Artificial Intelligence
RAG with Postgres and pgvector in production: from PoC to SLO
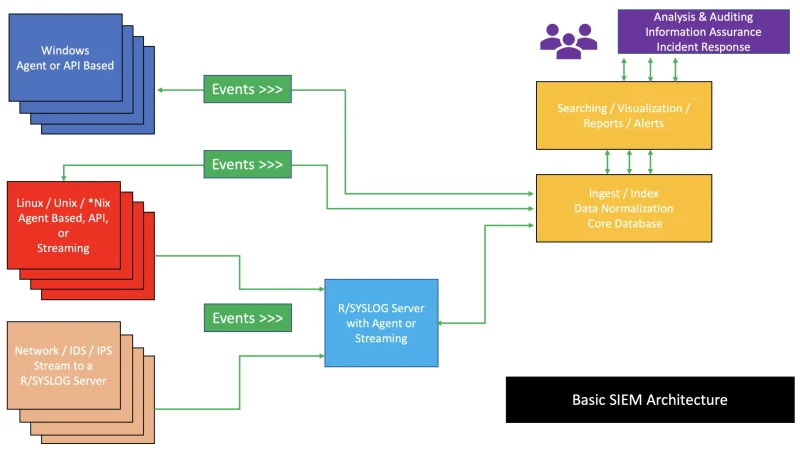
Embeddings, HNSW indexing, reranking, evaluation, context window, latency under load. Full stack with code and measurable SLOs.
Category
Methodologies that respect your time: lightweight processes for small teams.
Embeddings, HNSW indexing, reranking, evaluation, context window, latency under load. Full stack with code and measurable SLOs.
Full tutorial: tool use, streaming, prompt caching, observability, and your own MCP server. Reference repo included.
Using an LLM to judge another LLM became widespread in 2024 and remains the only scalable way to evaluate qualitative quality. The mature question is when to trust those numbers.
Opus 4.7 se lanzó como el modelo más capaz de Anthropic con énfasis en trabajo agéntico de horizonte largo. Tras dos meses de uso intensivo, estos son los cambios prácticos frente a Opus 4.6.
La primera factura de un agente en producción suele ser más alta de lo que el equipo esperaba. Este artículo recoge las palancas reales para controlar el coste sin sacrificar calidad.
Después de un año midiendo cuáles de las herramientas DevOps con IA integradas realmente aportan y cuáles son humo, este es el stack que se queda en mi flujo diario.
Los agentes fallan. La pregunta no es si, sino cómo y qué haces en los primeros veinte minutos. Este es el runbook que distingue un incidente contenido de una reputación dañada.
El red teaming de modelos de lenguaje ha pasado de actividad esotérica a práctica obligatoria. Con OWASP Agentic Top 10 y CSA Agentic AI Red Teaming Guide convergiendo en un vocabulario común, este es el manual operativo que cualquier equipo que despliegue agentes necesita tener.
Después de año y medio llenando tableros con agentes en producción, la pregunta que separa equipos que envían fiable de los que van a ciegas sigue siendo la misma: ¿cómo mides que el agente está funcionando?
El marco RICE es una metodología de priorización desarrollada por Intercom para decidir qué iniciativas entran en una hoja de ruta y en qué orden.
Prompt engineering ha pasado de ser una colección de trucos virales a una disciplina con patrones reproducibles, librerías dedicadas y herramientas de observabilidad.
Dos años después de los estándares NIST finales, la migración post-cuántica ya no es hipótesis. Qué se ha migrado de verdad, qué sigue atascado, dónde están los problemas operativos reales y cómo se ven los plazos desde abril de 2026.
Tras dos años de pilotos y un año de agentes en producción, la gobernanza ha pasado de comité aspiracional a control operativo. Qué piden las auditorías, qué rompió en 2025 y qué barandillas están absorbiendo la mayoría de los incidentes.
Durante 2025 cientos de equipos pusieron agentes IA en producción real. A principios de 2026, con datos suficientes, emergen lecciones consistentes sobre qué falla, qué funciona, cuánto cuesta y qué tareas no encajan. Repaso ordenado para equipos que empiezan ahora.
Tres años después de que platform engineering se convirtiera en palabra de moda, el polvo ha caído. Unas pocas empresas tienen plataformas internas que de verdad aceleran al desarrollo, muchas montaron un portal Backstage vacío y algunas volvieron a DevOps clásico. Análisis de qué distingue a las que ganaron.
La factura de IA en las empresas ha dejado de ser anecdótica. Entre tokens de modelos frontera, GPUs reservadas que nadie usa y pipelines RAG con cachés mal configuradas, muchos equipos pagan diez veces lo que deberían. Guía de FinOps específico para IA sin relatos promocionales.
Tras dieciséis meses desde la primera versión de computer use de Anthropic y el empuje paralelo de browser-use, OpenAI Operator y Gemini Control, los agentes que manejan navegador y escritorio han pasado de demo a flujos reales. Toca revisar qué patrones sobreviven cuando los ejecutas todos los días en producción.
