Kubernetes 1.35 llega a GA en 2026 consolidando mejoras gestadas durante tres versiones. Este es el balance desde la operación diaria: qué usar, qué probar y qué evitar.
Skills package reusable capabilities; subagents isolate bounded-task execution. Together they form the most effective pattern for composing complex agents in 2026.
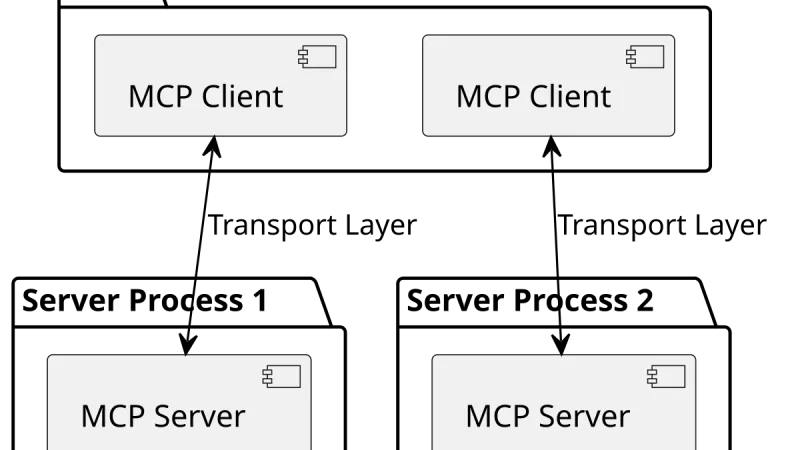
The Model Context Protocol, proposed by Anthropic in late 2024 and adopted through 2025-2026 by every major vendor, has proven operational patterns. This is the state of the art.
Tres años después del boom inicial, el RAG en producción ha convergido en patrones híbridos que combinan búsqueda densa, léxica y reranking. Estos son los que sobreviven al paso del tiempo.
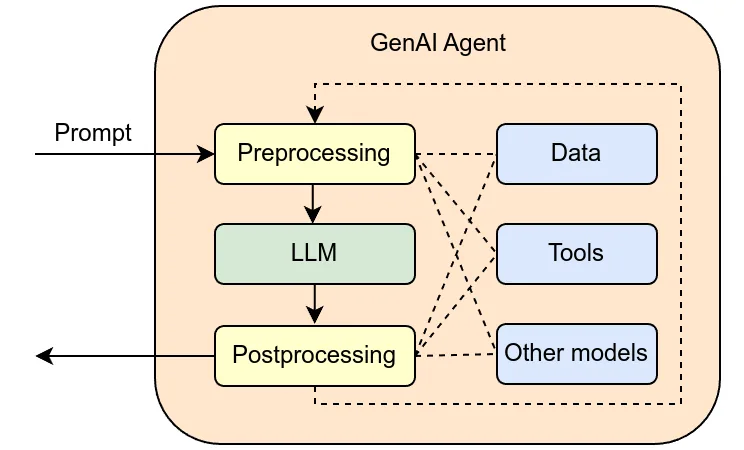
El concepto de Agent OS pasó del slide al despliegue en 2025. Seis meses en producción dejan patrones visibles: qué arquitecturas funcionan, dónde se rompe el modelo y qué aporta frente a correr agentes sobre pila existente.
