Formulación Matemática de Entrada de Red Neuronal Artificial
Actualizado: 2026-05-03
Bajo la superficie de cualquier red neuronal existe álgebra lineal: vectores, matrices y funciones. Entender la formulación matemática de la entrada no es un ejercicio académico — es la base para depurar modelos, diagnosticar problemas de gradiente y elegir funciones de activación con criterio.
Puntos clave
- Cada entrada a una red neuronal se representa como un vector columna x de n dimensiones.
- La capa oculta aplica una transformación lineal mediante una matriz de pesos W y un vector de sesgos b, seguida de una función de activación no lineal.
- La función de activación introduce la no linealidad sin la cual la red sería equivalente a una simple regresión lineal.
- El entrenamiento ajusta los pesos W y b minimizando una función de pérdida mediante descenso por gradiente con retropropagación.
- Los gradientes que se desvanecen o explotan son el principal problema matemático en redes profundas.
La representación matemática de la entrada
Una muestra de datos de entrada se representa como un vector columna de dimensión n:
$$mathbf{x} = begin{pmatrix} x_1 \ x_2 \ vdots \ x_n end{pmatrix} in mathbb{R}^n$$
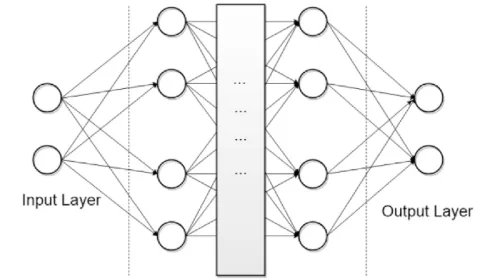
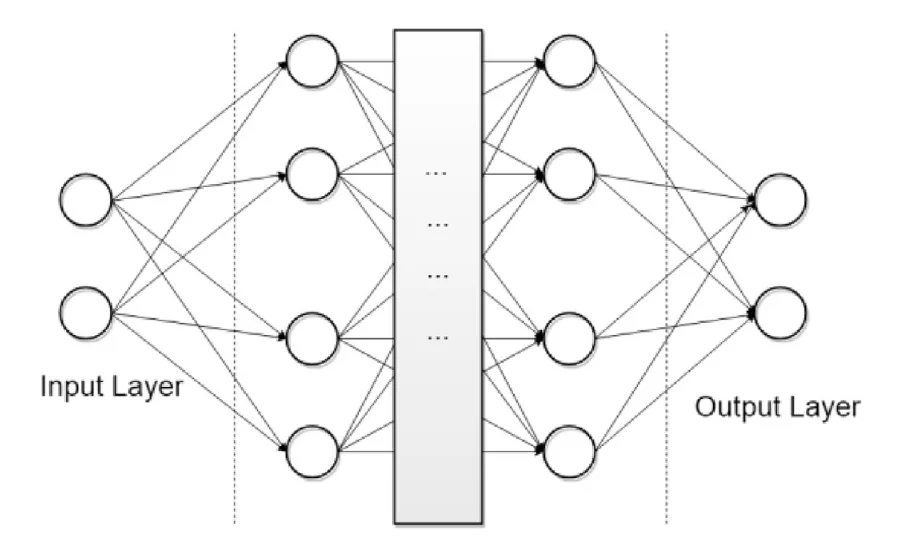
Donde cada xᵢ es una característica del dato: un píxel en una imagen, una palabra codificada en texto, un valor numérico en una tabla. Para un batch de B muestras, la entrada se organiza como una matriz X de dimensión B × n, lo que permite procesar varias muestras en paralelo mediante operaciones matriciales eficientes en GPU.
La capa oculta: transformación lineal seguida de no linealidad
Para una capa oculta con M neuronas, la operación es:
z = Wx + b
h = f(z)
Donde:
- W es la matriz de pesos de dimensión M × n. La fila j de W contiene los pesos de la neurona j.
- b es el vector de sesgos (bias) de dimensión M, que permite desplazar la activación independientemente de la entrada.
- f es la función de activación, aplicada elemento a elemento.
El sesgo b es crítico: sin él, si todas las entradas son cero, la salida también sería cero independientemente de los pesos, lo que limita la capacidad expresiva de la red.
