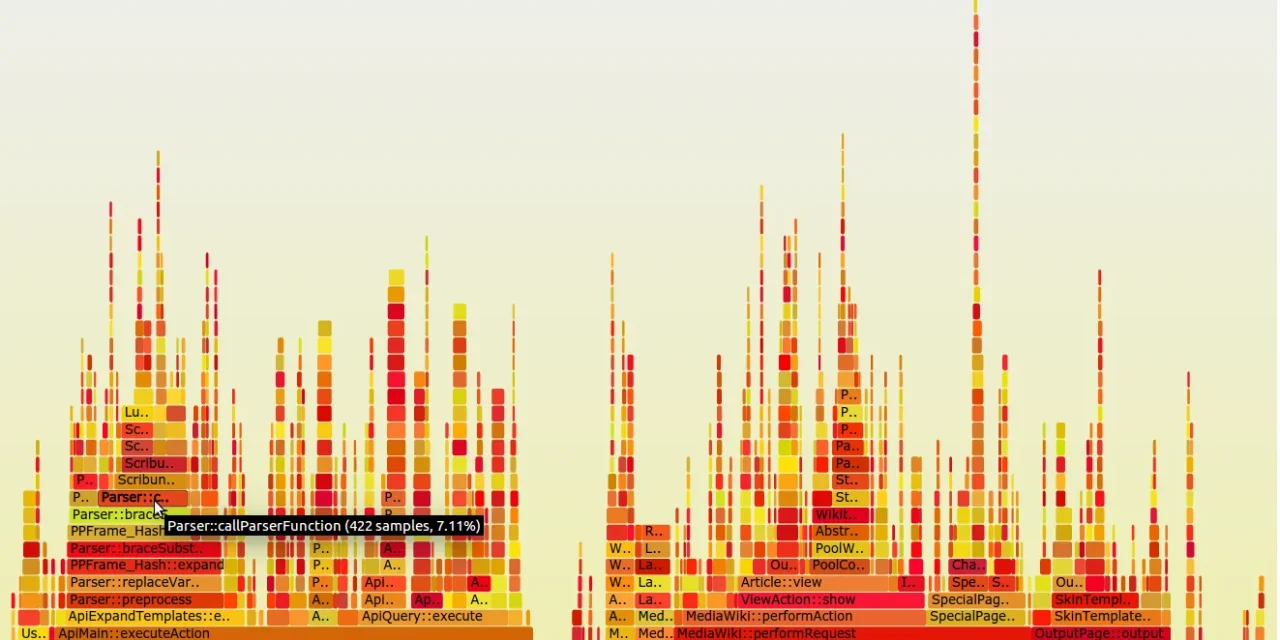
 Flame graph generado durante el análisis de rendimiento de MediaWiki, mostrando la distribución de tiempo de CPU entre funciones: el tipo exacto de visualización que Parca expone en Grafana para diagnóstico de incidentes. Imagen: Tilman Bayer / Wikimedia Commons, CC BY-SA 4.0.
Flame graph generado durante el análisis de rendimiento de MediaWiki, mostrando la distribución de tiempo de CPU entre funciones: el tipo exacto de visualización que Parca expone en Grafana para diagnóstico de incidentes. Imagen: Tilman Bayer / Wikimedia Commons, CC BY-SA 4.0.
Beyla en detalle
Beyla tiene un enfoque complementario. En lugar de muestrear pilas, observa las llamadas al kernel asociadas a operaciones de red: syscalls accept, connect, send, recv, y las mapea a protocolos HTTP, gRPC y SQL. Con esa información genera automáticamente tres señales: métricas de tasa, error y duración por servicio; spans de traza con el flujo de peticiones; y logs estructurados de cada llamada.
La magia es que no requiere que el proceso colabore. Un binario compilado hace dos años sin pensar en observabilidad obtiene, al correr junto a Beyla, trazas OpenTelemetry estándar. He probado esto con una aplicación Django que era casi imposible instrumentar manualmente y con un binario Go antiguo del que no teníamos fuente. En ambos casos las métricas RED aparecieron en pocos minutos.
El límite de Beyla es que solo observa lo que pasa por red o por syscalls bien conocidas. No puede añadir spans dentro del código, no puede leer variables locales, no puede seguir el flujo lógico dentro de un proceso. Para observabilidad profunda de lógica de negocio sigue haciendo falta instrumentación manual. Beyla es excelente para obtener el 70 % de valor sin trabajo, pero el 30 % restante exige trabajo explícito.