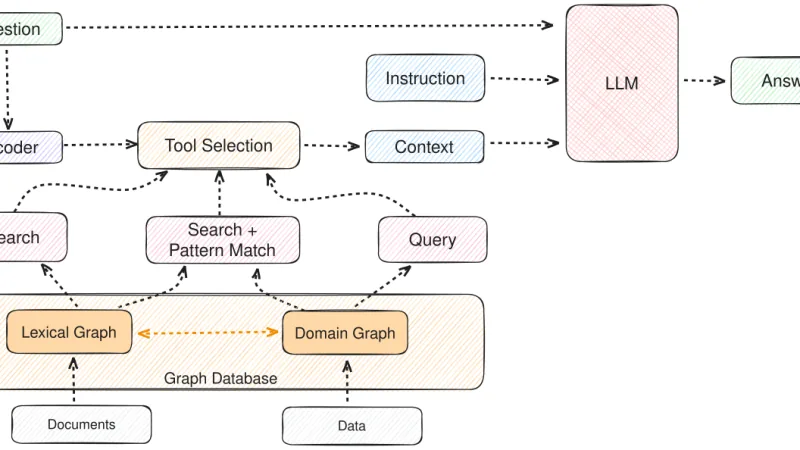
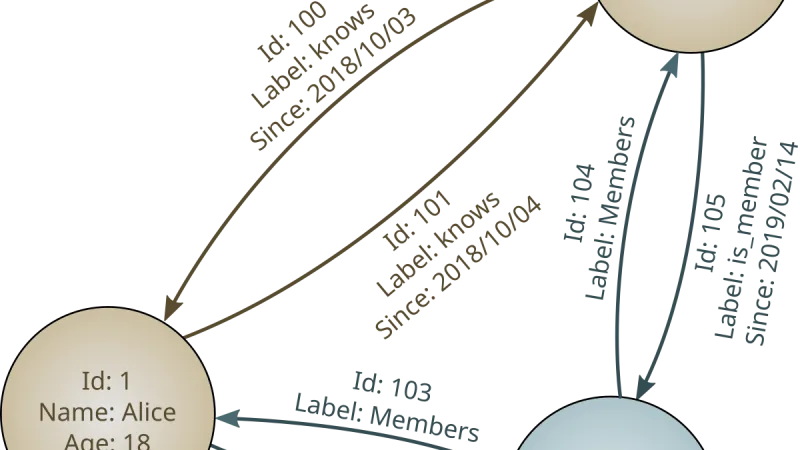
Un año después de que GraphRAG saliera de laboratorio, queda una estadística clara: funciona donde la información corporativa tiene relaciones densas, falla donde solo hay documentos sueltos. Patrones, costes y decisiones de arquitectura que han sobrevivido.
Dieciséis meses después del anuncio inicial, Model Context Protocol pasó de curiosidad a estándar de facto entre clientes y servidores de agentes. Qué hay disponible, qué servidores merecen la pena, qué problemas siguen abiertos y cómo se parece al mapa de protocolos anteriores.
Tres años después de que platform engineering se convirtiera en palabra de moda, el polvo ha caído. Unas pocas empresas tienen plataformas internas que de verdad aceleran al desarrollo, muchas montaron un portal Backstage vacío y algunas volvieron a DevOps clásico. Análisis de qué distingue a las que ganaron.
Seis meses después de que A2A llegara a la Linux Foundation, y tras varios ciclos de implementación por parte de Google, Microsoft y proyectos abiertos, qué significa la versión 1 del protocolo y si ya es seguro construir sobre él.
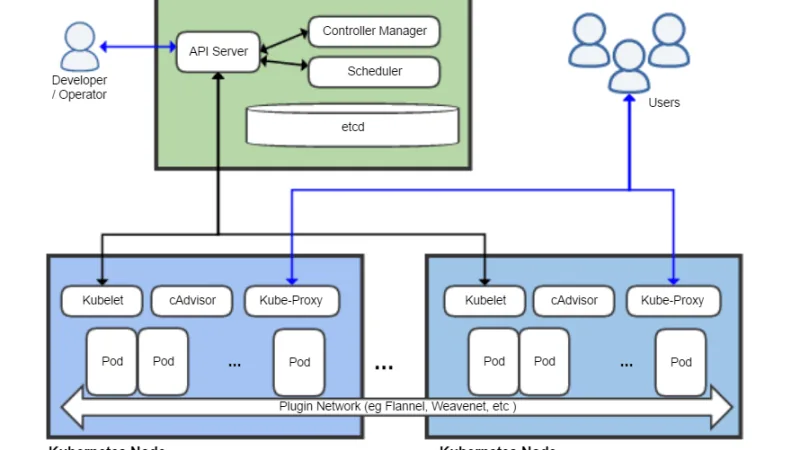
Con 1.34 liberado en agosto de 2025 y el ciclo de 1.35 en su última fase de congelación de funciones, qué llegará estable, qué quedará en beta, qué nos interesa a quienes mantenemos clústeres pequeños o medianos y qué podemos ignorar sin culpa hasta el siguiente ciclo.
La integración de WebAssembly dentro de containerd como tiempo de ejecución alternativo ha madurado. Ya es posible desplegar cargas mixtas Linux y Wasm en el mismo clúster de Kubernetes con argumentos operativos sólidos. Cuándo compensa y cuándo no.
