Frameworks de evaluación para retrieval: Ragas y similares
Actualizado: 2026-05-03
Construir un sistema RAG es relativamente fácil: embeddings + vector DB + LLM. Medir si funciona bien es el desafío real. ¿Las respuestas son fieles al contexto recuperado? ¿El contexto es relevante a la pregunta? ¿La respuesta responde lo que se preguntó? Sin métricas, la evaluación es intuición. Ragas[1] y frameworks similares convierten esas preguntas en números comparables entre versiones.
Puntos clave
- Ragas define cuatro métricas core: faithfulness, answer_relevancy, context_precision y context_recall.
- Faithfulness detecta alucinaciones: qué fracción de los claims de la respuesta están respaldados por el contexto recuperado.
- Integrar evaluación en CI desde el primer día detecta regresiones antes de que lleguen a producción.
- El coste de evaluar con GPT-4 puede ser significativo: estrategias de subset mode y evaluadores más baratos reducen el gasto.
- Las métricas son un proxy: la revisión humana periódica sigue siendo el ground truth.
Las cuatro métricas que importan
Faithfulness
¿La respuesta está respaldada por el contexto recuperado? Se calcula como la fracción de claims en la respuesta que pueden derivarse del contexto. Un faithfulness bajo indica alucinaciones: el modelo está inventando afirmaciones no presentes en los documentos recuperados.
Answer Relevancy
¿La respuesta responde la pregunta original? Se evalúa generando preguntas hipotéticas desde la respuesta y comparando con la pregunta original. Un score alto indica que la respuesta aborda el intent correcto.
Context Precision
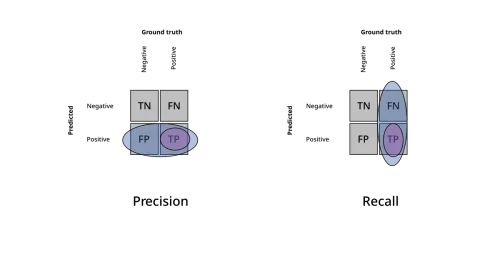
Del contexto recuperado, ¿qué fracción es relevante a la pregunta? Penaliza el retrieval con mucho “ruido”. Útil para tuning del chunk size y del parámetro top-k.
Context Recall
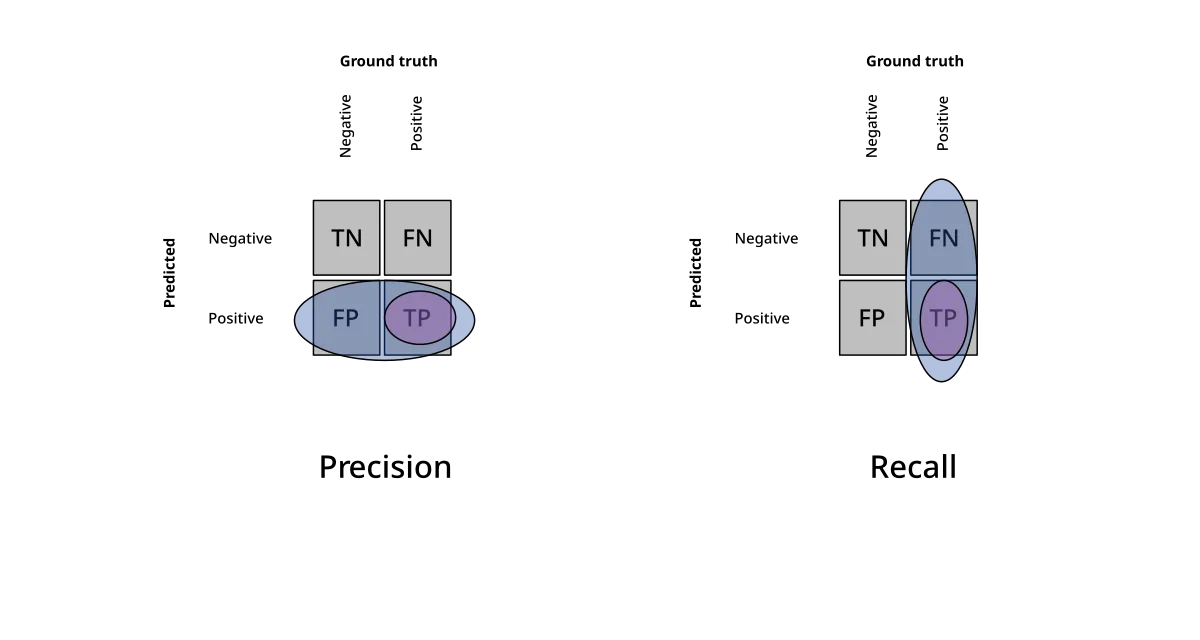
¿Contiene el contexto recuperado toda la información necesaria para responder correctamente? Requiere una respuesta ground truth. Detecta cuándo el retrieval “se deja” información importante fuera.