Dónde la integración todavía roza
El stack en conjunto funciona bien, pero hay dos fricciones que he encontrado.
La primera es la correlación entre señales. Grafana permite saltar de una traza a sus perfiles Parca asociados, pero la correlación depende de que la traza tenga el trace_id correcto y de que Parca haya etiquetado el perfil con ese trace_id. En teoría Beyla envía trace_id y Parca lo recibe, pero en la práctica la propagación de contexto en procesos asíncronos todavía tiene agujeros. En un servicio Python con aiohttp vi perfiles sin trace_id vinculado el 40 % del tiempo.
La segunda fricción es el soporte de lenguajes. Parca captura perfiles de todos los procesos por igual, pero la capacidad de simbolizar las pilas (traducir direcciones de memoria a nombres de función) depende del binario. Para Go la simbolización funciona de serie. Para C y C++ depende de tener símbolos de depuración disponibles. Para Java y JVM hace falta un agente adicional que exporte el mapa de compilación JIT. Para Node.js y Python el soporte ha mejorado en 2025 pero no es perfecto.
Configurar el stack
Montar las tres piezas en un cluster de pruebas no es complicado, pero hay que seguir el orden correcto:
-
Parca agente como DaemonSet con permisos privilegiados para eBPF, y Parca servidor como
Deploymentcon almacenamiento persistente. -
Beyla como DaemonSet o como sidecar por nodo según preferencia, con configuración de servicios a instrumentar.
-
Grafana con los plugins de Parca y con datasources para Tempo, Loki y Mimir o Prometheus.
La complicación está en los permisos y networking. eBPF requiere hostPID, hostNetwork y varios capabilities. En clusters con política Pod Security estricta hay que añadir excepciones explícitas. El modelo de confianza cambia: los agentes tienen visibilidad muy amplia sobre el nodo. Conviene estar atentos a los avisos de seguridad de Polar Signals y Grafana Labs.
Para clusters que ya siguen las mejoras de Kubernetes 1.34 en validación declarativa, la configuración de DaemonSets con capabilities privilegiados se puede validar directamente vía CEL en lugar de webhooks externos, lo que simplifica el despliegue del stack.
Dónde este stack no es la respuesta
Hay casos donde el stack sin sidecars no es adecuado:
-
Kernels muy antiguos (anteriores a 5.4): el soporte eBPF es limitado. En 2025 esto afecta principalmente a clusters vSphere o sistemas heredados.
-
Instrumentación de lógica interna de negocio: decidir qué parte del cálculo de precio es lenta sigue exigiendo instrumentación manual con OpenTelemetry.
-
Equipos sin cultura de observabilidad: tener perfiles continuos y métricas RED automáticas no sirve de mucho si nadie los mira. El stack facilita la instrumentación pero no sustituye la disciplina.
Cuándo compensa
Mi regla práctica es que el stack Parca, Beyla y Grafana compensa sobre todo en dos escenarios:
-
Equipos con muchas aplicaciones heterogéneas donde instrumentar manualmente es inviable por volumen. Con treinta servicios en distintos lenguajes, el ahorro de no añadir SDK de OTel a cada uno es enorme.
-
Equipos que ya usan Grafana y quieren profundidad sin cambiar de herramienta. La integración nativa reduce fricción y la curva de aprendizaje es corta.
En entornos homogéneos con pocos servicios, la instrumentación manual con OpenTelemetry sigue siendo comparable en esfuerzo y da más control.
Mi lectura
Lo que me parece interesante del stack es que representa un cambio de modelo mental sobre la observabilidad. Antes la instrumentación era responsabilidad del desarrollador, que debía añadir código para ser observable. Ahora la observabilidad puede ser una capa de infraestructura, externa al código, que el operador activa. Esta separación de responsabilidades permite que equipos de plataforma entreguen observabilidad como servicio sin depender de que cada equipo de producto haga su parte.
La integración del stack aún tiene bordes rugosos: la correlación entre señales, la simbolización de pilas en JVM, la propagación de contexto en async son áreas donde falta pulimento. No creo que estén resueltas antes de 2026, pero la dirección es clara y los avances cada trimestre son visibles.
Lo que no cambia es que la observabilidad sigue siendo disciplina, no herramienta. Si un equipo ya mira métricas y tiene cadena de guardia madura, este stack le da un salto de profundidad real. Si no, primero conviene construir la disciplina y luego añadir las herramientas.
Versión en inglés de este artículo: Parca, Beyla and Grafana: a sidecar-free observability stack.