Con MCP resolviendo la conexión entre agente y herramientas, el siguiente cuello de botella aparece: cómo hablan entre sí dos agentes de distintos proveedores. Agent2Agent de Google, donado a la Linux Foundation en 2025, intenta ocupar ese hueco.
gVisor interpone un kernel en espacio de usuario entre el contenedor y el anfitrión. Después de años en producción en Google y adopción creciente en plataformas serverless, merece una lectura honesta sobre cuándo compensa frente a microVMs y runtimes clásicos.
Un proxy con caché delante de un modelo de lenguaje puede reducir la factura de tokens de forma significativa, pero introduce riesgos sutiles si el diseño no es cuidadoso. Qué tipos de caché funcionan en producción, dónde están las trampas habituales y cómo integrarlos sin degradar la experiencia.
Un enrutador de inferencia decide qué modelo atiende cada petición en función de coste, latencia y complejidad. Bien diseñados reducen la factura de tokens sin que el usuario perciba degradación; mal diseñados introducen fallos sutiles difíciles de depurar.
TigerBeetle es una base de datos distribuida escrita en Zig y especializada en un tipo concreto de carga: contabilidad por partida doble de altísimo volumen con garantías fuertes de consistencia. No pretende sustituir a Postgres; pretende ser la pieza correcta cuando el problema es contar transacciones financieras a ritmo de millones por segundo sin fallos sutiles.
Después de tres años de expansión y de un ecosistema sobreexcitado alrededor del término, platform engineering llega a 2025 en una fase de consolidación. Las plataformas internas que sobreviven son las que entendieron su función real, las que confundieron el nombre con la solución están desmantelando sus equipos o recortándolos drásticamente.
Tras la adquisición por Microsoft en 2019, Citus vivió un limbo comercial que terminó con Microsoft abriendo el código completo en 2022. Tres años después, la extensión de particionado para Postgres ha madurado y ofrece una ruta práctica para escalar sin abandonar el motor que ya conoces. Un repaso honesto.
SQLite lleva años ganando terreno en servidores reales gracias a WAL, a proyectos como Litestream y libSQL, y a hardware con discos rápidos. Repaso los patrones que siguen funcionando después de varios años de uso, los que no, y por qué el tamaño medio de una aplicación web se come ya sin despeinarse.
Tras años de prometer un lakehouse abierto, la combinación de Apache Iceberg con catálogos REST y dbt encima ha cuajado en 2025 como la pila de referencia. Analizo qué resuelve, dónde sigue doliendo y por qué la separación limpia entre tabla, motor y transformación importa más de lo que parece.
DuckDB lleva dos años colándose en las arquitecturas de datos sin hacer ruido. Ya no es solo la base de datos embebida para analítica local: en 2025 está apareciendo en casos concretos de empresa donde reemplaza a piezas mucho más caras. Un recorrido por patrones reales.
El término Agent OS lleva un año ganando tracción entre investigación y producto. Describe una capa que va más allá de una biblioteca de agentes: planificador, gestión de contexto, memoria persistente y aislamiento. Una lectura del estado real de ese concepto.
Wolfi cumple tres años como proyecto público y se ha convertido en la base de imágenes de contenedor de Chainguard y de buena parte de la industria que persigue cadenas de suministro limpias. Revisión con rodaje de lo que aporta frente a Alpine y Debian slim.
Kata Containers lleva años prometiendo contenedores con aislamiento de máquina virtual sin sacrificar la ergonomía de Docker. En otoño de 2025 el proyecto se acerca a su versión 3.10 con una historia técnica por fin coherente y un nicho claro donde adoptarlo de verdad.
Model Context Protocol cumple diez meses desde su anuncio de Anthropic y ya no es una propuesta: hay cientos de servidores, implementaciones cruzadas entre proveedores y un registro público. Repaso de qué ha funcionado, qué sigue flojo y por qué 2025 marca el paso de curiosidad a infraestructura básica.
Las bases de datos SQL distribuidas han pasado de promesa a realidad operativa. YugabyteDB y CockroachDB lideran el segmento desde ángulos distintos. Elegir una sobre la otra exige entender qué compromete cada diseño y qué se paga por escalar horizontalmente.
Redpanda promete compatibilidad con el protocolo Kafka pero sin JVM, sin ZooKeeper y con arquitectura thread-per-core. En 2025 ya hay despliegues serios en producción. Merece la pena entender dónde compensa el cambio y dónde no.
Kubernetes 1.34 llega con ajustes en planificador, validación declarativa y progresos en soporte dinámico de recursos. Un repaso a lo que importa actualizar rápido, lo que puede esperar, y las deprecaciones que conviene leer con calma.
