La era del grafo de conocimiento renace con los LLM
Actualizado: 2026-05-03
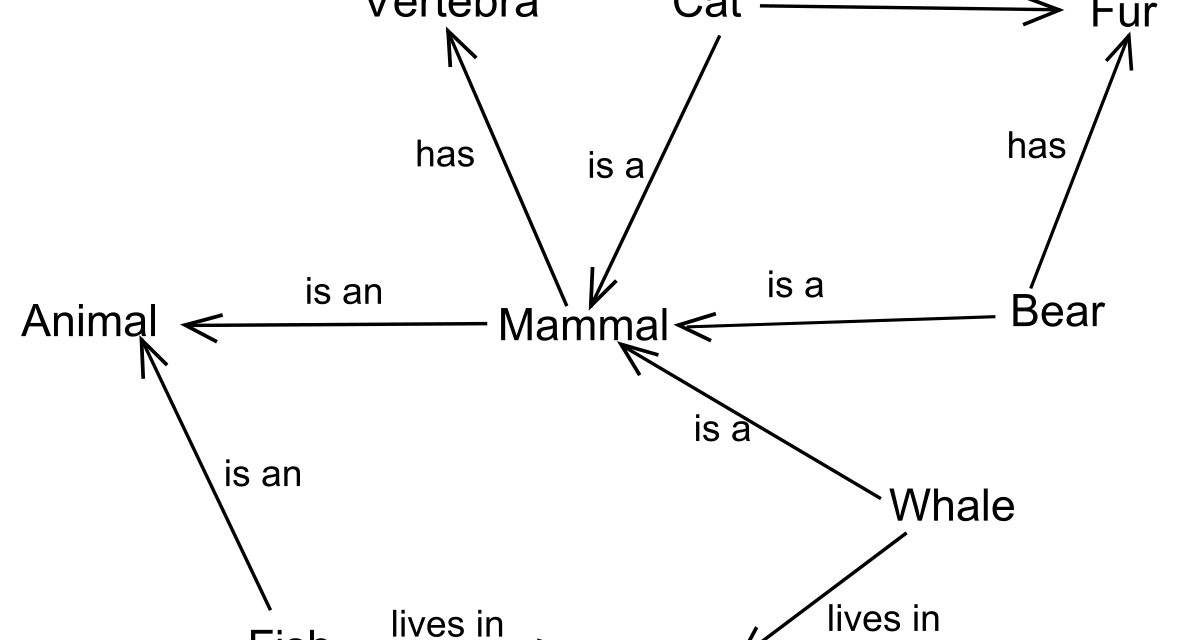
El knowledge graph llevaba una década en un segundo plano: tema de tesis, nicho académico, proyecto interno de Google que nadie fuera supo cómo replicar a escala. En 2025 ha vuelto al primer plano, y la razón es concreta. Los LLM necesitan una capa de anclaje para dejar de alucinar, para razonar sobre datos privados sin reentrenar y para que un agente pueda justificar sus decisiones. Esa capa es, cada vez más, un grafo.
Puntos clave
- Los LLM han derrumbado el coste de construcción de un knowledge graph en dos frentes: extracción de entidades desde texto no estructurado y mantenimiento del esquema sin ontólogo permanente.
- Los cuatro patrones con resultados concretos son: RAG con grafo como backbone, auditoría de razonamiento, memoria estructurada para agentes e integración de fuentes heterogéneas.
- La evaluación de grafos generados por LLM no tiene benchmarks estables; cada empresa inventa su propia métrica.
- Neo4j domina en empresa pero su licencia complica el uso a escala sin pagar; DuckDB, Kuzu y Memgraph atacan el caso embebido.
- El grafo efímero por sesión es el patrón más interesante para evitar el problema difícil de mantener un grafo global actualizado.
Qué cambió respecto a 2015
Hace diez años, construir un knowledge graph empresarial era un proyecto de dos años con un equipo de ontólogos. Se definía un esquema exhaustivo, se cargaban datos con ETL pesado y al final se servía vía SPARQL a tres aplicaciones que nadie usaba. El problema no era la tecnología del grafo, sino el coste de poblar y mantener el esquema.
Los LLM han hundido ese coste en dos frentes. Primero, la extracción de entidades y relaciones desde texto no estructurado pasó de ser un proyecto de NLP clásico con precisión mediocre a una llamada al modelo con prompt bien diseñado. Segundo, el mantenimiento del esquema dejó de requerir un ontólogo permanente: el modelo propone relaciones, un humano valida, el grafo evoluciona.
