Cilium y el futuro de la red de contenedores con eBPF
Índice de contenidos
Actualizado: 2026-06-20
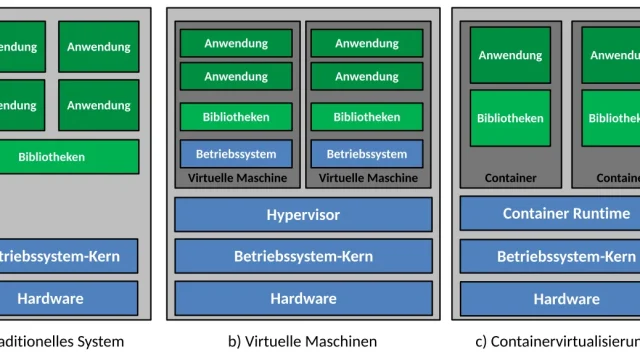
Cilium[1] es el proyecto que está redefiniendo cómo funcionan las redes en Kubernetes. A diferencia de CNIs tradicionales como Calico o Flannel, que se apoyan en iptables, Cilium reemplaza gran parte del stack de red con programas eBPF[2] cargados directamente en el kernel. El resultado: rendimiento significativamente mejor, visibilidad más profunda y políticas de seguridad más expresivas.
Puntos clave
- iptables escala linealmente O(n): con miles de servicios, la CPU de los nodos se satura solo gestionando reglas.
- Cilium carga programas eBPF en el kernel (XDP, tc, socket, cgroup) y usa lookups hash O(1) en lugar de cadenas lineales.
- Los benchmarks documentados muestran 30-50 % menos latencia p95, 2-3x más throughput y hasta 70 % menos CPU de kernel.
- Hubble añade observabilidad en tiempo real sin necesidad de
tcpdumpniconntrack. - La migración desde otro CNI es posible de forma incremental; se recomienda probar primero en staging.
El problema con iptables
iptables ha sido el estándar de red en Linux desde 1998. En clústeres K8s pequeños funciona bien. En clústeres grandes, es un cuello de botella medible por tres razones:
- Escalado O(n). Cada nueva regla añade una entrada al final de la cadena. Con 5.000 servicios, cada paquete pasa por miles de comparaciones.
- Actualizaciones costosas. Cambiar una regla requiere recrear toda la cadena, con impacto en el rendimiento durante el cambio.
- Debugging opaco. Seguir por qué un paquete concreto se aceptó o descartó requiere habilidad profunda.
kube-proxy en modo iptables refleja todos estos problemas: con miles de servicios, la CPU de los nodos se satura solo gestionando reglas, sin procesar ninguna carga útil real.
Qué hace Cilium diferente
Cilium carga programas eBPF en puntos de hook del kernel (XDP, tc, socket, cgroup). Cuando llega un paquete:
- El programa eBPF lo procesa directamente en el kernel, sin pasar por el stack de networking convencional.
- Lookups en tablas hash O(1) reemplazan las cadenas lineales de iptables.
- Sin copia de datos entre espacio de usuario y kernel para operaciones de red.
Los benchmarks documentados muestran:
- Reducción de latencia: 30-50 % menos latencia p95 frente a iptables bajo cargas de service mesh.
- Mayor throughput: 2-3x paquetes por segundo en nodos grandes.
- Menor consumo de CPU: hasta 70 % menos CPU de kernel en clústeres con miles de servicios.
Funcionalidades más allá del CNI básico
Cilium va mucho más allá de “red de pods”. Las capacidades adicionales más relevantes son:
Políticas de red L7
Cilium puede aplicar políticas no solo por IP/puerto (L3/L4), sino por contenido de aplicación (L7). El siguiente ejemplo permite solo GET a /api/v1/.* desde el frontend:
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: "allow-frontend-api"
spec:
endpointSelector:
matchLabels:
app: api
ingress:
- fromEndpoints:
- matchLabels:
app: frontend
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: "GET"
path: "/api/v1/.*"
Con iptables esta granularidad no es posible — requeriría un proxy adicional.
Observabilidad integrada con Hubble
Hubble[3] es la capa de observabilidad de Cilium. Muestra en tiempo real qué paquetes se procesan, qué políticas se aplican y qué conexiones se establecen — un dashboard que reemplaza gran parte del trabajo que antes exigía tcpdump + conntrack. Esta visibilidad complementa directamente lo que Pixie ofrece para observabilidad Kubernetes: mientras Pixie captura telemetría de aplicación, Hubble cubre la capa de red.
Cifrado transparente
Cilium puede cifrar todo el tráfico pod-a-pod con WireGuard o IPsec, activado con un único flag. Sin service mesh adicional.
Modo ambient mesh (integración con Istio)
Istio lanzó ambient mesh[4] eliminando sidecars mediante ztunnel + waypoint. Cilium se integra como CNI que hace posible parte de ese diseño, con rendimiento que sidecars tradicionales no podían igualar.
Cuándo adoptar Cilium
Cilium tiene sentido claro en estos escenarios:
- Clústeres K8s grandes (>50 nodos, >1000 servicios): los beneficios de escala son evidentes.
- Service mesh sin sidecars: Cilium con Hubble + políticas L7 puede sustituir gran parte de Istio tradicional.
- Requisitos de seguridad estrictos: políticas L7, cifrado transparente, identidad fuerte entre servicios.
- Observabilidad profunda necesaria: Hubble da visibilidad que otros CNIs no ofrecen de forma nativa.
Casos donde puede no compensar:
- Clústeres pequeños (<20 nodos): el overhead operativo de Cilium supera los beneficios.
- Kernel antiguo (<4.19): sin kernel moderno, las features de eBPF están limitadas.
- Equipos sin experiencia con eBPF: el debugging de Cilium requiere comprensión de eBPF — curva de aprendizaje real.
Migración desde otro CNI
Migrar de Calico o Flannel a Cilium no es trivial, pero el proceso está bien documentado. Los pasos típicos son:
- Prueba en staging con un node pool dedicado.
- Rolling deployment reemplazando Calico nodo a nodo (la aplicación debe tolerar la reconexión breve por pod).
- Validación de políticas de red existentes: la sintaxis es similar, pero hay diferencias sutiles.
- Activación gradual de features avanzadas (Hubble, cifrado, políticas L7) tras estabilización.
Organizaciones como Datadog, Adobe, Bell Canada y la propia AWS en su servicio EKS[5] han documentado migraciones exitosas.
Para completar el stack de observabilidad sobre Cilium, ver también OpenTelemetry como estándar unificado y el stack Grafana para logs, trazas y métricas. El concepto de eBPF como tecnología de monitorización se extiende también a Pixie — todos comparten los mismos primitivos del kernel.
Conclusión
Cilium no es solo otro CNI: es un cambio arquitectónico que pone eBPF en el centro del networking de Kubernetes. Para clústeres grandes o con requisitos avanzados de seguridad y observabilidad, es difícil justificar no adoptarlo. Para clústeres pequeños, la recomendación es conocer el proyecto y estar preparado para la transición cuando el crecimiento lo justifique.