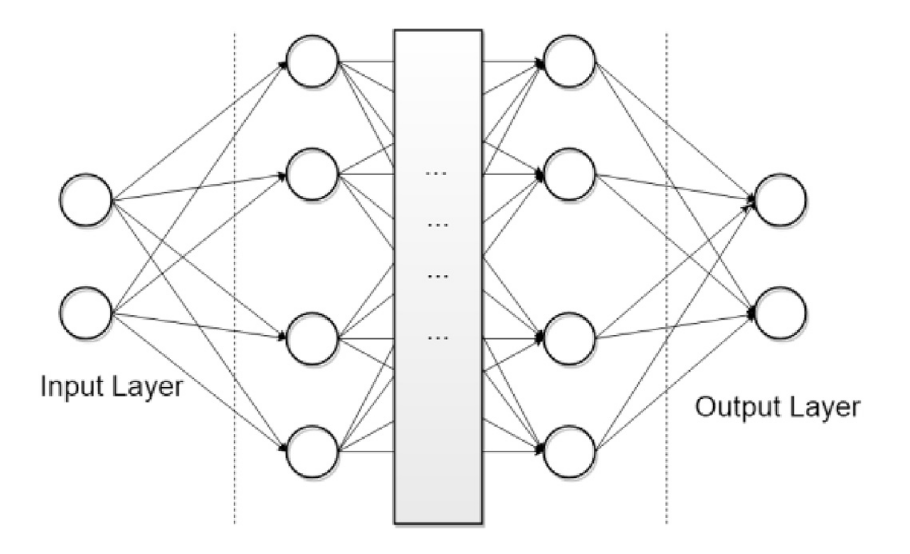
Funciones de activación: por qué importan
Sin una función de activación no lineal, la composición de capas lineales sigue siendo lineal. Una red de 100 capas sin activaciones equivale matemáticamente a una sola capa lineal. Las funciones de activación más usadas son:
- Sigmoide: f(z) = 1 / (1 + e⁻ᶻ) — salida en (0,1), útil en la capa de salida para clasificación binaria, pero propensa a gradientes que se desvanecen en redes profundas.
- ReLU (Rectified Linear Unit): f(z) = max(0, z) — computacionalmente eficiente y que mitiga el problema del gradiente desvanecido; es la función por defecto en capas ocultas de redes profundas.
- Tanh: f(z) = (eᶻ – e⁻ᶻ) / (eᶻ + e⁻ᶻ) — salida centrada en 0, con mejor comportamiento que sigmoide en capas ocultas.
- Softmax: usada en la capa de salida para clasificación multiclase — convierte un vector de valores arbitrarios en una distribución de probabilidad. Ver función Softmax.
- Función lineal: f(z) = z — sin transformación, usada en la capa de salida para regresión. Ver función lineal como función de activación.

El algoritmo de retropropagación
El entrenamiento consiste en ajustar W y b para minimizar una función de pérdida L (por ejemplo, entropía cruzada para clasificación, MSE para regresión). El algoritmo de retropropagación (backpropagation) calcula el gradiente de L respecto a cada parámetro usando la regla de la cadena:
$$frac{partial L}{partial mathbf{W}^{(l)}} = frac{partial L}{partial mathbf{h}^{(l)}} cdot frac{partial mathbf{h}^{(l)}}{partial mathbf{z}^{(l)}} cdot frac{partial mathbf{z}^{(l)}}{partial mathbf{W}^{(l)}}$$
El proceso, paso a paso:
- Propagación hacia delante: calcular la predicción de la red.
- Cálculo de la pérdida: comparar predicción con etiqueta real.
- Propagación hacia atrás: calcular los gradientes capa por capa desde la salida hasta la entrada.
- Actualización de parámetros: con descenso por gradiente, W ← W – η · ∂L/∂W, donde η es la tasa de aprendizaje.
El problema del gradiente desvanecido ocurre cuando los gradientes se hacen exponencialmente pequeños al propagarse hacia atrás por muchas capas — principalmente con sigmoide y tanh. ReLU y sus variantes (Leaky ReLU, ELU) mitigan este problema. El problema contrario — gradiente explosivo — se trata con gradient clipping.
Para más contexto arquitectural, ver redes neuronales y deep learning. Si te interesa la clasificación multiclase desde la perspectiva de la capa de salida, ver función Softmax. El uso práctico de estos modelos en benchmarks rápidos se cubre en LazyPredict en Python.
Conclusión
La formulación matemática de una red neuronal es elegante en su estructura: álgebra lineal en cada capa, no linealidad en cada activación, y optimización iterativa en el entrenamiento. Comprender estos fundamentos no es opcional para quien quiera ir más allá de usar librerías como cajas negras. El diagnóstico de un modelo que no converge, la elección de la función de activación correcta o el diseño de la arquitectura adecuada dependen directamente de entender la matemática que hay debajo.