Redis 8.2 incorpora búsqueda vectorial como tipo de dato nativo. La pregunta no es si funciona, sino si sustituye a un motor dedicado como Qdrant, Weaviate o pgvector en cargas reales con millones de vectores y latencias exigentes.
Kafka 4.0 llegó en marzo con la promesa cumplida: el clúster se autoadministra sin ZooKeeper. Después de meses operando clústeres KRaft y de la migración obligada, qué cambia de verdad, dónde duelen las diferencias y qué hay que saber antes de migrar.
Los formatos de tabla abiertos sobre lagos de datos han pasado de curiosidad a columna vertebral de muchas arquitecturas analíticas. Delta Lake 4.0 e Iceberg 1.9 son los dos con más peso en 2025. Revisamos dónde están y qué criterios conviene aplicar para elegir entre ellos.
Seis meses después de la GA de containerd 2.0 hay suficiente camino recorrido para evaluar la migración desde 1.x. Repasamos compatibilidad, cambios de API, trampas habituales y cuándo compensa planificar el salto.
Firecracker lleva años detrás de Lambda y Fargate, pero su adopción fuera de AWS se ha acelerado. Repaso cuándo compensa cambiar containers por microVMs, qué aportan frente a gVisor y dónde siguen las asperezas.
Kubernetes 1.32 Penelope se publicó en diciembre y lleva varios meses rodando en clusters. Es buen momento para mirar qué cambios han envejecido bien, cuáles han generado trabajo extra y qué aprendizajes llevarse al salto hacia 1.33.
PostgreSQL 17 llegó en septiembre con mejoras silenciosas del planificador. Seis meses en producción confirman que los escaneos SAOP, el streaming I/O y los anti-joins han cambiado planes de consulta reales sin tocar una línea de SQL.
Valkey 8.1 salió el 31 de marzo y marca el momento en que la alternativa comunitaria de Redis deja de ser experimento. Cuenta una migración real: qué cambió, qué se mantuvo igual, y dónde hubo sobresaltos.
La release 1.33 llega el 23 de abril y el sneak peek oficial de marzo ya deja ver las líneas fuertes: in-place resize GA, sidecars terminando de madurar y un puñado de deprecaciones importantes.
Desde que Microsoft abrió GraphRAG, el patrón de usar grafos sobre tus propios datos ha pasado de experimento académico a técnica con aplicaciones prácticas. Reflexión sobre cuándo compensa, cómo se monta y qué errores se repiten.
Coolify promete la experiencia de Vercel o Heroku desplegada en tus propios servidores. Tras varios meses usándolo en VPS de producción, cuento dónde brilla, dónde cojea y para qué perfil de equipo tiene sentido.
GraphRAG lleva un año en uso empresarial real. Balance de qué tipos de preguntas resuelve mejor que el RAG clásico, qué cuesta operarlo y cuándo la complejidad extra compensa.
Cloudflare Workers cumple ocho años y se ha convertido en una plataforma de aplicaciones completa. Repaso de qué ofrece hoy, qué limitaciones persisten y en qué tipo de proyecto tiene sentido apostar.
Montar un sistema de ficheros compartido entre varios servidores sin NFS ni complicaciones de kernel. Recorrido por la instalación de JuiceFS usando S3 como backend y PostgreSQL como metadatos.
Anthropic presenta MCP, un estándar abierto para conectar modelos de lenguaje con datos y herramientas. Qué resuelve, cómo se diferencia del function calling y por qué puede convertirse en el LSP de los agentes.
MariaDB 11.7 trajo vector search nativo, mejoras en JSON y optimizaciones de rendimiento. Cómo se diferencia de MySQL 8 y cuándo sigue siendo la elección correcta.
DuckDB es el motor analítico embebido que ha cambiado el panorama. Lee Parquet y CSV directamente, vectoriza la ejecución y cabe dentro de tu proceso Python. Un repaso a cuándo sustituye de verdad a un data warehouse.
Kubernetes 1.30 trae ValidatingAdmissionPolicy en GA, pod scheduling readiness y job success policy. Una release discreta pero útil para quien opera clústeres de verdad.
5 min1564.4
We use first- and third-party cookies to analyze site traffic. You can accept them, reject them, or configure your choice.
Learn more
Cookie preferences
NecessaryEssential for the site to work. Always on.
AnalyticsHelp us understand how the site is used (Google Analytics).