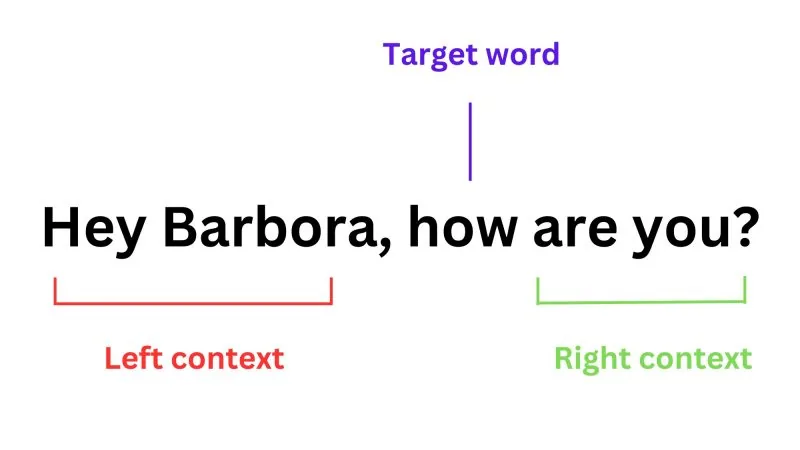
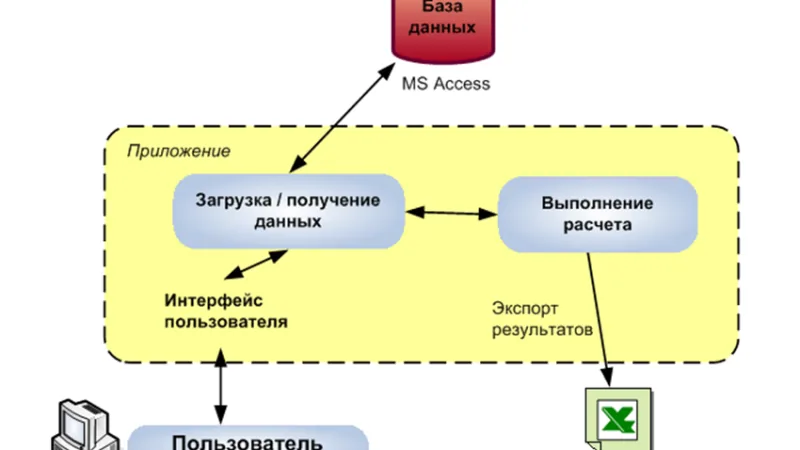
Using an LLM to judge another LLM became widespread in 2024 and remains the only scalable way to evaluate qualitative quality. The mature question is when to trust those numbers.
Opus 4.7 se lanzó como el modelo más capaz de Anthropic con énfasis en trabajo agéntico de horizonte largo. Tras dos meses de uso intensivo, estos son los cambios prácticos frente a Opus 4.6.
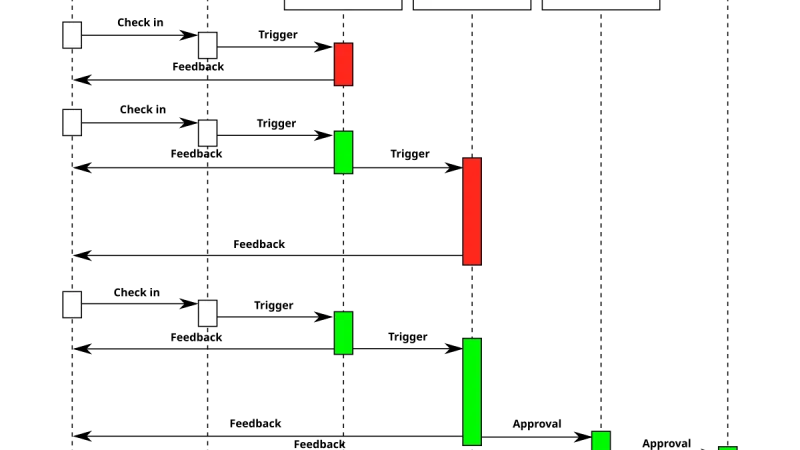
Los agentes fallan. La pregunta no es si, sino cómo y qué haces en los primeros veinte minutos. Este es el runbook que distingue un incidente contenido de una reputación dañada.