Una selección de postmortems publicados entre 2025 y 2026 por equipos que operan sistemas con IA en producción revela patrones repetidos: fallos en guardrails, deriva silenciosa de modelos, dependencia oculta del proveedor y una colección de sustos que vale la pena destilar.
Dos años de experimentación con modelos generativos aplicados a descubrimiento de producto han dejado prácticas concretas útiles y otras tantas que se descartan. Un repaso honesto de qué ha funcionado, qué ha fracasado y cómo incorporar IA al ciclo de discovery sin corromper sus fundamentos.
A principios de 2026, varias plataformas de orquestación incluyen carbon-aware scheduling como opción por defecto o muy visible. Con meses de datos reales, toca evaluar si la promesa de reducir emisiones sin dañar rendimiento se cumple y en qué escenarios.
Los cuadros de mando con IA llevan un par de años prometiendo detección de anomalías mágica y causa raíz automática. La realidad es más modesta pero también más útil, si se sabe separar el ruido del valor real. Repaso honesto de qué funciona y qué no.
Los modelos grandes de lenguaje llevan dos años prometiendo documentar código, APIs y arquitecturas sin esfuerzo. Después de ver docenas de proyectos intentarlo, hay patrones claros de dónde funciona y dónde acaba siendo una deuda más.
Los frameworks de guardrails prometen filtrar entradas y salidas de modelos de lenguaje para bloquear fugas de datos, contenido dañino o alucinaciones. Tras evaluar cuatro de los más populares en producción, repaso qué hacen realmente, qué coste en latencia y factura añaden y cuándo compensan frente a controles más simples.
Los agentes que encadenan llamadas a modelos, herramientas y memoria son difíciles de depurar sin una instrumentación pensada para ellos. Después de un año largo operando agentes en producción, repaso qué hay que medir primero, qué estándares están consolidándose y qué errores caros evita tener trazas bien hechas desde el inicio.
Después de tres años de expansión y de un ecosistema sobreexcitado alrededor del término, platform engineering llega a 2025 en una fase de consolidación. Las plataformas internas que sobreviven son las que entendieron su función real, las que confundieron el nombre con la solución están desmantelando sus equipos o recortándolos drásticamente.
Probar sistemas que incluyen modelos de lenguaje rompe la primera regla del testing: la misma entrada da la misma salida. Analizo las estrategias que han funcionado tras un año largo integrando IA en productos reales, por qué los tests deterministas tradicionales no bastan y cómo plantear un cinturón de pruebas que capture regresiones sin bloquearse en la varianza.
Hace tres años era una curiosidad académica. Hoy, planificar cargas por intensidad de carbono de la red eléctrica es una opción integrada en Kubernetes, en los servicios de contenedores de los grandes proveedores y en varios schedulers de CI. Repasamos qué cambió y qué hacer con esa capacidad.
Los equipos de producto están tentados de sustituir entrevistas y tests reales por síntesis de IA. Dos años de experiencia ya permiten separar dónde la IA ayuda de verdad y dónde genera una falsa sensación de entender al usuario.
OpenSSH lleva un año ofreciendo intercambio de claves híbrido con ML-KEM. La pregunta ya no es si migrar, sino cómo hacerlo sin romper clientes antiguos ni dejar huecos en la cadena de conexión.
Casi nueve meses después del lanzamiento de Computer Use, algunos equipos lo han llevado a producción para tareas reales. Dónde funciona, dónde todavía no conviene, y qué patrones están emergiendo para que un agente que maneja ratón y teclado no acabe siendo más problema que solución.
Los agentes de IA empiezan a tener un hueco serio en los pipelines de integración continua: revisar diffs, proponer arreglos, generar tests que faltan. Seis meses de uso real para separar los patrones que funcionan de los que acaban costando más tiempo del que ahorran.
El profiling continuo ha salido del terreno experimental y se ha vuelto una herramienta habitual en sistemas con tráfico real. Repaso qué aporta eBPF frente a instrumentación clásica, qué cuesta y cuándo compensa instalarlo.
Han pasado siete años desde que Google publicó el Workbook, y buena parte del libro no ha envejecido. Repaso los patrones que de verdad aplicamos en equipos pequeños y los que resultaron ser cultura de campus.
Llevar FinOps a cargas de IA obliga a repensar lo que funcionaba en nube tradicional. Los costes no vienen solo de instancias EC2; vienen de tokens, llamadas de herramientas, reindexados y experimentos fallidos.
Un sistema RAG sin evaluación continua se degrada en silencio. Los índices cambian, los modelos se actualizan, los usuarios preguntan cosas nuevas. Este es un repaso práctico de qué métricas vigilar y cómo montar el cuadro de mando que avisa antes del incidente.
Después de años acumulando SBOMs, el cuello de botella es filtrar qué CVEs afectan de verdad. VEX aparece como la pieza que convierte el ruido en señal, y en 2025 empieza a tener adopción real en pipelines de supply chain.
