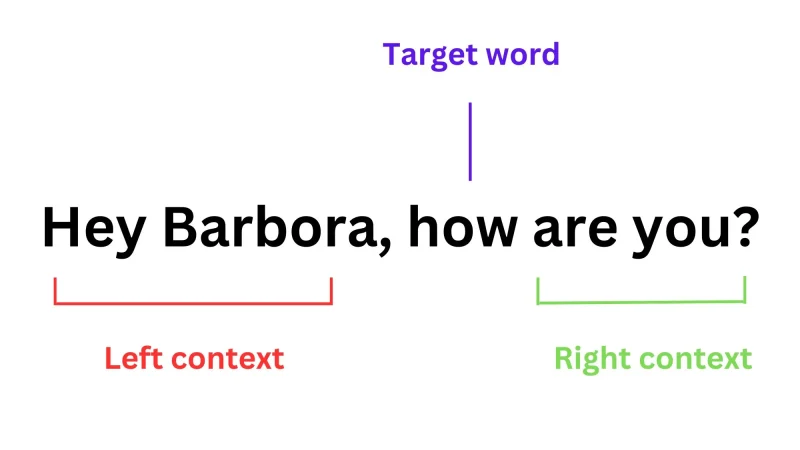
Skills package reusable capabilities; subagents isolate bounded-task execution. Together they form the most effective pattern for composing complex agents in 2026.
Using an LLM to judge another LLM became widespread in 2024 and remains, in 2026, the only scalable way to evaluate qualitative quality in LLM systems. It is reliable when judge-human correlation exceeds 0.7 on 30 cases and gets recalibrated quarterly; below that threshold, do not trust the number.
Opus 4.7 launched as Anthropic's most capable model, with emphasis on long-horizon agentic work. After two months of intensive use, these are the practical changes versus Opus 4.6.
The first invoice for a production agent usually runs double or triple the estimate. This article walks through five real levers, in priority order, caching, routing, context control, batching, and telemetry, to cut cost without touching perceived quality.
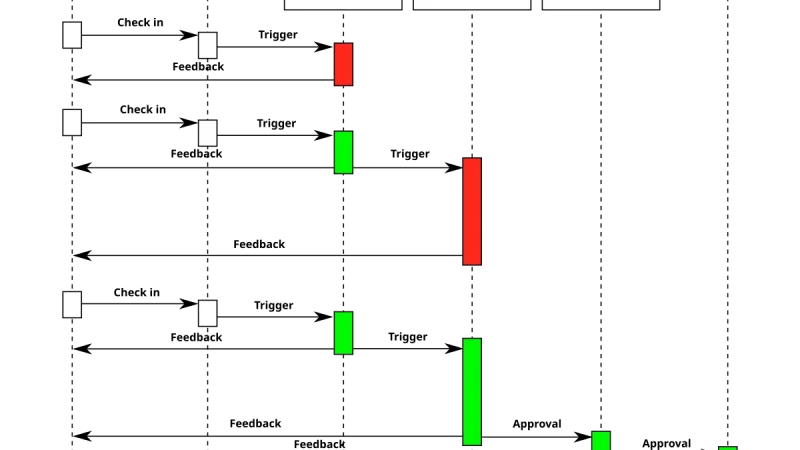
AI agents fail in production, and what matters is how you respond in the first twenty minutes. This runbook covers severity classification, isolating before investigating, purging contaminated memory, communicating without inventing facts, and turning every incident into a regression test before closing it as done.
LLM red teaming has gone from an esoteric activity to a mandatory practice. With the OWASP Agentic Top 10 and the CSA Agentic AI Red Teaming Guide converging on shared vocabulary, this is the operational playbook any team deploying agents needs to have.
Después de año y medio llenando tableros con agentes en producción, la pregunta que separa equipos que envían fiable de los que van a ciegas sigue siendo la misma: ¿cómo mides que el agente está funcionando?
El concepto de Agent OS pasó del slide al despliegue en 2025. Seis meses en producción dejan patrones visibles: qué arquitecturas funcionan, dónde se rompe el modelo y qué aporta frente a correr agentes sobre pila existente.
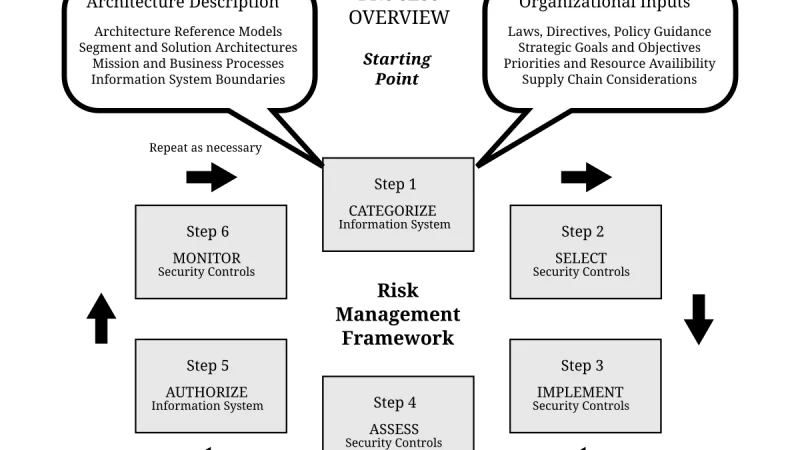
After two years of pilots and a year of agents in production, governance has moved from an aspirational committee to an operational control. What audits ask for, what broke in 2025, and which guardrails absorb most incidents.