Uso básico de Ragas
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_precision,
context_recall,
)
from datasets import Dataset
data = {
"question": ["¿Qué es RAG?", "¿Qué ventajas tiene?"],
"answer": ["RAG combina retrieval con generación.", "Menor hallucination..."],
"contexts": [
["RAG (Retrieval Augmented Generation) combina..."],
["Las ventajas de RAG incluyen..."]
],
"ground_truth": ["RAG es una técnica...", "Ventajas principales..."]
}
dataset = Dataset.from_dict(data)
result = evaluate(
dataset=dataset,
metrics=[faithfulness, answer_relevancy, context_precision, context_recall]
)
print(result)Ragas usa OpenAI por defecto pero es configurable con cualquier LLM. Para el retrieval, ver nomic-embed-text para embeddings abiertos y pgvector para el índice vectorial.
Integración en CI
El objetivo es detectar regresiones cuando cambias prompts, modelos, chunk size o estrategia de retrieval:
# .github/workflows/rag-eval.yml
- name: Evaluate RAG
run: |
python evaluate.py --threshold-faithfulness 0.8# evaluate.py
results = evaluate(dataset, metrics=[faithfulness])
if results["faithfulness"] < 0.8:
sys.exit(1) # Falla el CI, bloquea el mergeLos thresholds se establecen desde el baseline histórico. Un cambio que baja faithfulness un 10% es señal de alerta. Integrar evaluación en CI desde el primer día es una inversión que paga dividendos: detecta regresiones antes de producción y da credibilidad al sistema ante stakeholders.
Alternativas a Ragas
Cada framework tiene su foco específico:
TruLens[2]: métricas similares más un triad (context_relevance, groundedness, answer_relevance). Trae un dashboard web integrado y tiene fuerte integración con LangChain. Buena opción si ya usas LangChain como orquestador —ver LangGraph para flujos de agentes.
DeepEval[3]: framework tipo pytest con métricas custom fáciles de añadir. Integración CI/CD lista para usar. El más cercano a los flujos de testing de software habituales.
Giskard[4]: RAG eval más seguridad y detección de bias. Tier comercial con free tier. Útil cuando safety y fairness son requisitos explícitos.
Arize Phoenix[5]: observabilidad para aplicaciones LLM incluyendo evaluación. Open source con opción SaaS.
LLM como juez
La mayoría de frameworks usan un LLM (típicamente GPT-4) para calcular las métricas. Esto tiene implicaciones:
- Ventaja: escalable, puede evaluar múltiples facetas simultáneamente.
- Desventaja: el juez tiene sus propios sesgos, el coste es real y los resultados no son deterministas.
Mejoras emergentes:
- Small LLMs fine-tuned como evaluadores: más baratos y reproducibles.
- Consenso multi-LLM: tres modelos votan y se toma la mayoría.
- Revisión humana periódica: para validar que las métricas automáticas siguen siendo útiles.
Gestión del coste de evaluación
Evaluar 500 preguntas con GPT-4 sobre cuatro métricas implica unas 6000 llamadas LLM (~$60-300 por evaluación completa). Estrategias para controlarlo:
- Subset mode en CI: 50 preguntas por PR, evaluación completa solo en releases.
- Evaluador más barato para mayoría (GPT-4o mini), GPT-4 para los casos críticos.
- Cachear resultados: si el dataset y el modelo no cambian, reutilizar la evaluación anterior.
El dataset de evaluación
El activo más valioso no son las herramientas sino el dataset de evaluación:
- Extraer preguntas reales de logs de usuarios en producción.
- Anotar ground truth con expertos de dominio.
- 50-500 ejemplos es razonable para empezar.
- Incluir edge cases: preguntas ambiguas, out-of-scope, multi-step.
Las herramientas son baratas. Un dataset representativo, curado y mantenido, es la diferencia entre métricas que detectan problemas reales y métricas que dan falsa confianza.
Conclusión
Evaluar RAG con rigor es la diferencia entre un sistema que “funciona en la demo” y uno que “funciona en producción”. Ragas ofrece métricas estándar con implementación accesible. TruLens, DeepEval y Giskard son alternativas válidas con distintos focos. Construir un dataset propio representativo es el activo más valioso. Integrar evaluación en CI desde el día 1 es la inversión con mejor retorno en cualquier proyecto RAG serio.