Los agentes de IA han pasado de ser un tema de laboratorio a tener SDKs serios en tres grandes proveedores. Reflexión sobre cómo pasar de la demo llamativa a un caso de uso interno que mueva una métrica real.
Semgrep ha crecido hasta convertirse en uno de los análisis estáticos más pragmáticos del ecosistema. Reflexión sobre por qué funciona donde otros SAST fracasan y cómo meterlo en un pipeline sin que se convierta en ruido.
Dos años después de que Zero Trust dejase de ser palabra de marketing, toca mirar cómo conecta con el SIEM del día a día. Reflexión sobre señales útiles, ruido evitable y decisiones que de verdad cambian la postura de seguridad.
Con las primeras obligaciones del AI Act europeo ya en vigor, la gobernanza de la IA en empresa deja de ser teórica. Qué comités montar, qué políticas escribir y qué auditar, desde la experiencia de varias implantaciones.
Dependabot y Renovate persiguen lo mismo pero con filosofías distintas. Comparo ambos tras años usándolos en proyectos propios y de cliente, y repaso cuándo uno aprieta mejor y cuándo el otro se adapta más al flujo del equipo.
Hace un año los pesos abiertos eran una apuesta; hoy son una opción de producción real. Repaso lo que ha funcionado, lo que no y cómo están encajando Llama, DeepSeek, Qwen y Mistral en arquitecturas empresariales que antes dependían de APIs cerradas.
Dos años después de convivir con asistentes de IA en el editor, los hábitos se han asentado. Reflexión sobre qué ha cambiado en el día a día de programar, qué se ha aprendido y qué quedaba por descubrir.
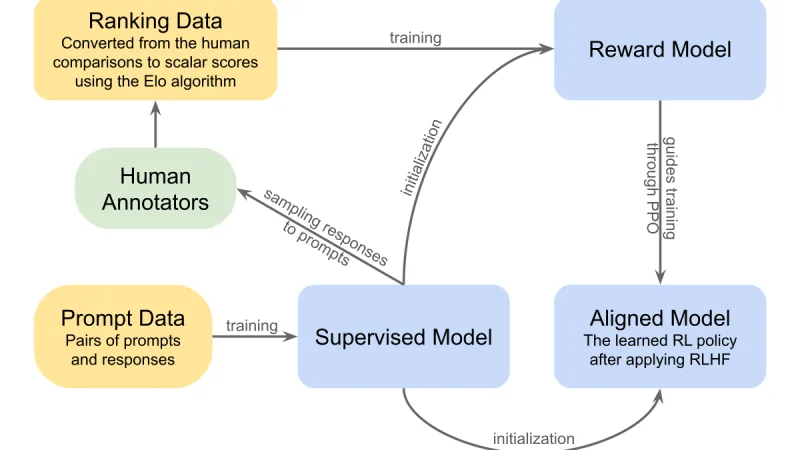
Tres años después de que RLHF se hiciera popular, el paisaje del alineamiento de modelos es más rico. Repaso de RLHF, DPO y los métodos más recientes como KTO o ORPO, con criterios para elegir.
SLSA lleva año y medio en su versión 1.0 y el ecosistema ha tenido tiempo de adoptarlo. Repaso de lo que funciona, lo que sigue costando y por dónde tiene sentido empezar.
Medir la calidad de un sistema RAG es más sutil de lo que parece. Métricas, conjuntos dorados y los errores más comunes al evaluar.
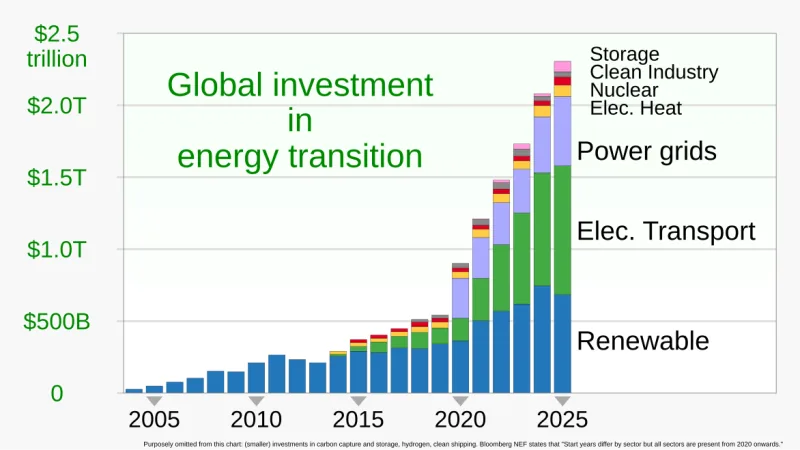
El software consume energía. Reducir su huella de carbono no es solo virtud — es ahorro operativo. Ocho principios prácticos aplicables desde mañana.
Las aplicaciones LLM necesitan observabilidad específica: trazas de prompt/respuesta, costes de tokens y métricas de calidad. Herramientas y patrones para 2024.