Durante 2025 cientos de equipos pusieron agentes IA en producción real. A principios de 2026, con datos suficientes, emergen lecciones consistentes sobre qué falla, qué funciona, cuánto cuesta y qué tareas no encajan. Repaso ordenado para equipos que empiezan ahora.
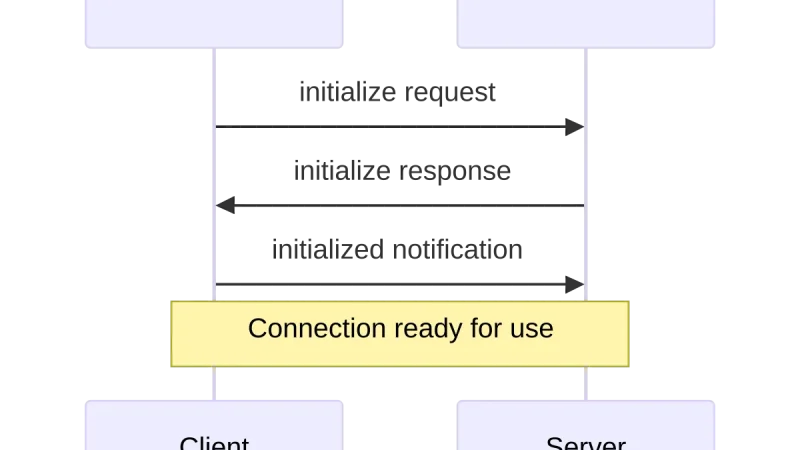
Twenty months after the initial announcement, Model Context Protocol went from curiosity to de-facto standard among agent clients and servers. What is available, which servers are worth it, which problems remain open, and how it compares to earlier protocol maps.
Anthropic publicó Haiku 4.5 en octubre de 2025 y el modelo ha madurado rápido: rendimiento cercano a Sonnet 4 en tareas estructuradas a un tercio del coste, ventana amplia y latencia baja. Es la pieza que faltaba para desplegar agentes a escala sin quemar presupuesto.
After two years watching every product invent its own interface for talking to an agent, by January 2026 a stable design consensus is emerging about which patterns work, which do not, and what the average user already expects. Time to write down what has settled.
Six months after A2A landed at the Linux Foundation, and after several implementation cycles from Google, Microsoft, and open projects, what version 1 of the protocol means and whether it is safe to build on yet.
With MCP solving the agent-to-tool layer, a parallel problem surfaces: how do two agents from different vendors communicate with each other. Google's Agent2Agent protocol, donated to the Linux Foundation in June 2025, tries to fill that gap with an open standard.
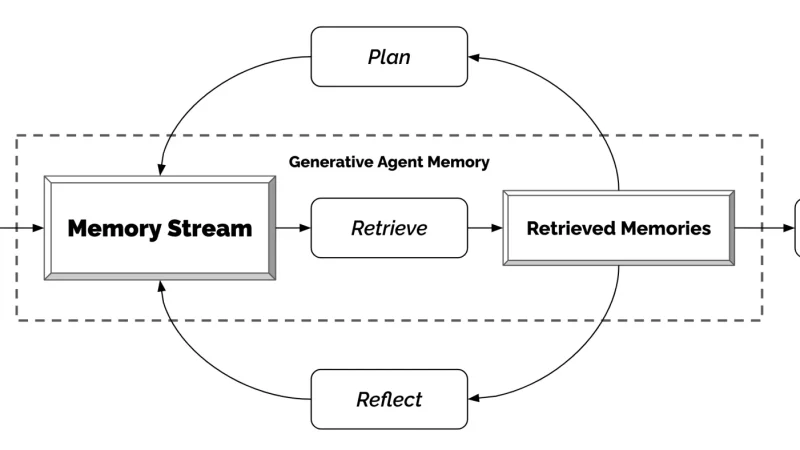
Agents that chain calls to models, tools and memory are hard to debug without instrumentation designed for them. After a long year running agents in production, I cover what to measure first, which standards are consolidating, and which costly mistakes are avoided by getting the traces right from the start.
Casi nueve meses después del lanzamiento de Computer Use, algunos equipos lo han llevado a producción para tareas reales. Dónde funciona, dónde todavía no conviene, y qué patrones están emergiendo para que un agente que maneja ratón y teclado no acabe siendo más problema que solución.
Los editores de código han empezado a incorporar MCP como cliente nativo: VS Code, Zed, Cursor y varios forks de Neovim. Esto cambia la forma en que el agente accede al contexto del proyecto y abre preguntas prácticas sobre qué servidores activar y cómo configurarlos sin abrir puertas.
AI agents are starting to earn a real place in continuous integration pipelines: reviewing diffs, proposing fixes, generating missing tests. Six months of real-world use to separate the patterns that work from the ones that end up costing more time than they save.
A year after chat stopped being the only acceptable way to talk to an agent, UI patterns built specifically for agent tasks are emerging. I go through the ones starting to stick and the ones that are just cycle fashion.
Seis meses después de que MCP se volviera el protocolo común de integración de agentes, el catálogo comunitario supera el millar de servidores. Repaso cuáles uso a diario, cuáles son ruido y cómo separarlos sin caer en la trampa de la novedad.
Y Combinator's W25 and S25 cohorts show a historic tilt toward vertical agents and developer tools, with outcome-based pricing emerging as a new model. I break down the visible patterns, the business models on display, and what founders operating outside Silicon Valley should copy from this reading of the batch.
6 min6964.3
We use first- and third-party cookies to analyze site traffic. You can accept them, reject them, or configure your choice.
Learn more about cookies
Cookie preferences
NecessaryEssential for the site to work. Always on.
AnalyticsHelp us understand how the site is used (Google Analytics).