Integración continua con agentes de IA: primeros patrones
Actualizado: 2026-06-20
Llevo seis meses integrando agentes de IA en los pipelines de integración continua de varios proyectos y la experiencia ha sido una curva empinada: los primeros intentos fueron decepcionantes, las primeras iteraciones generaron más ruido que valor, y solo después de afinar el contexto y los límites aparecieron los patrones que de verdad ayudan. Este post recoge lo que he aprendido sobre dónde y cómo usar agentes en CI sin convertir cada pull request en un debate con una máquina que no entiende del todo lo que revisa. Ver también: Herramientas de IA para desarrolladores: stack de 2026.
Para el contexto más amplio de agentes en producción, el análisis de agentes de IA en empresa cubre los criterios de adopción organizativa. La seguridad de agentes en pipelines se trata en seguridad de agentes LLM. El patrón de revisión de código también se conecta con CodeQL y GitHub Advanced Security.
Puntos clave
- La revisión automática de diffs funciona bien cuando el agente recibe contexto amplio: archivos completos y historial reciente de la rama, no solo las líneas cambiadas.
- Delimitar explícitamente qué revisar —lógica de control de errores, nombres, coherencia de módulo, cobertura— elimina el 80% del ruido.
- Los tests generados por agentes necesitan revisión humana antes de fusionarse; las assertions tautológicas son el problema más frecuente.
- Las sugerencias automáticas de arreglos solo son útiles para problemas que el agente puede explicar en una frase.
- Coste aproximado: 5-30 céntimos por pull request mediano; rentable cuando la revisión humana es cuello de botella.
Por qué justo ahora
La pregunta razonable es por qué hablar de esto en 2025 y no antes. La respuesta es doble. Por un lado, los modelos actuales aguantan ventanas de contexto suficientes para analizar un diff real con sus archivos vecinos, sin tener que trocear artificialmente. Por otro, las integraciones de plataforma han madurado: GitHub Actions, Gitea Actions y equivalentes ya tienen runners pensados para ejecutar pasos con modelos, y el coste por pull request ha bajado al punto donde compensa para equipos pequeños.
Hasta 2024 montar un revisor con IA exigía trabajo de plomería propio: extraer el diff, recortar para caber en la ventana, invocar el modelo, procesar la respuesta. En 2025 hay herramientas que hacen la primera capa de ese trabajo, con lo cual la barrera de entrada es mucho más baja y el foco puede estar en configurar el comportamiento.
Revisión de diffs como patrón base
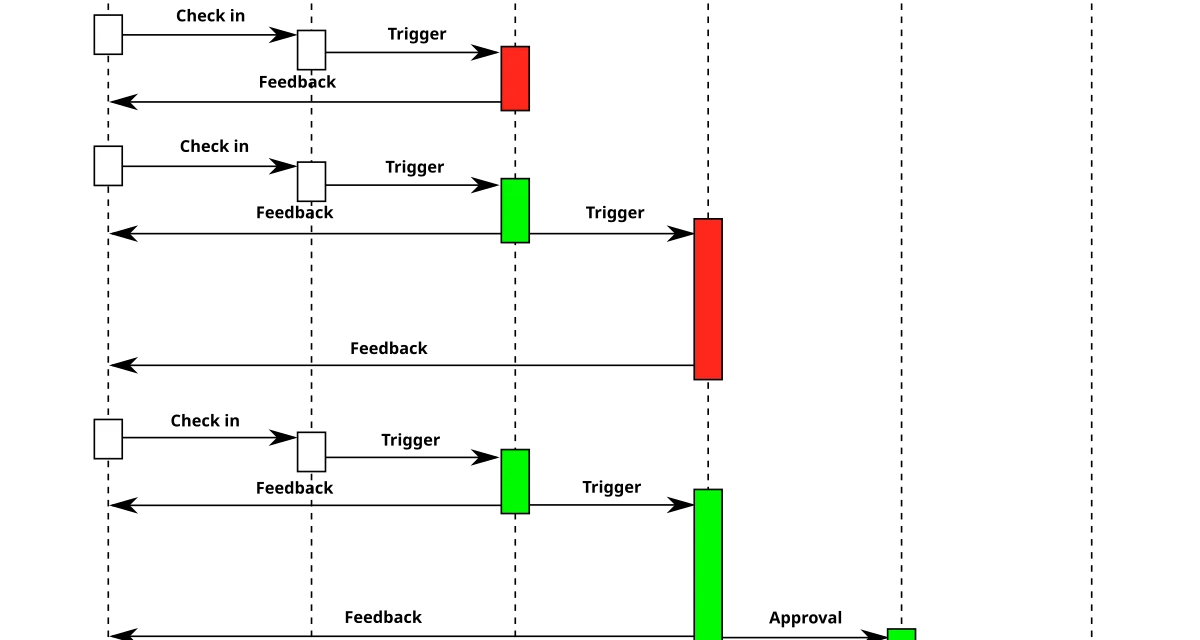
El patrón más útil que he encontrado es la revisión automática de diffs en pull requests abiertos. Un job de CI dispara un agente que lee el diff, los archivos cambiados en su totalidad y los archivos relacionados por imports. El agente publica un comentario con observaciones: posibles errores lógicos, violaciones de convenciones del proyecto, pruebas que faltan, dependencias nuevas no justificadas.
La clave para que este patrón funcione es el contexto. Un agente que solo ve las líneas cambiadas dice tonterías con frecuencia; un agente que ve los archivos completos y el historial reciente de la rama dice cosas útiles. En las pruebas, pasar de contexto de 500 líneas a contexto de 3.000 bajó la tasa de falsos positivos de cerca del 40% a menos del 10%.