Microsoft publicó GraphRAG a finales de 2024 y el efecto en la comunidad fue inmediato. Lo que GraphRAG demostró no fue nuevo conceptualmente (anclar generación en grafos es idea vieja), sino que un pipeline moderno de ingesta con LLM puede construir, en horas, un grafo denso desde un corpus corporativo. Ese cambio de economía abrió la puerta a la adopción actual.
Patrones que funcionan en producción
Cuatro patrones están dando resultados concretos en empresas que los han desplegado en el último año:
- RAG con grafo como backbone. En lugar de buscar chunks por similitud vectorial pura, el grafo orienta la recuperación: primero identifica entidades relevantes a la consulta, luego extrae el subgrafo de su vecindad y entrega al LLM un contexto conectado en vez de fragmentos aislados. Para consultas que requieren relacionar varias entidades, el grafo es drásticamente mejor que la similitud. Complementa directamente las prácticas de evaluación continua de RAG.
- Auditoría de razonamiento. Un agente que extrae una conclusión puede citar el camino en el grafo que la sostiene. Esa traza es reproducible y revisable por un humano. Para sectores regulados (banca, salud, legal) esta capacidad de justificar ha pasado de deseable a requisito.
- Memoria estructurada para agentes. En lugar de dejar que el agente acumule texto libre en una memoria conversacional que crece sin control, el agente escribe hechos estructurados en un grafo. Las consultas futuras son deterministas, el coste de token se mantiene bajo y el estado es depurable.
- Integración de fuentes heterogéneas. Un grafo con alias y reconciliación permite unificar la misma entidad cuando aparece con nombres ligeramente distintos en CRM, ERP, helpdesk y emails. Ese trabajo era costoso antes; ahora el LLM propone las reconciliaciones y el grafo las consolida.
Las barreras que siguen en pie
Hay tres fricciones reales que frenan el desarrollo:
- La evaluación es difícil. Medir la calidad de un grafo generado por LLM no tiene benchmarks estables. Cada empresa acaba inventando su propia métrica (precisión de aristas, cobertura de entidades, consistencia temporal) y comparar implementaciones es complicado.
- El mantenimiento en vivo. Un grafo es útil cuando refleja la realidad. Si los datos fuente cambian y el grafo no se actualiza, aparecen contradicciones que confunden al LLM más que ayudarle. Automatizar la detección de cambios y la re-extracción incremental es un problema sin solución estándar todavía.
- La elección de tecnología. Neo4j domina en despliegues empresariales pero su licencia complica el uso a escala sin pagar. TigerGraph y Memgraph compiten en rendimiento de consulta. DuckDB con extensiones de grafo, Kuzu y otros proyectos recientes atacan el caso de grafo embebido. La elección depende de volumen, latencia requerida y si el grafo es efímero (regenerable) o canónico (fuente de verdad).
El caso que me llama la atención
Un patrón especialmente interesante es el grafo efímero por sesión. En lugar de mantener un grafo corporativo canónico, el sistema construye al vuelo un pequeño grafo que cubre la consulta actual. Para cada pregunta, extrae entidades mencionadas, carga su vecindad desde el almacén de documentos y genera un grafo de trabajo con decenas o centenares de nodos. El LLM responde con ese contexto acotado y el grafo se descarta.
La ventaja: no hay que resolver el problema difícil de mantener un grafo global actualizado. La desventaja: cada consulta paga un coste de construcción. Para casos de uso con preguntas repetidas sobre un dominio acotado, la caché de subgrafos amortiza el coste.
Mi lectura
La vuelta del knowledge graph no es nostalgia ni moda: es una respuesta concreta a las limitaciones de los LLM puros. El modelo solo, por bueno que sea, no puede garantizar consistencia entre respuestas separadas por semanas, no puede explicar por qué llegó a una conclusión y no puede razonar con datos que no vio en entrenamiento. El grafo cubre esos huecos.
Lo que me parece notable es que esta vez la adopción parece sostenible. En 2015 los knowledge graphs fracasaban por su coste de construcción. En 2025, el mismo equipo que antes habría necesitado dos años puede poner un grafo útil en semanas, porque el LLM hace el trabajo pesado de extracción y el ontólogo humano se limita a definir el esquema mínimo.
Mi apuesta es que en los próximos doce meses los equipos de datos sin una estrategia explícita de grafo + LLM se quedarán atrás en casos que requieran razonamiento cruzado sobre fuentes heterogéneas. No por moda, sino porque los que la tengan responderán preguntas que los demás no pueden contestar. Este patrón de memoria estructurada también alimenta los servidores MCP de la comunidad más avanzados.