Prompt engineering ha pasado de ser una colección de trucos virales a una disciplina con patrones reproducibles, librerías dedicadas y herramientas de observabilidad.
Durante 2025 cientos de equipos pusieron agentes IA en producción real. A principios de 2026, con datos suficientes, emergen lecciones consistentes sobre qué falla, qué funciona, cuánto cuesta y qué tareas no encajan. Repaso ordenado para equipos que empiezan ahora.
Una selección de postmortems publicados entre 2025 y 2026 por equipos que operan sistemas con IA en producción revela patrones repetidos: fallos en guardrails, deriva silenciosa de modelos, dependencia oculta del proveedor y una colección de sustos que vale la pena destilar.
Hace tres años era una curiosidad académica. Hoy, planificar cargas por intensidad de carbono de la red eléctrica es una opción integrada en Kubernetes, en los servicios de contenedores de los grandes proveedores y en varios schedulers de CI. Repasamos qué cambió y qué hacer con esa capacidad.
Casi nueve meses después del lanzamiento de Computer Use, algunos equipos lo han llevado a producción para tareas reales. Dónde funciona, dónde todavía no conviene, y qué patrones están emergiendo para que un agente que maneja ratón y teclado no acabe siendo más problema que solución.
El profiling continuo ha salido del terreno experimental y se ha vuelto una herramienta habitual en sistemas con tráfico real. Repaso qué aporta eBPF frente a instrumentación clásica, qué cuesta y cuándo compensa instalarlo.
Después de años acumulando SBOMs, el cuello de botella es filtrar qué CVEs afectan de verdad. VEX aparece como la pieza que convierte el ruido en señal, y en 2025 empieza a tener adopción real en pipelines de supply chain.
Dos años después de que Zero Trust dejase de ser palabra de marketing, toca mirar cómo conecta con el SIEM del día a día. Reflexión sobre señales útiles, ruido evitable y decisiones que de verdad cambian la postura de seguridad.
Dependabot y Renovate persiguen lo mismo pero con filosofías distintas. Comparo ambos tras años usándolos en proyectos propios y de cliente, y repaso cuándo uno aprieta mejor y cuándo el otro se adapta más al flujo del equipo.
SLSA lleva año y medio en su versión 1.0 y el ecosistema ha tenido tiempo de adoptarlo. Repaso de lo que funciona, lo que sigue costando y por dónde tiene sentido empezar.
CrewAI modela agentes como un equipo con roles y tareas. Cómo se compara con LangGraph y AutoGen, y cuándo merece la pena adoptar un patrón multi-agente.
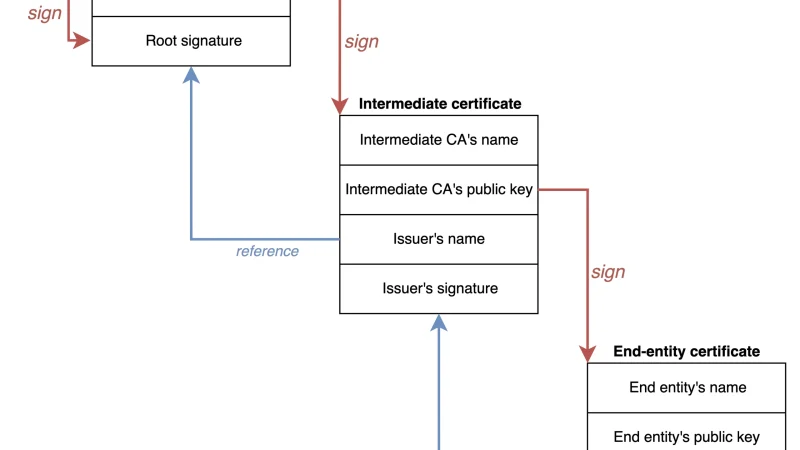
Dos años después de irrumpir, Sigstore se ha consolidado como estándar de firma para artefactos OCI. Repaso del estado real en los grandes registros y de lo que funciona en producción.