El segundo factor crítico es delimitar qué revisar. Pedirle al agente que revise todo es pedirle que diga algo sobre todo, incluyendo cosas donde no sabe nada. Darle una lista explícita funciona mejor: lógica de control de errores, nombres de variables, coherencia con el patrón del módulo, tests que cubran los cambios. Fuera de esa lista, silencio. Esto elimina ruido y mantiene la credibilidad del comentario.
Generación de tests que faltan
El segundo patrón que usa mi pipeline es la generación de tests para funciones nuevas sin cobertura. Un job separado detecta funciones públicas añadidas en el diff que no tienen tests asociados, genera casos de prueba con el agente, y propone el resultado como un commit adicional en el pull request.
Este patrón es más delicado que la revisión. Los tests generados necesitan ser buenos, no solo existir, y hay que resistir la tentación de subir cobertura con pruebas que no prueban nada sustancial. Lo que ha funcionado es generar solo los casos felices y los bordes más obvios, y pedir explícitamente al humano que añada los casos de error y los casos adversos.
El segundo cuidado son los tests que parecen correctos pero pasan siempre. La IA tiene tendencia a generar assertions tautológicas: comprueba que la función devuelve lo que devuelve. Revisar los tests generados antes de fusionarlos es obligatorio; confiar ciegamente en que la cobertura sube es el camino rápido a una base de tests peor que la anterior.
Arreglos propuestos como sugerencias
El tercer patrón, menos maduro pero prometedor, es la propuesta de arreglos automáticos. Cuando el agente detecta un problema concreto, además de describirlo en texto, publica una sugerencia en el pull request que el autor puede aceptar con un clic. Este patrón es potente porque convierte el comentario abstracto en código concreto.
El límite es que solo funciona bien en problemas pequeños y locales: formato, nombres, validaciones de entrada olvidadas. Para cambios arquitecturales o decisiones de diseño, el agente no tiene contexto para proponer el arreglo correcto y acaba sugiriendo cosas peores que el problema original. Mi regla es activar sugerencias automáticas solo para problemas que el agente puede explicar en una frase; para problemas que requieren párrafo, que el autor decida.
Costes reales y límites prácticos
Un agente de calidad para revisión de un pull request mediano cuesta entre 5 y 30 céntimos por ejecución dependiendo del modelo y del tamaño del contexto. Para un proyecto con 50 pull requests a la semana, son entre 10 y 60 euros al mes. No es gratis pero tampoco es caro comparado con el tiempo de revisión humana que ahorra en los pull requests pequeños.
El límite que más frustra es la memoria entre ejecuciones. Cada invocación del agente es independiente: no recuerda decisiones previas del equipo, no aprende de las sugerencias rechazadas, no afina su criterio a las convenciones específicas del proyecto. Hay estrategias para paliarlo —incluir fragmentos del historial en el contexto, mantener un archivo de convenciones que se inyecta en cada llamada— pero ninguna es completa.
Lo que no conviene automatizar
Tras varios meses he acabado con una lista de cosas que no conviene pedirle al agente en CI:
- Revisión de cambios de seguridad: los falsos negativos son caros y el agente no tiene el contexto completo de la política de seguridad del proyecto. Para estos cambios es mejor un linter de seguridad clásico y revisión humana dedicada.
- Cambios que tocan contratos públicos de API: el agente puede detectar rupturas sintácticas pero no entiende las implicaciones semánticas de un cambio de contrato.
- Análisis de rendimiento: el agente puede leer código y especular sobre complejidad, pero no sabe medir. Para decisiones de rendimiento, hay que medir, no opinar.
Cómo configuro el pipeline
Mi configuración actual tiene tres pasos diferenciados:
- Paso rápido y barato: análisis sintáctico y de estilo con herramientas clásicas. Este paso filtra el 80% de los problemas triviales antes de que el agente los vea, lo que ahorra coste y mejora la señal.
- Agente de revisión: se ejecuta solo si el primer paso pasa y si el pull request cambia más de 20 líneas. Para cambios muy pequeños el coste no se amortiza. El agente recibe el diff, los archivos tocados enteros, el historial reciente de la rama y un archivo de convenciones del proyecto.
- Generador de tests: solo se dispara si se detectan funciones nuevas sin cobertura y si la rama no es de hotfix. Los hotfix son rápidos y el autor sabe lo que hace; bloquear con propuestas generadas añade fricción innecesaria.
Cuándo compensa
Mi criterio para decidir si un proyecto se beneficia de agentes en CI es sencillo: equipos de tres o más personas donde la revisión humana es cuello de botella, código con convenciones claras y documentadas, y presupuesto para asumir entre 20 y 100 euros al mes en coste de modelo. Para equipos más pequeños, la revisión humana sigue siendo más barata y precisa.
Para proyectos puntuales o exploratorios, los agentes en CI son ruido. El coste fijo de configurar el pipeline no se amortiza y el agente acaba comentando cosas que el autor ya sabe y ha decidido ignorar. La madurez del proyecto es un requisito que a veces se pasa por alto.
Dentro de un año el patrón será más sofisticado: agentes que recuerdan decisiones previas, que afinan criterios con las correcciones del equipo, que coordinan revisiones largas en varias pasadas. Por ahora, los patrones simples y acotados son los que funcionan. Resistir la tentación de pedirle al agente todo y concentrar su trabajo en tres o cuatro tareas donde aporta valor es la forma rápida de sacarle partido sin quemar credibilidad.



