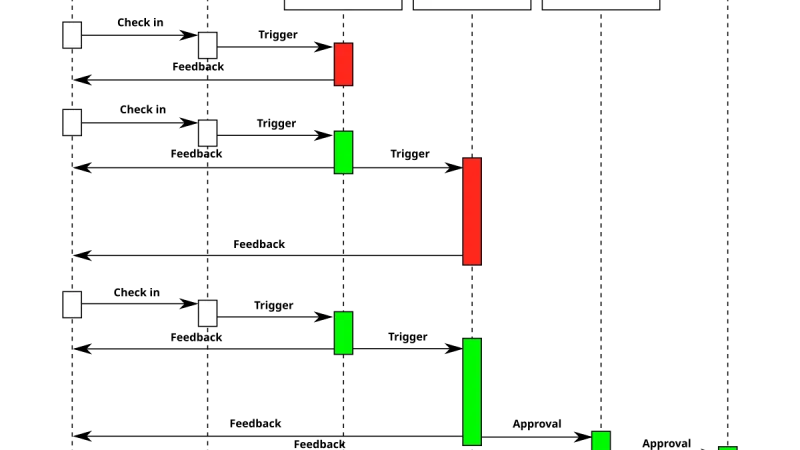
Los agentes de IA empiezan a tener un hueco serio en los pipelines de integración continua: revisar diffs, proponer arreglos, generar tests que faltan. Seis meses de uso real para separar los patrones que funcionan de los que acaban costando más tiempo del que ahorran.
Semgrep ha crecido hasta convertirse en uno de los análisis estáticos más pragmáticos del ecosistema. Reflexión sobre por qué funciona donde otros SAST fracasan y cómo meterlo en un pipeline sin que se convierta en ruido.
Cómo los dataframes y los pipelines de Apache Spark permiten procesar grandes volúmenes de datos de forma eficiente, distribuida y optimizable en clústeres.
4 min1714.4
We use first- and third-party cookies to analyze site traffic. You can accept them, reject them, or configure your choice.
Learn more
Cookie preferences
NecessaryEssential for the site to work. Always on.
AnalyticsHelp us understand how the site is used (Google Analytics).