Los post-mortems blameless son fáciles de decir, difíciles de hacer bien. Técnicas concretas para extraer aprendizaje real sin que se conviertan en teatro.
Internal Developer Platform es un término con tres grandes opciones. Cuál encaja mejor según el tamaño del equipo y la cultura de plataforma de tu organización.
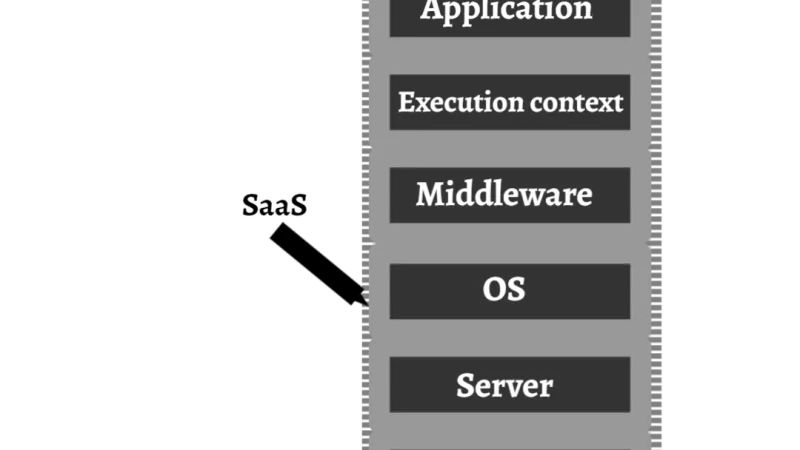
El mercado SaaS se está concentrando tras años de fragmentación. Cómo evaluar el lock-in, negociar renovaciones y construir exit strategies que funcionen de verdad.
Los OKR (Objectives and Key Results) alinean a toda la organización hacia metas ambiciosas y medibles, con revisiones trimestrales que mantienen el foco sin perder la flexibilidad.
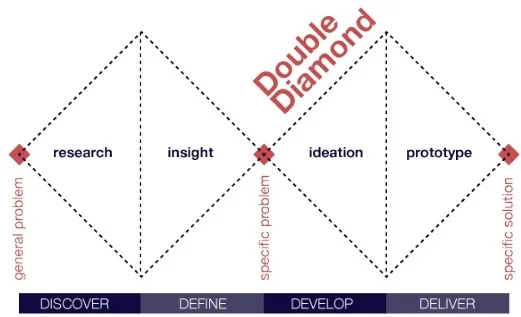
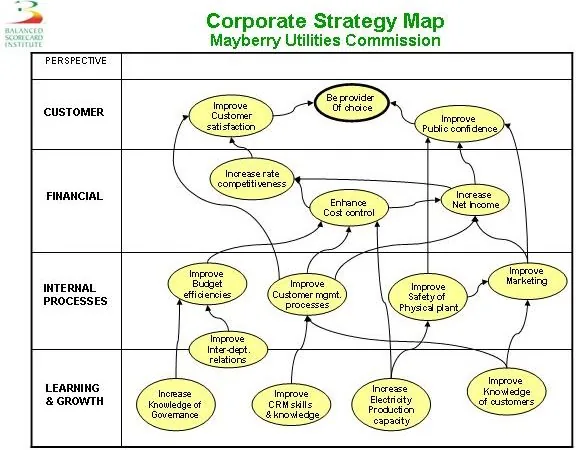
SMART, OKR, Balanced Scorecard: tres metodologías para que los objetivos dejen de ser buenas intenciones y se conviertan en compromisos medibles alineados con la estrategia.
5 min2044.5
We use first- and third-party cookies to analyze site traffic. You can accept them, reject them, or configure your choice.
Learn more
Cookie preferences
NecessaryEssential for the site to work. Always on.
AnalyticsHelp us understand how the site is used (Google Analytics).